今天完成的事情:
在service层整合memcached
使用spring AOP 整合 memcached
memcached 缓存更新的机制
明天计划的事情:
spring 整合 Redis
压测
遇到的问题:
以下
收获:
在service层整合memcached:
public static final Logger log = LoggerFactory.getLogger(MemcachedInterceptor.class);
@Autowired
MemCachedClient memCachedClient;
@Autowired
ProfessionMapper professionMapper;
@Override
public List<Profession> selectAll() throws Exception{
List<Profession> professionList = (List<Profession>) memCachedClient.get("professionList");
try {
if (professionList !=null){
log.info("\n"+"从缓存中查询所有");
}else {
log.info("\n"+"从数据库中查询所有");
professionList = professionMapper.selectAll();
boolean list = memCachedClient.set("professionList", professionList);
log.info("\n"+"新增所有数据缓存:"+list);
}
}catch (Throwable t){
t.printStackTrace();
}
return professionList;
}
运行报错,com.kbk.model.Profession java.io.NotSerializableException。。。
序列化的问题,应该是存入memcached中,需要将数据序列化才能存入。。
了解一些什么是序列化?为什么要序列化?
序列化是用来通信的,服务端把数据序列化,发送到客户端,客户端把接收到的数据反序列化后对数据进行操作,完成后再序列化发送到服务端,服务端再反序列化数据后对数据进行操作。说白了,数据需要序列化以后才能在服务端和客户端之间传输(Java内存到memcached服务器)。这个服务端和客户端的概念是广义的,可以在网络上,也可以在同一台机器的不同进程中,甚至在同一个进程中进行通信。在传统编程中,对象是通过调用栈间接的与客户端交互,但在面向服务的编程中,客户端永远都不会直接调用实例。
简单来说序列化就是一种用来处理对象流的机制(I/O流,之前学过的,传输图片),所谓对象流也就是将对象的内容进行流化,流的概念这里不用多说(就是I/O),我们可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间(注:要想将对象传输于网络必须进行流化)!在对对象流进行读写操作时会引发一些问题,而序列化机制正是用来解决这些问题的!
参考网址:
2.https://blog.csdn.net/qq_34062105/article/details/82590215
序列化了解就到此位置了
===========
===========
直接在实体类添加
运行成功:
==============
==============
为什么要使用AOP整合memcached?
1.直接对Service层代码进行修改,就违背了“开放-封闭”原则,也会导致缓存系统的操作代码散落到Service层的各处,不方便代码的管理和维护。所以,需要使用Spring AOP---非入侵式的来创建、管理这些缓存操作代码
使用spring AOP 整合 memcached
@Aspect
@Component
public class MemcachedInterceptor {
public static final Logger log = LoggerFactory.getLogger(MemcachedInterceptor.class);
//将缓存客户端工具类 MemcachedCache 织入进来
@Autowired
private MemCachedClient memCachedClient;
/**
* 定义pointcunt
*/
@Pointcut("execution(* com.kbk.service.Impl.ProfessionServiceImpl(..))")
public void selectAll() {
}
/**
* 环绕装备 用于拦截查询 如果缓存中有数据,直接从缓存中读取;否则从数据库读取并将结果放入缓存
*
* @param call
* @return
*/
@Around("selectAll()")
public Profession selectAllAround(ProceedingJoinPoint call) {
Profession profession = null;
profession = (Profession) memCachedClient.get("professionList");
System.out.println("测试运行");
if (profession != null) {
profession = (Profession) memCachedClient.get("professionList");
log.debug("从缓存中读取!professionList"+profession);
} else {
try {
profession = (Profession) call.proceed();
if (profession != null) {
memCachedClient.set("professionList", profession);
log.debug("缓存装备被执行:professionList"+profession);
}
} catch (Throwable e) {
e.printStackTrace();
}
}
return profession;
}
}
运行报错:org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'memcachedController' defined in file [D:\JAVASourceCode\SpringMVC-Task4\target\SpringMVC-Task4\WEB-INF\classes\com\kbk\controller\MemcachedController.class]: Initialization of bean failed; nested exception is java.lang.IllegalArgumentException: warning no match for this type name: com.kbk.service.Impl [Xlint:invalidAbsoluteTypeName]
这个异常出现的原因一般是:为注入bean失败异常
1.对应的bean没有添加注解
2.对应bean添加注解错误,例如将spring的@Service错选成dubbo的包
3.选择错误的自动注入办法。
=========
=========
修改成
将代码修改成
@Aspect
@Component
public class MemcachedInterceptor {
public static final Logger log = LoggerFactory.getLogger(MemcachedInterceptor.class);
//将缓存客户端工具类 MemcachedCache 织入进来
@Autowired
private MemCachedClient memCachedClient;
@Autowired
ProfessionMapper professionMapper;
/**
* 定义pointcunt
*/
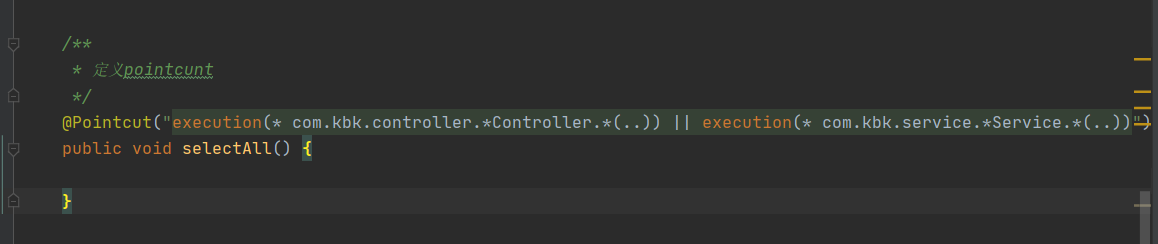
@Pointcut("execution(* com.kbk.controller.*Controller.*(..)) || execution(* com.kbk.service.*Service.*(..))")
public void selectAll() {
}
/**
* 环绕装备 用于拦截查询 如果缓存中有数据,直接从缓存中读取;否则从数据库读取并将结果放入缓存
*
* @param
* @return
*/
@Around("selectAll()")
public List<Profession> selectAllAround() throws Exception {
List<Profession> profession = (List<Profession>) memCachedClient.get("professionList");
try {
if (profession != null) {
profession = (List<Profession>) memCachedClient.get("professionList");
log.debug("从缓存中读取!professionList"+profession);
} else {
log.info("\n"+"从数据库中查询所有");
profession = professionMapper.selectAll();
boolean list = memCachedClient.set("professionList", profession);
log.info("\n"+"新增所有数据缓存:"+list);
}
}catch (Throwable t){
t.printStackTrace();
}
return profession;
}
}
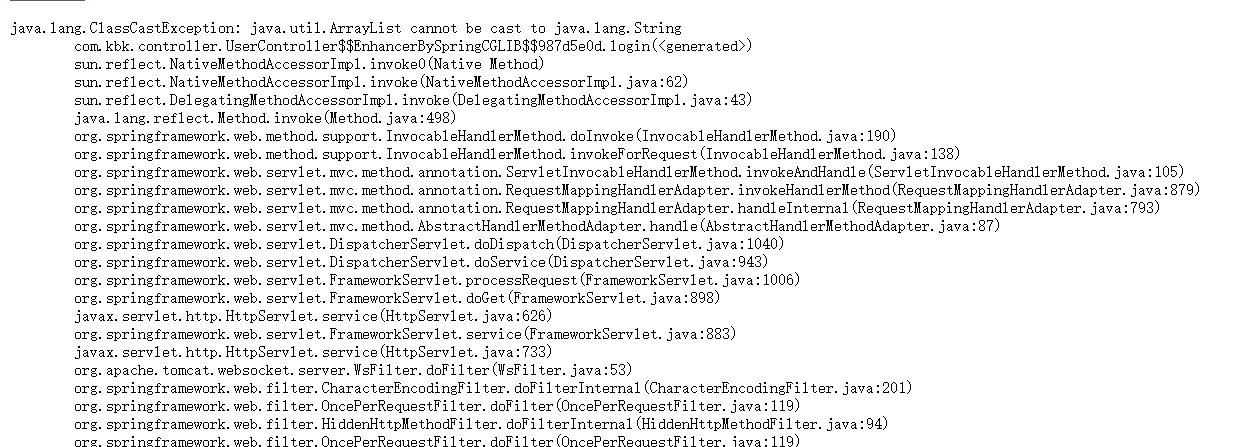
报错:java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.lang.String
先不折腾这个了
===========
===========
memcached 缓存更新的机制
看到好些人在写更新缓存数据代码时,先删除缓存,然后再更新数据库,而后续的操作会把数据再装载的缓存中。然而,这个是逻辑是错误的。试想,两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
参考网址:https://coolshell.cn/articles/17416.html
为什么要先删除缓存,更新数据库之后,查询获取新的数据,直接使用memCachedClient.set方法不就行了吗(set方法,如果key值已存在则直接覆盖重写。)





评论