发表于: 2021-05-01 22:59:35
1 2110
学习spring Cloud Sleuth 服务链路追踪
spring Cloud-Security
遇到的问题:
3.私自配置了本地仓库文件,导致Config Server不知道用那一个,报错 找不到文件 解决办法:删除本地仓库文件
解决Spring Cloud Config的报错

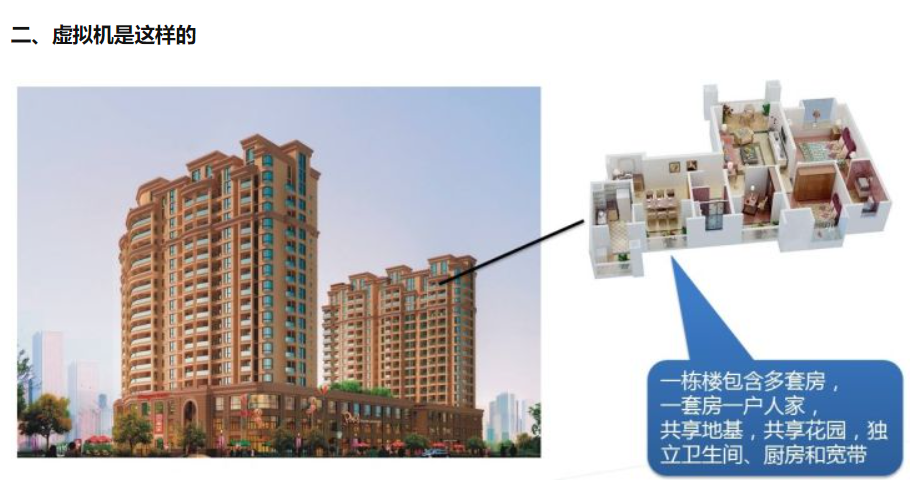
看到一个好玩的 物理机 和 虚拟机 + Docker容器的区别


微服务的定义:
1.按业务划分为一个独立运行的程序,即服务单元。 一般来说,将访问量大的服务分离出去,比如电商服务中的订单服务等等
2.服务之间通过HTTP协议相互通信。 一般通过RestTemplate,按照Restful风格进行通信。辅助通信有 RabbitMQ, 和Dobbo明显的不同,就是Dobbo采用RPC进行通信
3.自动化部署。 这个和Jenkins+Docker有关,是为了解决微服务中 多个服务部署问题,毕竟不像单体架构一样,只用部署一个war包就行了。
4.可使用不同的编程语言。 这个暂时没发现
5.可以使用不同的存储技术。 这个就是数据库独立了,对于经常需要读写采用MongDB或者Redis,他们的读写速度很快。每个服务所使用的数据存储技术根据业务来选择。
6.服务集中化管理。 比如Eureka 通过Eureka来注册服务和发现服务
7.微服务是一个分布式系统。
分布式系统比单体架构更加的复杂,体现在服务的独立性,服务相互调用的可靠性,还有分布式事务,全局锁,全局id,以及数据的一致性,单体架构不用考虑这些复杂性。 由于通信依赖HTTP请求,网络不好,会对分布式带来很大的影响。且在分布式系统中,各个服务互相依赖,一旦一个服务出现问题或者网络延迟,在高并发的情况下,很短的时间内,线程资源会被耗尽,导致该服务不可用。由于服务间相互依赖,可能会导致整个系统都崩溃,这就是“雪崩效应”。于是引入了熔断机制。
开发流程:
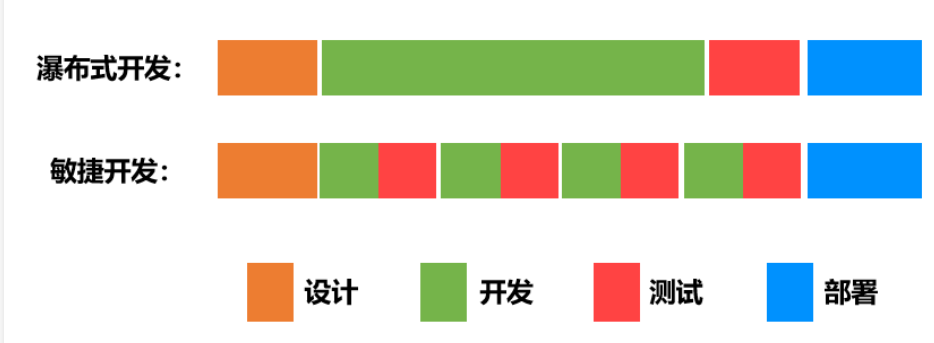
带来的好处,风险大小降低,大幅提升了软件开发的效率和版本更新的速度
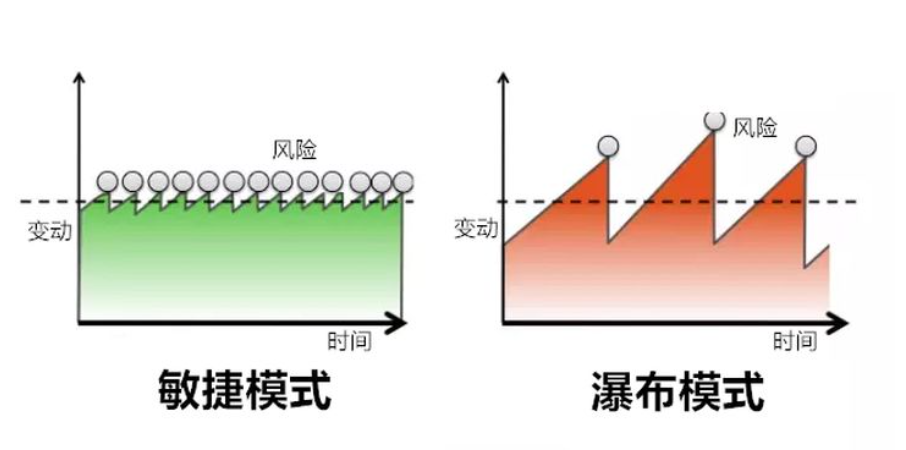
可是OP(部署还是铁板一块), 于是新加入了一种模式:
DevOps(Development Operations)
意思就会变成下面这样:
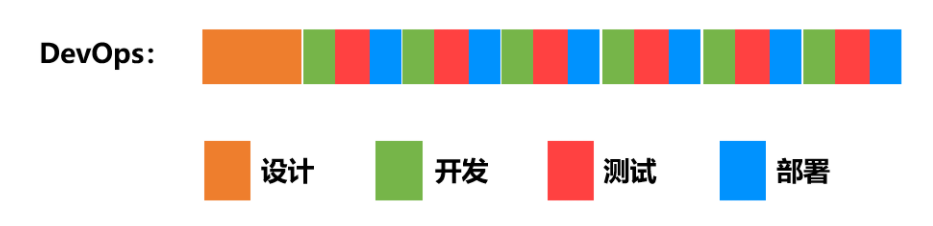
=======
DevOps其实很早之前就提出来了,但是一直不火。因为当时Docker和Jenkins还没出现,微服务也不常见,可以看到技术和开发流程是相辅相成的。
想到微服务这个 不仅仅是spring cloud和Dobbo等等,而是由微服务这个概念带来一整套的改变。spring cloud+Docker+Jenkins+DevOps等等
微服务十分契合DevOps,从早期一个人搞所有步骤,到现在变成每个都只负责了一个微服务下面的一小个设计。给我的感觉开发流程是逐渐在向 流水线靠近(想到对工业革命意义重大的流水线生产一样)。
用轻量的消息代理将分布式的服务连接起来,消息总线可以为微服务做监控,也可以实现程序之间相互通信。
因为微服务太多了,一个一个更改配置太麻烦了。


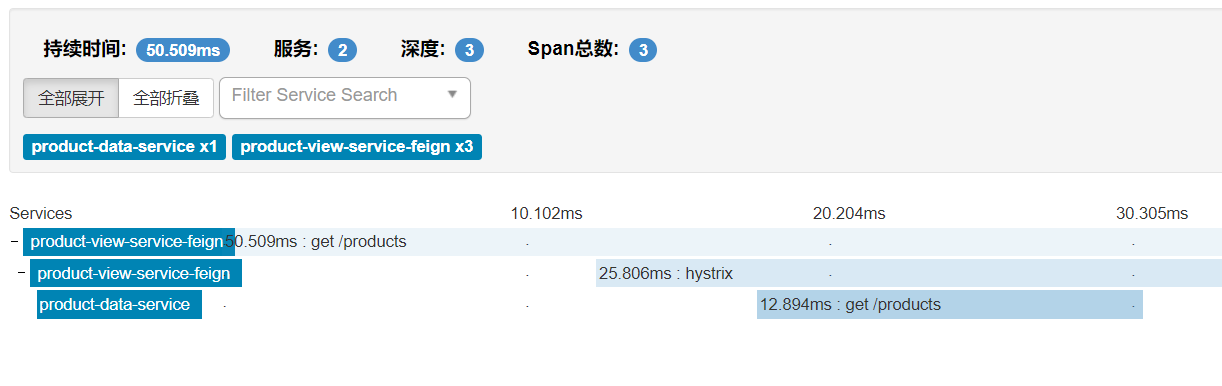
spring Cloud Sleuth 服务链路追踪:
spring Cloud Sleuth是什么?
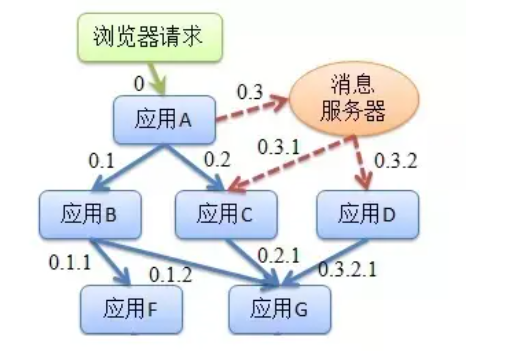
是一个分布式链路追踪组件,封装了Dapper,Zipkin和Kibana等组件,通过它可以知道服务之间相互依赖的关系,并实时观察链路的调用情况。
单纯的理解链路追踪,就是指一次任务的开始到结束,期间调用的所有系统及耗时(时间跨度)都可以完整记录下来。
Spring Cloud Sleuth 提供了以下功能:
链路追踪:通过 Sleuth 可以很清楚的看出一个请求都经过了那些服务,可以很方便的理清服务间的调用关系等。
性能分析:通过 Sleuth 可以很方便的看出每个采样请求的耗时,分析哪些服务调用比较耗时,当服务调用的耗时随着请求量的增大而增大时, 可以对服务的扩容提供一定的提醒。
数据分析,优化链路:对于频繁调用一个服务,或并行调用等,可以针对业务做一些优化措施。
可视化错误:对于程序未捕获的异常,可以配合 Zipkin 查看。
为什么要使用spring Cloud Sleuth?
因为微服务架构是一个分布式架构,微服务系统按照业务划分服务单元,一个微服务系统往往有很多个服务单元。然后一个请求可能会调用多个服务单元,这时候,一旦出错,找出错误是一件很复杂的事情,那么这个时候就需要spring Cloud Sleuth 为我们来找出一个请求的参与过程。
简单实现:
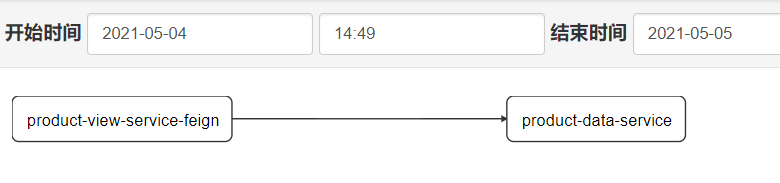
1.对 product-data-service和 product-view-service-feign 两个 pom.xml 里都增加 zipkin依赖
2.两个的配置文件都加上
3.在启动类里配置 Sampler 抽样策略: ALWAYS_SAMPLE 表示持续抽样
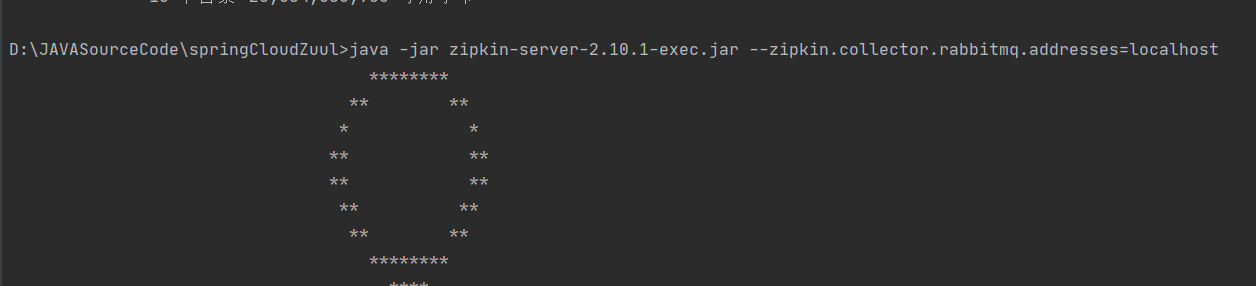
4.启动 zipkin-server-2.10.1-exec.jar
备注:
java -jar zipkin-server-2.10.1-exec.jar --zipkin.collector.rabbitmq.addresses=localhost




评论