发表于: 2021-03-11 22:35:10
2 759
今天完成的事情:(一定要写非常细致的内容,比如说学会了盒子模型,了解了Margin)
1,核对需求
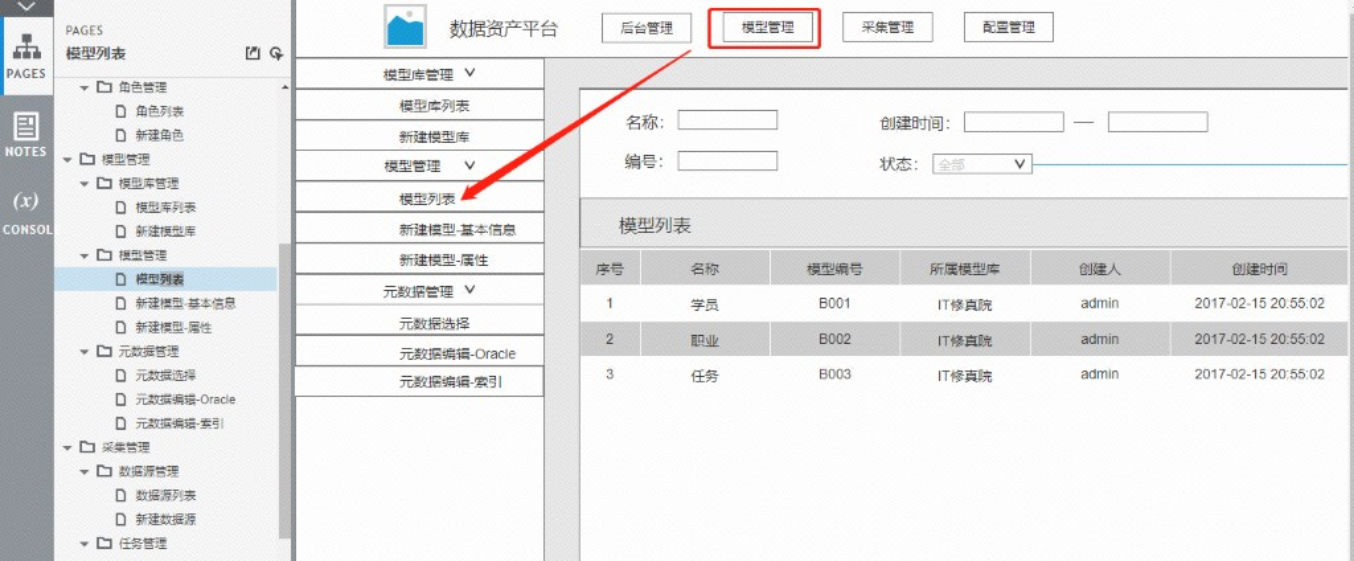
一期原型图中的模型管理 客户说模型管理的命名会让使用者产生歧义,是模型库里的模型吧,应该和元模型没什么关系
这里我也想知道,当初问什么设计的时候不用元模型而用模型 其实这个若要修改都比较简单 就是不知道算不算一个需求
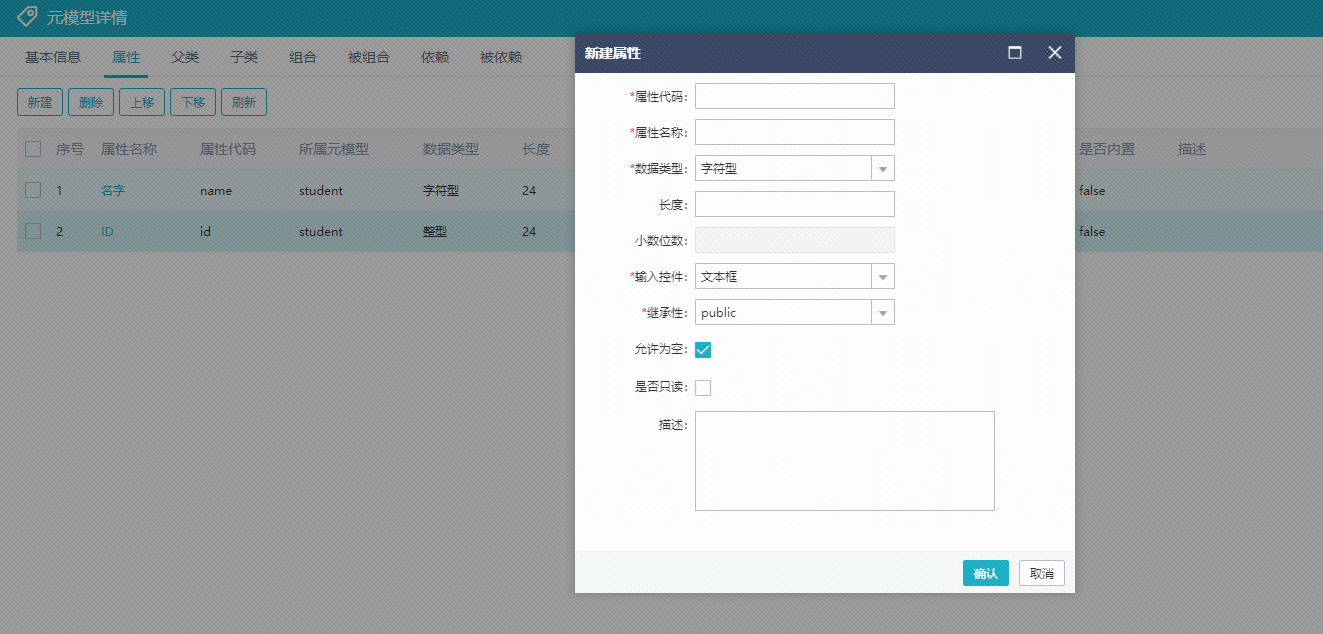
还有一个地方是元模型的详情部分 原本一期的原型除了基础的基本信息和属性
后面需要添加组合依赖的功能 这是在新建元模型里需要考虑的。
最后一个元模型的存储问题 但是给的一篇文章主要说的是新的元数据管理的方法

目前设计的理念是就是基于MOF的元模型设计,定义一系列的管理元模型的模型,就是元元模型。如上右图,这里面有类表、类属性表、类组合关系和类继承关系等等,这些就是元元模型。采用这种方式就解决了模型稳定性的问题,还带了很灵活的扩展性。当一个组织要增加一种新的元数据管理时,只需要通过元模型管理的功能,定义好元数据的属性(包含属性与元数据存储表字段映射关系)。元数据采集适配器按照模型的定义,把元数据存储到表。使用的时候,在按照元模型的定义把表里的元数据转义出来,展现到页面上。
但是今天推荐的新的元数据管理的方式:分三类
1.是元数据系统管理表例如元模型管理表之类的。这类数据(例如元元数据)量不大,但对元数据管理很重要。
存储架构:要用关系型数据库比较合适,数据量不大,单一致性的要求比较强。例如开源的Mysql,如果在配合redis内存数据库,那就更好了。
2.是元数据的应用表例如元数据关联关系等,元数据中的血缘分析、影响分析和数据地图的数据就是来源于这里。有点类似与人的社交网络分析。这个需要对海量的元数据进行分析,并将关系存储起来。
存储架构:关联关系的存储,比较推荐图数据库,例如Neo4j。之前使用过关系型数据库对这类数据进行存储。在关系比较复杂的情况下,检索的速度比较慢。因为这是一个类似与网状的关系图。要检索的数据呈几何倍数的增长。
3.元数据的事实表;即通过元数据采集适配器采集到来的原始的元数据。这类元数据可读性很差,是不能拿给用户直接来使用的。其显著的特点是数据量大,为了保持其时效性,需要按照一定频率进行更新。
存储架构:元数据事实表,采用非关系型数据库存储能够较好满足其特点。
明天计划的事情:(一定要写非常细致的内容)
核对三期的原型
需求总结
任务三修改再次提交
任务四
任务五完善
遇到的问题:(遇到什么困难,怎么解决的)
原型当中如果遇到文字命名有歧义 这种算不算需求?
收获:(通过今天的学习,学到了什么知识)




评论