发表于: 2021-02-22 23:54:42
1 2154
今天完成的事情:
列出来每一个请求的时耗分解图
学习spring-AOP,根据教程用aop记录controller的出参入参
深度思考
明天计划的事情:
代码改善,深度思考。spring-aop日志
遇到的问题:
以下
收获:
请求分耗:
| 方法名称 | 所耗时间MS |
| insertBanner | 139 |
| showBanner | 116 |
| postContents | 27 |
| selectMessageByWorkId | 79 |
| insertStudio | 221 |
| getFirst | 159 |
| Work | 131 |
| insertWork | 101 |
spring-AOP基础概念
1.面写切面编程
2.预编译+动态代理(程序运行期间)
作用:
在程序运行期间,不修改源码对已有方法进行增强。
AOP 相关术语
Joinpoint(连接点):
所谓连接点是指那些被拦截到的点。在 spring 中,这些点指的是方法,因为 spring 只支持方法类型的连接点。
Pointcut(切入点):
所谓切入点是指我们要对哪些 Joinpoint 进行拦截的定义。
Advice(通知/增强):
所谓通知是指拦截到 Joinpoint 之后所要做的事情就是通知。
通知的类型:前置通知,后置通知,异常通知,最终通知,环绕通知。
Introduction(引介):
引介是一种特殊的通知在不修改类代码的前提下, Introduction 可以在运行期为类动态地添加一些方
法或 Field。
Target(目标对象):
代理的目标对象。
Weaving(织入):
是指把增强应用到目标对象来创建新的代理对象的过程。
spring 采用动态代理织入,而 AspectJ 采用编译期织入和类装载期织入。
Proxy(代理):
一个类被 AOP 织入增强后,就产生一个结果代理类。
Aspect(切面):
是切入点和通知(引介)的结合。
AOP为什么会出现?解决了什么问题?
为了减少重复代码,将和业务代码无关的模块都分开,比如:权限,日志,事务
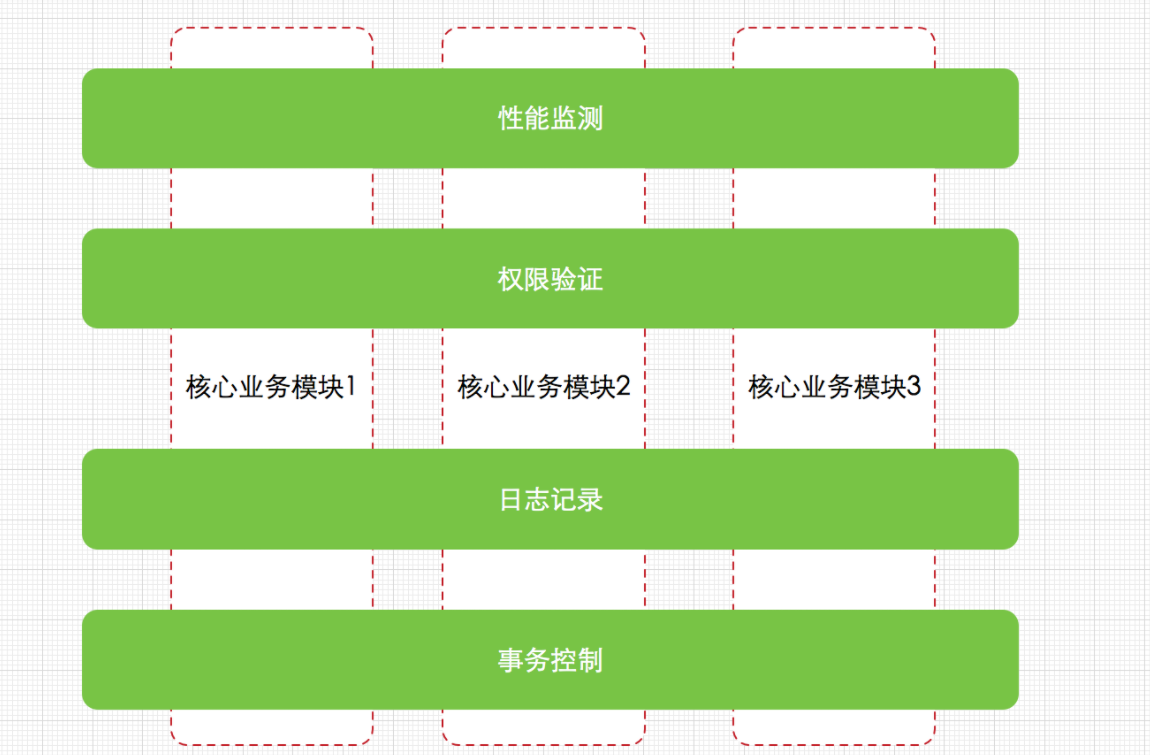
根据教程用aop记录controller的出参入参。
定义一个切入点:
/**
* 定义一个切入点
*/
@Pointcut("execution(* com.kbk.controller.*Controller.*(..))")
private void logRecordArg(){};
使用环绕通知:
/**
* 定义一个环绕通知记录controller出参入参
*/
@Around("logRecordArg()")
private Object getControllerLog(ProceedingJoinPoint point) {
//获取目标方法所在类的全限定名。
String methodName=point.getSignature().getDeclaringType().getName();
StringBuilder sb = null ;
sb = new StringBuilder(300);
// 类名+方法名
String target = point.getSignature().getDeclaringTypeName() + "." + point.getSignature().getName();
Object[] args = point.getArgs();
String[] paramsName = ((MethodSignature) point.getSignature()).getParameterNames();
sb.append(target).append(" 入参:【");
if(args != null && paramsName != null && args.length > 0 && paramsName.length > 0) {
for (int i=0; i< paramsName.length; i++) {
sb.append(" ").append(paramsName[i]).append(" = ").append(args[i]).append(",");
}
sb.deleteCharAt(sb.length()-1);
}
sb.append("】");
Object result = null;
try {
result = point.proceed();
} catch (Throwable throwable) {
throwable.printStackTrace();
logger.error("错误信息:"+throwable.getMessage());
}
sb.append(" 出参:【").append(result).append("】");
// 记录日志
logger.info(sb.toString());
// 调用结果返回
return result;
}
结果:

===============================
===============================
1.nginx服务器有什么作用?什么叫反向代理?为什么要使用反向代理?
反向代理和负载均衡。
反向代理就是nginx充当tomcat,jetty,resin等等要具体运行项目的服务器的中介。
作用:
防止主服务器被恶意攻击
为负载均衡和动静分离提供实现支持
负载均衡:使用反向代理同时代理多个相同内容的应用服务器(比如tomcat),将客户端请求分发到各个应用服务器上并接收响应返回给客户端。
2.什么是代码生成,mybatis generator代码生成是怎么实现的,还有什么办法可以生成代码?
Mybatis generator 生成的文件分两大块,共四种:实体(实体类 pojo.java、条件查询类 pojoExample.java)映射(映射文件 pojoMapper.xml、接口 pojoMapper.java)
MBG 连接数据库后会扫描指定的数据库与表,并且得到他们的所有字段、类型、长度、主键信息来建立实体类。
其中字段名会按照配置文件的规则进行格式化,MBG 中有一个类型映射表,根据 mysql 中的类型及长度信息转换为 java 的类型。
其中会遇到一些问题,对于 mysql 中的 int tinyint bigint 来说,长度信息并不会影响他们的存储长度,只会在开启自动填充零的时候对其显示效果产生影响。但是在 MBG 的默认映射表中,tinyint(1) 会转换为 java 中的 boolean。这个时候我们可以通过修改配置文件来改变映射。
在 example 类中,会生成很多条件查询、排序的方法,主要的作用是对 sql 进行拼接,内部的方法非常多,有针对每一个字段的 or and between noteuals eqals 方法,使用的时候可以根据需求进行自由拼接。
另外还可以设置排序方式,当然这部分就需要用户来自定义一段 sql 语句了。
其他的自动生成代码方法:
Velocity 模板引擎快速生成代码
https://www.ibm.com/developerworks/cn/java/j-lo-velocity1/index.html
FreeMarker
http://freemarker.foofun.cn/index.html
3.Mysql的一般而言应该配置多大的内存, 多大的硬盘 ,多大的连接数?
这就涉及到了MySQL的优化了了吧。
一般来说 Mysql 的内存设置应该尽量接近物理机的内存,但又要给其他的服务与系统留下足够的内存空间。
内存和硬盘相比微不足道
硬盘,机械硬盘和固态硬盘又不一样,
这要取决于磁盘,如果你使用的是 SSD 固态硬盘,它不需要寻址,也不需要旋转碟片。打住打住!!!你千万可别理所当然的认为:“既然SSD速度更快,我们把线程数的大小设置的大些吧!!”
结论正好相反!无需寻址和没有旋回耗时的确意味着更少的阻塞,所以更少的线程(更接近于CPU核心数)会发挥出更高的性能。只有当阻塞密集时,更多的线程数才能发挥出更好的性能。
公理:你需要一个小连接池,和一个充满了等待连接的线程的队列
实际上,连接池的大小的设置还是要结合实际的业务场景来说事。
比如说,你的系统同时混合了长事务和短事务,这时,根据上面的公式来计算就很难办了。正确的做法应该是创建两个连接池,一个服务于长事务,一个服务于"实时"查询,也就是短事务。
还有一种情况,比方说一个系统执行一个任务队列,业务上要求同一时间内只允许执行一定数量的任务,这时,我们就应该让并发任务数去适配连接池连接数,而不是连接数大小去适配并发任务数。
参考网址:https://www.jianshu.com/p/1c9ffde4c704
4.在端到端的请求当中,建立Http连接需要多久,Model通过JSP转成Json需要多久,Nginx调用Resin需要多久,Service访问DB需要多久,一个Sql语句执行的时间是多久。
找到了这个,明天试试
➜ ~ curl -w "@curl-format.txt" -o /dev/null -s -L "http://cizixs.com"
time_namelookup: 0.012
time_connect: 0.227
time_appconnect: 0.000
time_redirect: 0.000
time_pretransfer: 0.227
time_starttransfer: 0.443
----------
time_total: 0.867
可以看到这次请求各个步骤的时间都打印出来了,每个数字的单位都是秒(seconds),这样可以分析哪一步比较耗时,方便定位问题。这个命令各个参数的意义:
-w:从文件中读取要打印信息的格式
-o /dev/null:把响应的内容丢弃,因为我们这里并不关心它,只关心请求的耗时情况
-s:不要打印进度条
从这个输出,我们可以算出各个步骤的时间:
DNS 查询:12ms
TCP 连接时间:pretransfter(227) - namelookup(12) = 215ms
服务器处理时间:starttransfter(443) - pretransfer(227) = 216ms
内容传输时间:total(867) - starttransfer(443) = 424ms
参考网址:https://www.ruanyifeng.com/blog/2019/09/curl-reference.html
https://cizixs.com/2017/04/11/use-curl-to-analyze-request/
5.什么是Sql注入,应该怎么解决?对于未做SQL注入防范的程序,你可以直接通过调用接口删掉表吗?
SQL注入就是一些攻击者把SQL命令插入到web表单的输入或者页面的url中,欺骗服务器执行恶意的SQL语句。在某些表单中,用户输入的内容直接用来构造或者影响动态SQL命令,或者作为存储过程的输入参数。这类表单特别容易收到SQL注入式的攻击。
解决方法:
1)采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setXXX方法传值即可。
2)使用正则表达式过滤传入的参数.
3)字符串过滤
SQL注入攻击实例
比如在一个登录界面,要求输入用户名和密码:
可以这样输入实现免帐号登录:
用户名: ‘or 1 = 1 –
密 码:
点登陆,如若没有做特殊处理,那么这个非法用户就很得意的登陆进去了.(当然现在的有些语言的数据库API已经处理了这些问题)
这是为什么呢? 下面我们分析一下:
从理论上说,后台认证程序中会有如下的SQL语句:
String sql = "select * from user_table where username=
' "+userName+" ' and password=' "+password+" '";
当输入了上面的用户名和密码,上面的SQL语句变成:
SELECT * FROM user_table WHERE username=
'’or 1 = 1 -- and password='’
分析SQL语句:
条件后面username=”or 1=1 用户名等于 ” 或1=1 那么这个条件一定会成功;
然后后面加两个-,这意味着注释,它将后面的语句注释,让他们不起作用,这样语句永远都能正确执行,用户轻易骗过系统,获取合法身份。
这还是比较温柔的,如果是执行
SELECT * FROM user_table WHERE
username='' ;DROP DATABASE (DB Name) --' and password=''
….其后果可想而知…
6.在内存里拼装数据会节省时间吗?如果不能,为什么要选择单表查询,而不是直接拼装成Sql语句。
内存拼装数据是啥意思,单表查询速度快
7.为什么一般而言,不允许使用连表查询,不允许使用复杂的Group By等语句,为什么不允许使用存储过程?
优点:
a,简化了代码逻辑
b,减少了不必要的数据传输,毕竟查询完很多数据都是不需要的
缺点:
a,数据表如果由修改那么连表查询就需要做修改,工作量未知
b,连表查询会锁表,不利于写操作
c,sql 中可能会有复杂的嵌套,写完就忘
8.为什么响应时间一般不允许超过200MS,怎么查看一个请求从发起到结束,耗费在什么地方了?
超过200ms会影响用户体验,通过配置nginx的conf.xml文件,使用aop进行日志记录,记录controller和service的执行时间。
主要耗费在网络延时,数据库连接这几块地方。
9.为什么要自测,仅仅使用Postman来测试足够吗?什么是本地测试,什么是在开发环境测试?在开发过程中,应该每天部署代码到开发环境吗,为什么?
自测是因为自己需要对写出来的程序运行情况的一个了解,哪个地方报错,哪个地方需要调优都要了解到。仅仅使用postman测试不够,因为不知道细节方面的耗时,比如连接db的时间,service的运行时间,controller的运行时都不能了解到。
本地测试就是在ide写完代码之后部署到本地tomcate等服务器进行测试。
开发环境(DEV):开发环境是程序猿们专门用于开发的服务器,配置可以比较随意, 为了开发调试方便,一般打开全部错误报告。
测试环境(UAT):一般是克隆一份生产环境的配置,一个程序在测试环境工作不正常,那么肯定不能把它发布到生产机上。
生产环境(PROD):是指正式提供对外服务的,一般会关掉错误报告,打开错误日志。
需要,因为要持续集成,改完代码立即提交。
10.保存图片有几种方式?什么样的情景下应该使用哪一种?
保存在数据库或者保存在硬盘
如果图片比较小,可以选择二进制直接存储在数据库中
如果过大就要保存在硬盘中,数据库对应的字段是链接或者服务器相对路径




评论