1.什么是负载均衡,为什么要做负载均衡?
通俗的讲就是客户端发送过来的请求,并不是直接请求目标服务器,而是有一个中转的代理服务器进行分发的。代理服务器会根据当前的服务器的使用情况和分发的规则,将请求转送到对应的负载均衡服务器上
1.一台服务器挂掉,可以转发去另一台服务器,不会影响项目的正常运行。2.减少高并发的压力
2.为什么要使用memcache?memcache有什么作用?
因为网站的高并发读写和对海量数据的处理需求,传统的关系型数据库开始出现瓶颈。
1.对关系型数据库进行高并发读写(每秒上万次的访问),数据库系统是无法承受的。
2.对关系型数据库,如果在一个有上亿条数据的数据表中查找某条记录,效率将非常低。
这时候就需要使用到memcache,目的就是解决以上这两个瓶颈的
3.后台只允许有列表页和详情页,列表页分为搜索区和列表区和操作区,原因是什么?有没有其他设计方式,相比之下各自的好处是什么?
这个还没有做过,猜测一下原因应该是,为了更好的查找到数据吧。后台好像一般都会使用分页。列表页可以让管理人员快速找到自己需要的功能,不用一个个点开去查看。详情页面展示了一个类目下的所有操作,让操作人员不需要切换页面就可以完成操作。
4.什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
计算机集群(英語:computer cluster)是一组松散或紧密连接在一起工作的计算机。 由于这些计算机协同工作,在许多方面它们可以被视为单个系统。 与网格计算机不同,计算机集群将每个节点设置为执行相同的任务,由软件控制和调度。
即多台服务器执行同一个任务,当其中某个服务器宕机之后其他的服务器可以支持业务继续进行。比如后端的负载均衡。
集群使用场景:后端负载均衡、缓存集群、数据库集群
实现方案:
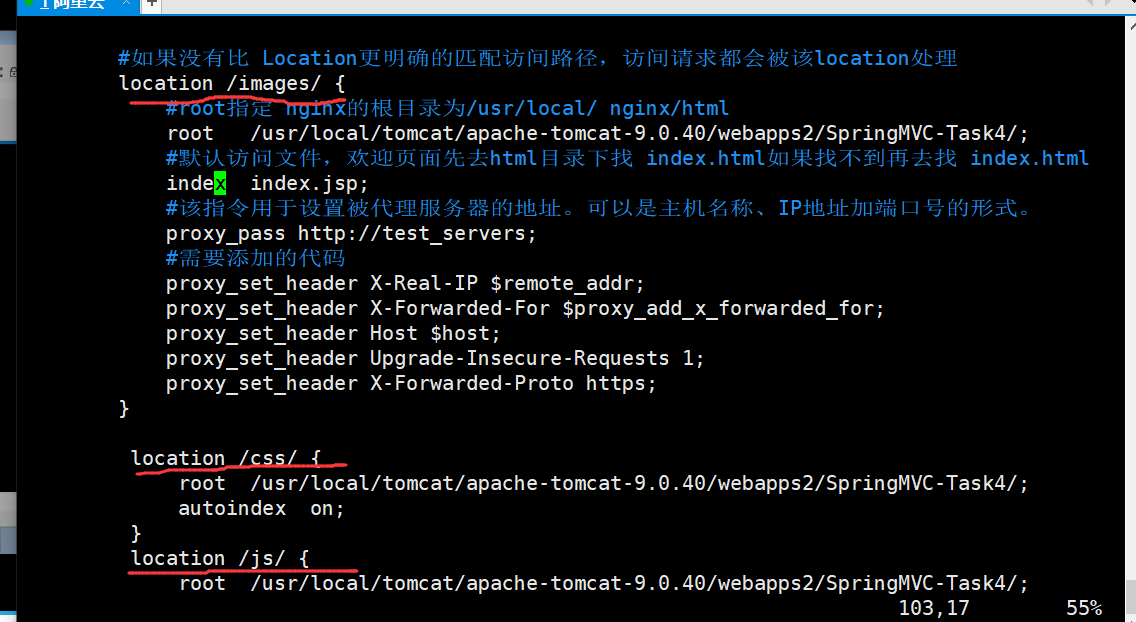
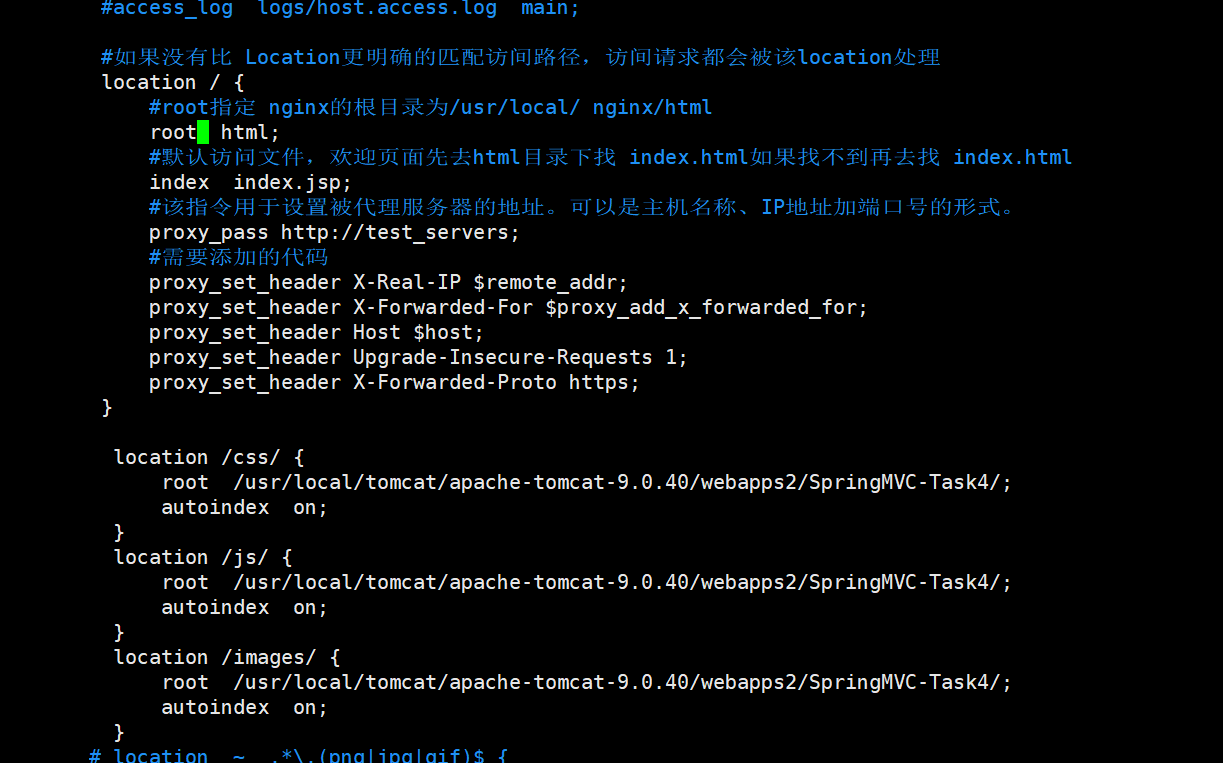
通过代理(nginx)的 upstream
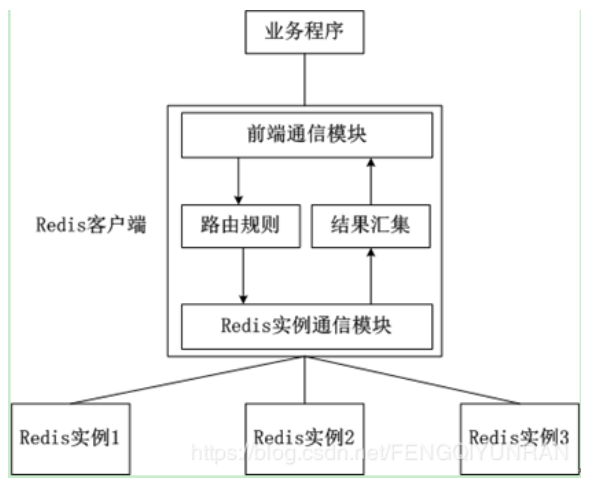
客户端分片:客户端分片是把分片的逻辑放在Redis客户端实现,通过Redis客户端预先定义好的路由规则,把对Key的访问转发到不同的Redis实例中,最后把返回结果汇集。这种方案的模式如图所示
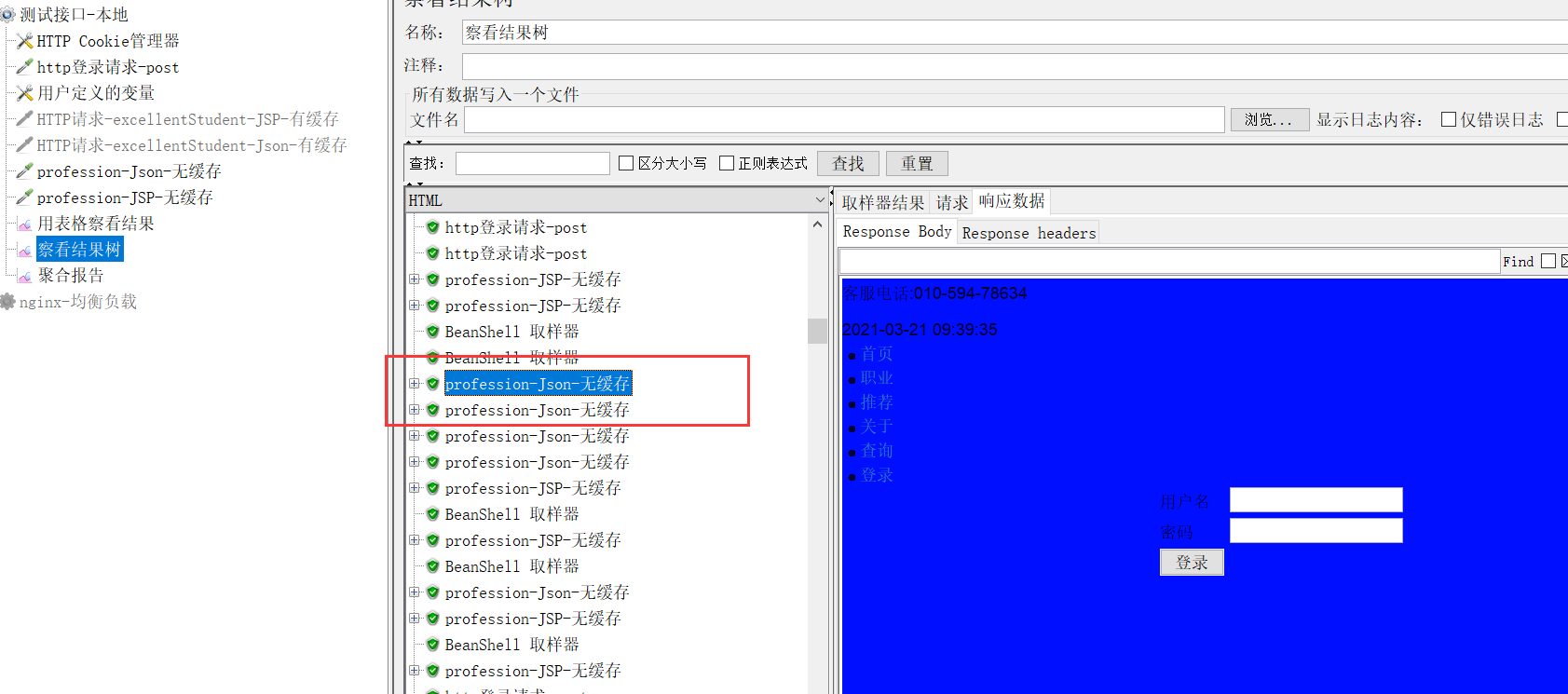
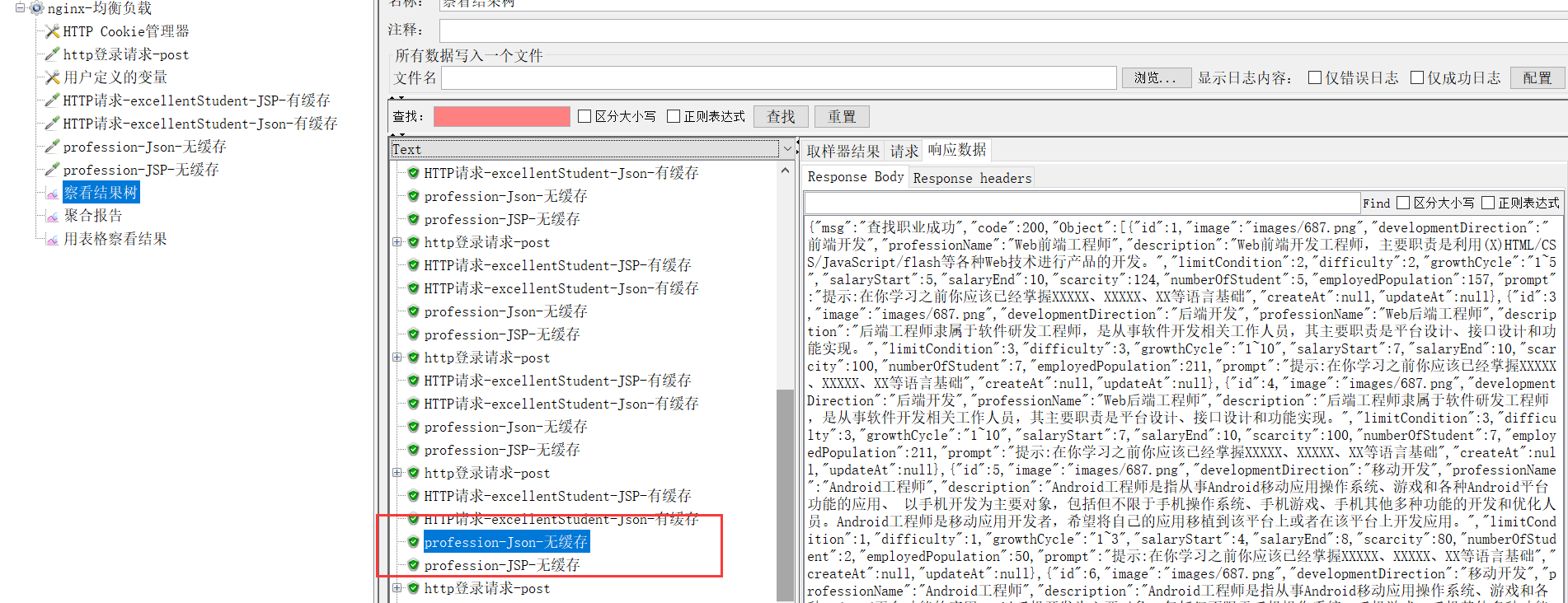
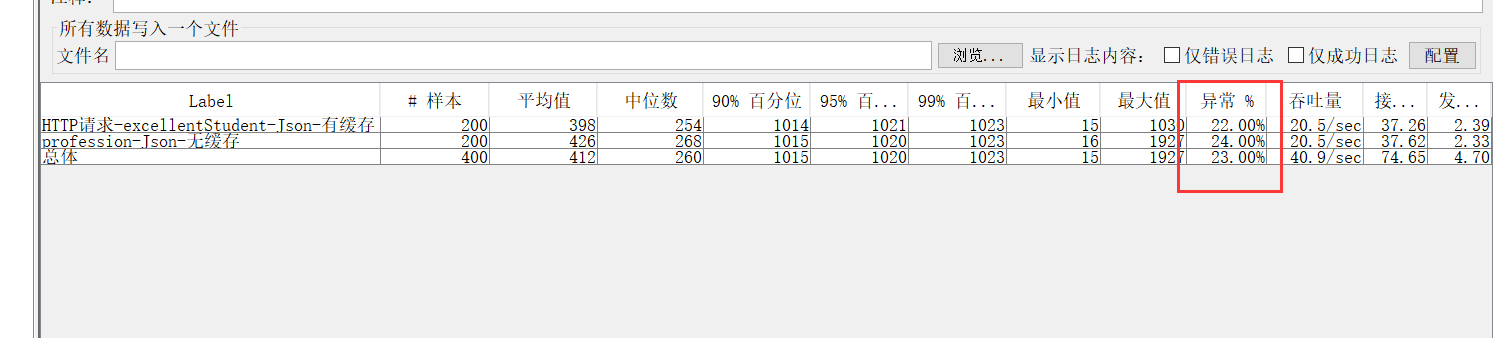
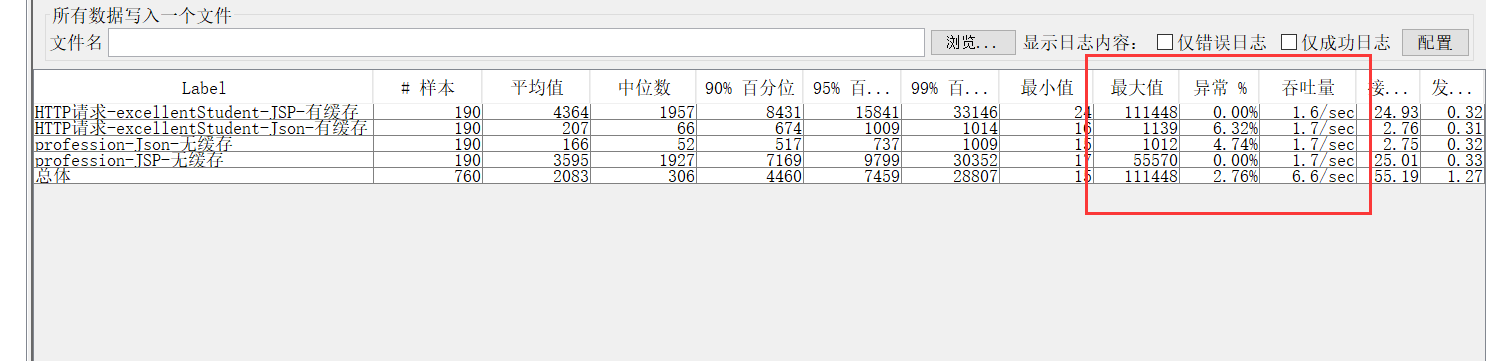
5.什么是压测,为什么要进行压力测试?JMETER工具的使用
压力测试是在强负载(大数据量、大量并发用户等)下的测试,查看应用系统在峰值使用情况下操作行为,从而有效地发现系统的某项功能隐患、系统是否具有良好的容错能力和可恢复能力。
6.Memcache和Redis可否做集群?什么样的情况下应该做集群?
都可以做集群。
后端要做负载均衡的时候缓存也要做负载均衡。
比如我们使用 session 做用户登录认证,这和时候就需要使用 redis 来缓存 session 再各个后台服务器之间共享 session。
7.什么是脏数据,缓存中是否可能产生脏数据,如果出现脏数据该怎么处理?
当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
缓存中可能产生脏数据。
对缓存进行双删,跟新数据库之前删除缓存,更新完之后间隔几百毫秒再删一次。
8.插入,更新和查询数据的时候,读写缓存和DB的顺序应该是怎么样的?
插入:插入DB
更新:更新DB,先判断缓存值是否为空(为空直接将DB的数据添加到缓存),不然检查DB和缓存的值是否相等,相等不进行操作,不相等进行更新的操作
查询:先查询缓存值,判断是否为空,不为空,直接返回缓存的值。为空,去DB查询值添加到缓存当中。
9.JVM缓存和Memcache这种缓存的区别在哪里?是否可以不使用Memcache,只用虚拟机内存做缓存?
JVM缓存: 在系统中,有些数据量不大、不常变化,但是访问十分频繁,例如省、市、区数据。针对这种场景,可以将数据加载到应用的内存中,以提升系统的访问效率,减少无谓的数据库和网路的访问。
内部缓存的限制就是存放的数据总量不能超出内存容量,毕竟还是在 JVM 里的。
比如 java 的 map、list
功能强大的内部缓存 - Guava Cache / Caffeine
本地缓存的优点:
直接使用内存,速度快,通常存取的性能可以达到每秒千万级 可以直接使用 Java 对象存取 本
地缓存的缺点: 数据保存在当前实例中,无法共享 重启应用会丢失
最著名的外部缓存 - Redis / Memcached
Redis有很多优点: 很容易做数据分片、分布式,可以做到很大的容量 使用基数比较大,库比较成熟
同时也有一些缺点: Java 对象需要序列化才能保存 如果服务器重启,再不做持久化的情况下会丢失数据,即使有持久化也容易出现各种各样的问题
10.缓存应该在Service里,还是应该存放在Controller里,为什么?
controller 缓存适合长时间不更新、变量少的数据。
service 适合缓存经常更新的数据。
11.什么叫穿透DB?什么情况下会发生,穿透DB后会发生什么事情?
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。如果key对应的value是一定不存在的,并且对该key并发请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
所以很容易被别人恶意大量访问数据库,造成服务器的压力很大,可能会直接崩溃。
解决方法:
参数校验,缓存null,布隆过滤
12.什么叫命中率?正常来讲,命中率应该控制在多少?
终端用户访问加速节点时,如果该节点有缓存住了要被访问的数据时就叫做命中,如果没有的话需要回原服务器取,就是没有命中。取数据的过程与用户访问是同步进行的,所以即使是重新取的新数据,用户也不会感觉到有延时。 命中率=命中数/(命中数+没有命中数), 缓存命中率是判断加速效果好坏的重要因素之一。
13.什么样的数据适合存在缓存中?缓存的淘汰算法有哪些?
缓存(最多使用),数据查询、短连接、新闻内容、商品内容, 应用排行榜等等;
noeviction:返回错误,不会删除任何键值
allkeys-lru:使用LRU算法删除最近最少使用的键值
volatile-lru:使用LRU算法从设置了过期时间的键集合中删除最近最少使用的键值
allkeys-random:从所有key随机删除
volatile-random:从设置了过期时间的键的集合中随机删除
volatile-ttl:从设置了过期时间的键中删除剩余时间最短的键
volatile-lfu:从配置了过期时间的键中删除使用频率最少的键
allkeys-lfu:从所有键中删除使用频率最少的键
14.什么叫一致性哈希,通常用来解决什么问题?
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对K/n 个关键字重新映射,其中 K是关键字的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
应用场景:缓存集群的时候常见的方式是对一个 key 进行hash处理,得出它应该存到哪台缓存服务器。那么当我们需要扩容的时候就需要重新多所有的数据进行再次 hash 后分配服务器。一致性哈希就是为了解决这个问题,让我们扩容的时候不会影响到其他服务器数据的存储路径,同时去掉缓存服务器的时候会自动分配到附近的服务器上。
15.缓存的失效策略有哪几种,分别适合什么场景?
FIFO:使用队列实现,一头放新数据,另一头淘汰数据。
适合用于数据的缓冲。
LRU:在队列的基础上,队列中被命中的数据更新到新增数据的一头,最后队尾的被淘汰
适用于内存管理、页面置换。
LFU:按照数据的访问次数排序,最少访问的被淘汰
16.Memcache和Redis的区别是什么?
1、Memcached:内存型数据库,无持久化功能(无法保存到硬盘上),掉电即失,可靠性差,用于动态系统中减轻数据库负载,提升性能;做缓存,适合多读少写,大数据量的情况(如人人网大量查询用户信息、好友信息、文章信息等)。
2、Redis:内存型数据库,有持久化功能(可以保存到硬盘上),具备分布式特性,可靠性高,适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统(如新浪微博的计数和微博发布部分系统,对数据安全性、读写要求都很高)。
17.怎么预估自己系统可承载的日活数?
压力测试,测到不宕机且 90% line 在可接受范围内的最大值就是网站的可承载日活。
18.什么是JMeter?Jmeter是否可以在多台机器上分布式部署?为什么要分布式部署?
测试工具,可以分布式部署。单台计算机的性能不够测试服务器,需要集群一起测试。
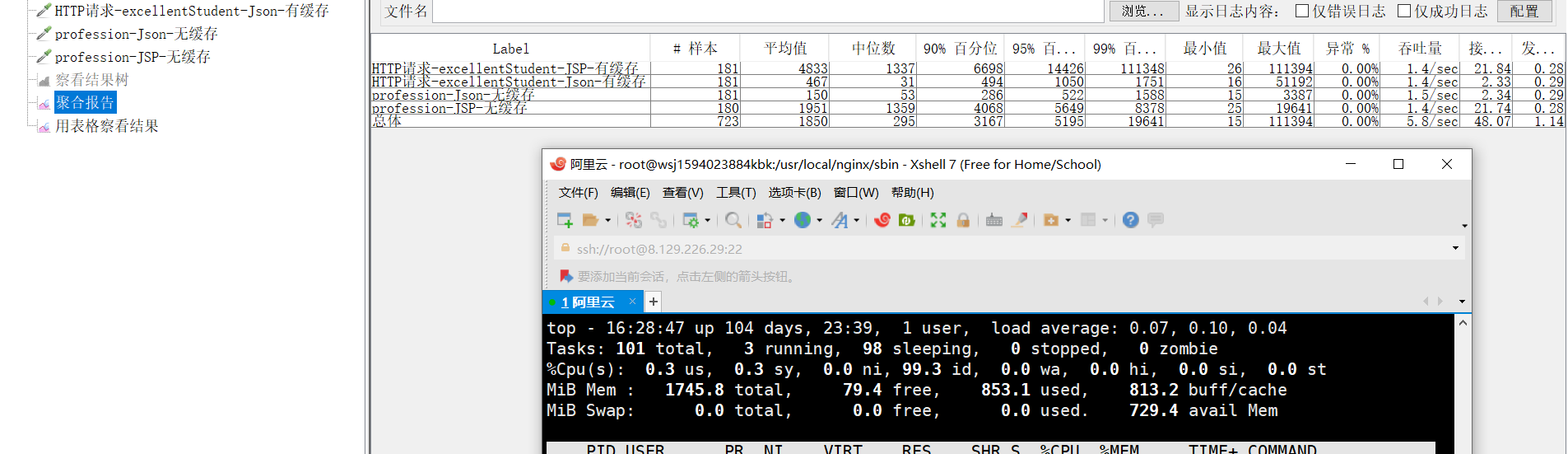
19.什么是TPS,什么是每秒并发数,什么是90%Line?分别应该到达多少算符合系统上线的要求?
测试性能时,我们更常用“1秒钟”来作为切片时间段。一秒钟完成多少个事务请求,这个数据就是我们耳熟能详的“每秒事务数”。这个指标翻译成英文就是TPS - Transaction Per Seconds。(也有用QPS - Query Per Seconds来统计的,其差异暂时不做讨论了)
每秒事务数,就是衡量服务器性能的最重要也是最直观指标。
并发数指的是一个时间段内的事务完成数。这个切片“时间段”常取1秒钟或1分钟这样的整数来做换算。假设一个厨师平均2分钟做完一道菜,那么8个厨师2分钟完成8道菜,换算一下就是4道/分钟。如果以分钟为单位进行统计,那么这个数字就是最终结果。
90%响应时间(90%Line)一组数由小到大进行排列,找到他的第90%个数(假如是12),那么这个数组中有90%的数将小于等于12 。
用在性能测试的响应时间,也就是90%请求响应时间不会超过12 秒。












评论