发表于: 2020-11-19 23:45:13
1 2149
今天完成的事情:
java中使用增强型的for循环
for (String name : nameArray) { }
1、String name--声明会带有数组单一元素的循环变量,数组元素的类型必须与循环变量的类型匹配,name在循环过程中会带有不同元素的值。
2、冒号(:)--代表“in”
3、nameArray--要被逐个运行的集合,这必须是对数组或其他集合的引用。
上面这行程序以中文来说就是:“对nameArray中的每个元素执行一次”而编译器会这么认为:
1、创建名称为name的String变量.
2、将nameArray的第一个元素赋值给name。
3、执行重复的内容。
4、赋值给下一个元素name。
5、重复执行至所有元素都被运行为止。
创建名词为student的Student(集合),将list的第一个元素(集合)赋值给student,执行重复类容,赋值给下一个元素(集合)student,重复执行至所有元素都被运行为止。
map概述+集合的常用方法
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即`java.util.Map`接口。
我们通过查看`Map`接口描述,发现`Map`接口下的集合与`Collection`接口下的集合,它们存储数据的形式不同,如下图。

* `Collection`中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。
* `Map`中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。
* `Collection`中的集合称为单列集合,`Map`中的集合称为双列集合。
* 需要注意的是,`Map`中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
学了map的四个方法,put(添加),remove(删除),get(获取),containsKey(判断是否存在)
import java.util.HashMap;
import java.util.Map;
public class Demo01map {
public static void main(String[] args) {
// TODO Auto-generated method stub
// show01();
// show02();
// show03();
show04();
}
private static void show04(){
Map<String,Integer> map = new HashMap<>();
map.put("小明",130);
map.put("小红",140);
map.put("小黑",120);
System.out.println(map);
boolean v1 = map.containsKey("小黑");
System.out.println("v1:"+v1);//
boolean v2 = map.containsKey("小黄");
System.out.println("v1:"+v2);//
}
private static void show01() {
Map<String,String> map = new HashMap<>();
String v1 = map.put("小黑","可乐");
System.out.println("v1="+v1);
String v2 = map.put("小黑","雪碧");
System.out.println("v2="+v2);
System.out.println(map);
map.put("静静","凯凯");
map.put("笨蛋","傻狗");
map.put("傻猫","天才");
System.out.println(map);
}
private static void show02(){
Map<String,Integer> map = new HashMap<>();
map.put("小明",130);
map.put("小红",140);
map.put("小黑",120);
System.out.println(map);
Integer v1 = map.remove("小红");
System.out.println("v1:"+v1);//v1=140
System.out.println(map);
// int v2 = map.remove("小蓝");//自动插箱,空指针异常
Integer v2 = map.remove("小红");
System.out.println("v1:"+v2);//v1=140
System.out.println(map);
}
private static void show03(){
Map<String,Integer> map = new HashMap<>();
map.put("小明",130);
map.put("小红",140);
map.put("小黑",120);
System.out.println(map);
Integer v1 = map.get("小黑");
System.out.println("v1:"+v1);//v1=140
// int v2 = map.remove("小蓝");//自动插箱,空指针异常
Integer v2 = map.get("小红");
System.out.println("v1:"+v2);//v1=140
}
}
ResultMap
MyBatis中在查询进行select映射的时候,返回类型可以用resultType,也可以用resultMap,resultType是直接表示返回类型的,而resultMap则是对外部ResultMap的引用,但是resultType跟resultMap不能同时存在。
在MyBatis进行查询映射的时候,其实查询出来的每一个属性都是放在一个对应的Map里面的,其中键是属性名,值则是其对应的值。
当提供的返回类型属性是resultType的时候,MyBatis会将Map里面的键值对取出赋给resultType所指定的对象对应的属性。
所以其实MyBatis的每一个查询映射的返回类型都是ResultMap,只是当我们提供的返回类型属性是resultType的时候,MyBatis对自动的给我们把对应的值赋给resultType所指定对象的属性,而当我们提供的返回类型是resultMap的时候,因为Map不能很好表示领域模型,我们就需要自己再进一步的把它转化为对应的对象,这常常在复杂查询中很有作用。
复杂查询就是在一个实体类中嵌套另外一个实体类,这时候可以使用ResultMap的association标签,简单的看了一下。之后涉及在来使用吧。
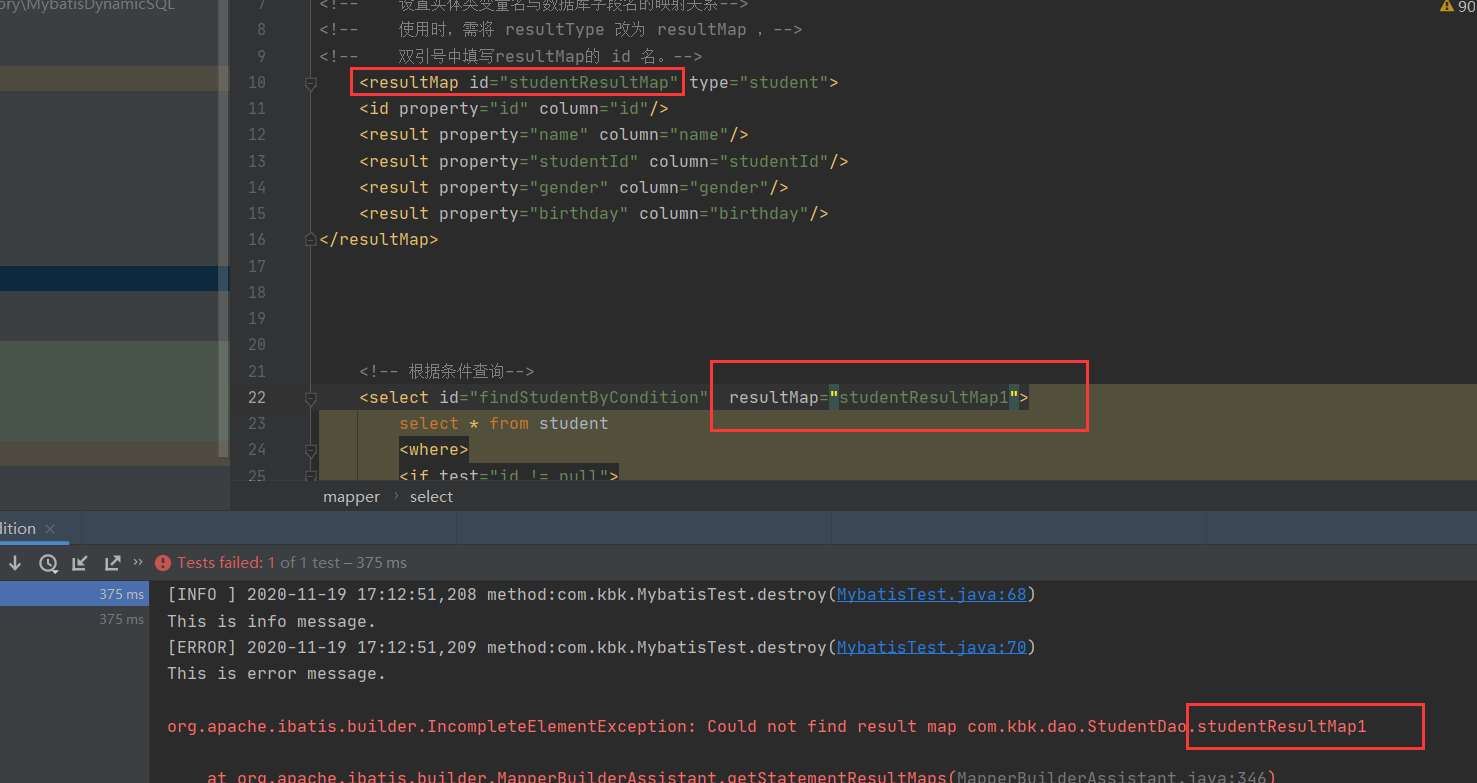
resultMap的实现,注意<resultMap id="studentResultMap",这里的id和下面select配置resultMap="studentResultMap"是一一对应的,错了就会报错。
type="student">,这个对应的是实体类
<resultMap id="studentResultMap" type="student">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="studentId" column="studentId"/>
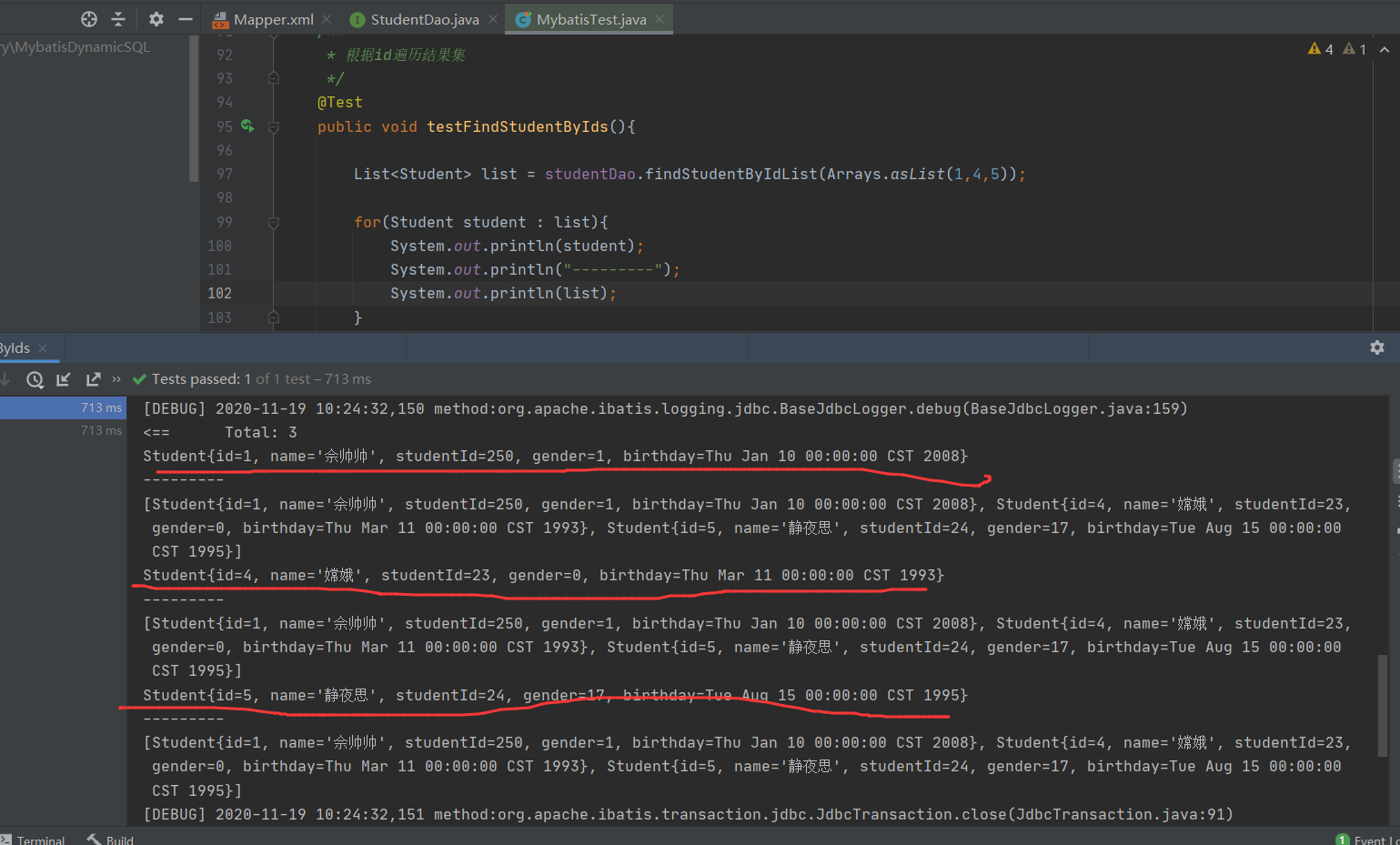
<result property="gender" column="gender"/>
<result property="birthday" column="birthday"/>
</resultMap>
<!-- 根据条件查询-->
<select id="findStudentByCondition" resultMap="studentResultMap">
select * from student
<where>
<if test="id != null">
and id = #{id}
</if>
<if test="name != null" >
and name = #{name}
</if>
</where>
</select>
运行成功。
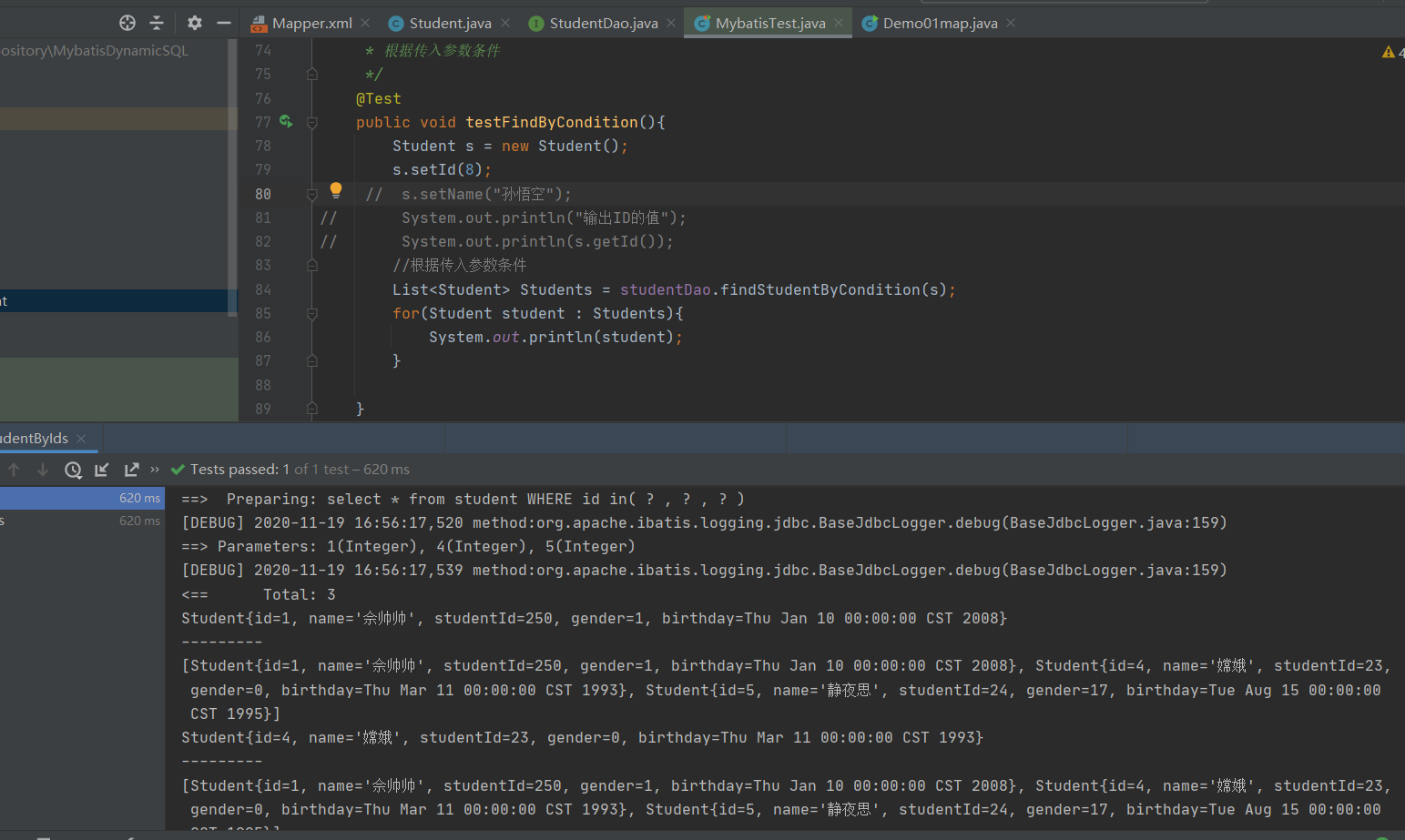
报错如下:
select * from table 的缺点
《阿里java开发手册》中 MySQL 部分描述:
4 - 1. 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明:
增加查询分析器解析成本。
增减字段容易与 resultMap 配置不一致。
无用字段增加网络 消耗,尤其是 text 类型的字段。
开发手册中比较概括的提到了几点原因,让我们深入一些看看:
1. 不需要的列会增加数据传输时间和网络开销
用“SELECT * ”数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
增大网络开销;* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。如果DB和应用程序不在同一台机器,这种开销非常明显
即使 mysql 服务器和客户端是在同一台机器上,使用的协议还是 tcp,通信也是需要额外的时间。
2. 对于无用的大字段,如 varchar、blob、text,会增加 io 操作
准确来说,长度超过 728 字节的时候,会先把超出的数据序列化到另外一个地方,因此读取这条记录会增加一次 io 操作。(MySQL InnoDB)
3. 失去MySQL优化器“覆盖索引”策略优化的可能性
SELECT * 杜绝了覆盖索引的可能性,而基于MySQL优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式。
从上面几点来看,对于经常和数据库打交道的我们来说确实应该用select 字段名 来进行查询。
<!-- 根据条件查询-->
<select id="findStudentByCondition" resultMap="studentResultMap">
select id, name, studentId, gender, birthday from student
<where>
<if test="id != null">
and id = #{id}
</if>
<if test="name != null" >
and name = #{name}
</if>
</where>
</select>
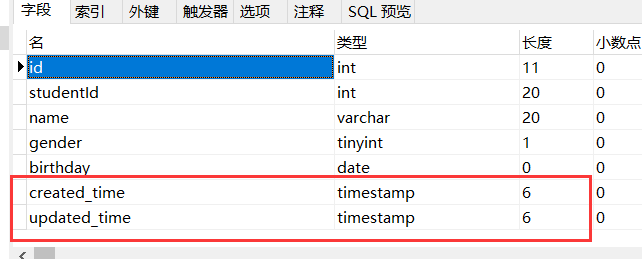
created_time和updated_time
数据库设计表的内容
timestamp,显示年月日时分秒
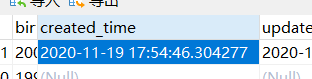
实体类
package com.kbk.pojo;
import java.sql.Timestamp;
import java.util.Date;
public class Student{
private Integer id;
private String name;
private Integer studentId;
private Integer gender;
private Date birthday;
private Timestamp created_time;
private Timestamp updated_time;
public Student(){
}
public Student(Integer id, String name,Integer studentId,Integer gender,Date birthday,Timestamp created_time,Timestamp updated_time){
this.id = id;
this.name = name;
this.studentId = studentId;
this.gender = gender;
this.birthday = birthday;
this.created_time = created_time;
this.updated_time = updated_time;
}
配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
<mapper namespace="com.kbk.dao.StudentDao">
<!-- 设置实体类变量名与数据库字段名的映射关系-->
<!-- 使用时,需将 resultType 改为 resultMap ,-->
<!-- 双引号中填写resultMap的 id 名。-->
<resultMap id="studentResultMap" type="student">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="studentId" column="studentId"/>
<result property="gender" column="gender"/>
<result property="birthday" column="birthday"/>
<result property="created_time" column="created_time"/>
<result property="updated_time" column="updated_time"/>
</resultMap>
<!-- 根据条件查询-->
<select id="findStudentByCondition" resultMap="studentResultMap">
select id, name, studentId, gender, birthday, created_time, updated_time from student
<where>
<if test="id != null">
and id = #{id}
</if>
<if test="name != null" >
and name = #{name}
</if>
</where>
</select>
测试结果:
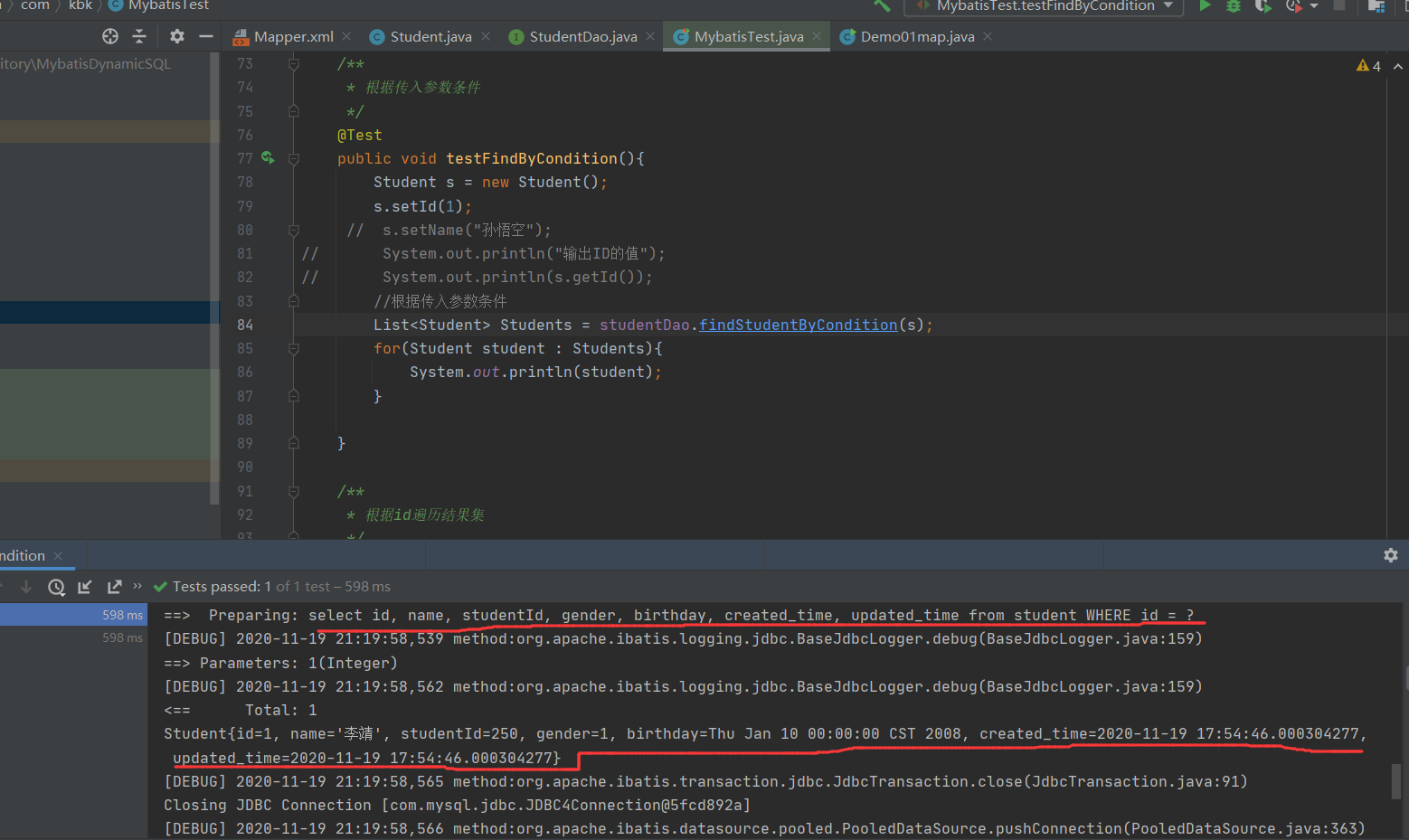
25.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
create_at是在行插入时以当时的时间为值插入。
update_at实在行一旦被修改的时候,以当时时间为值插入。
这两个字段做为数据的属性,不应该开发给外部调用的接口。
这是因为我修改了着id=1的内容,所以CreateAt和UpdateAt时间相同。

使用自定义域名并通过配置本地Host来配置DB连接文件
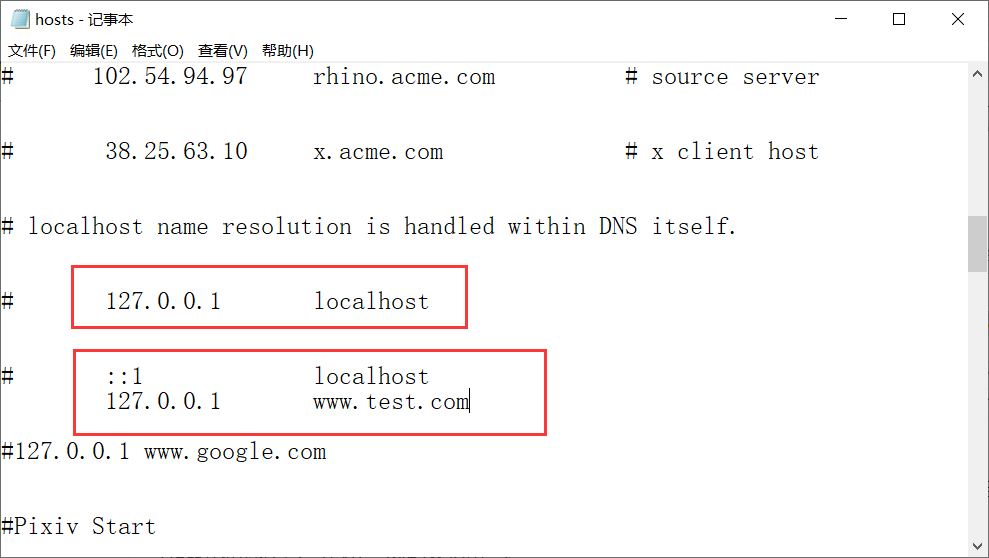
hosts文件详解
localhost是一个域名,127.0.0.1为IP地址。Windows系统中,约定127.0.0.1为本地IP地址。localhost是其对应的域名。
Host文件的位置: 在XP 、win7系统中,HOST文件 位于系统盘C:\Windows\System32\drivers\etc中,如果进去没有看到Hos文件,是因为某些系统将Host文件隐藏了。
什么是HOST文件: Hosts是一个没有扩展名的系统文件,其基本作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,一旦找到,系统会立即打开对应网页,如果没有找到, 则系统再会将网址提交DNS域名解析服务器进行IP地址的解析,如果发现是被屏蔽的IP或域名,就会禁止打开此网页!
后面的目前还不能理解,现在不打算深入学习这个知识点。
来看一下Hosts文件的工作方式以及它在具体使用中起哪些作用。
根据以上的介绍我们可以总结出Host文件的三个主要作用:
1、加快域名解析
对于要经常访问的网站,我们可以通过在Hosts中配置域名和IP的映射关系,提高域名解析速度。由于有了映射关系,当我们输入域名计算机就能很快解析出IP,而不用请求网络上的DNS服务器。 例如:Host文件中添加一条:222.73.44.198 blog.itful.com (IP与域名中间要有空格,IP地址一定要输入正确,不然就访问不了该网站了)——可以通过运行CMD,输入“ping 网站域名” 来获得网站的IP地址!这样访问侠客岛速度就会略快一点啦,因为他不需要经过DNS域名服务器进行IP地址的解析!
2、方便局域网用户
在很多单位的局域网中,会有服务器提供给用户使用。但由于局域网中一般很少架设DNS服务器,访问这些服务器时,要输入难记的IP地址。这对不少人来说相当麻烦。现在可以分别给这些服务器取个容易记住的名字,然后在Hosts中建立IP映射,这样以后访问的时候,只要输入这个服务器的名字就行了。
3、屏蔽网站
现在有很多网站不经过用户同意就将各种各样的插件安装到你的计算机中,其中不乏有病毒木马。对于这些网站我们可以利用Hosts把该网站的域名映射到一个错误的IP或本地计算机的IP,这样就不用访问了。在Windows系统中,约定 127.0.0.1为本地计算机的IP地址, 0.0.0.0是错误的IP地址。 例如,我们在Hosts中,输入以下内容(一个例子)127.0.0.1 www.puchunwei.com # 这个网站影响我孩子的健康成长,我要屏蔽他这样,计算机解析域名 www.puchunwei.com 时,就解析到本机IP或错误的IP,达到了屏蔽不健康网站的目的。现在某些病毒,恶意程序会修改我们的host文件,导致我们无法访问某些网站,当发现某些网站不能访问时,我们可以进入Host文件进行观察,如果是因为Host文件造成的网站无法访问,删除病毒添加的语句,就可以对网站进行正常访问
4、企业开发过程中,使用本地域名代替繁琐的Ip地址进行开发
因为企业开发中可能使用的多台服务器,每台服务器都有自己的地址,可以在开发机器上配置一个容易记住的域名与服务器对应,方便进行进行开发测试。
先打开本地hosts文件,在下面添加127.0.0.1 www.test.com
然后打开jdbc.properties配置文件,在jdbc.url=jdbc:mysql://localhost:3306修改成www.test.com:3306/db4
程序执行成功

明天计划的事情:
做这两天的思维导图,然后开始做任务二, 查看接口定义格式,分别给出CRUD的接口文档格式, 根据接口文档,使用Spring Rest 编写对应的Controller,日志记录接收参数后,暂时不用写业务逻辑,直接返回JSP,直接用Json Tag-lib 生成假数据
遇到的问题:
以上,
收获:增强for循环,for (String name : nameArray) { },每次将nameArray中的第一个元素赋给name,重复执行,直到所有元素都被运行完为止。map的四个方法,put(添加),remove(删除),get(获取),containsKey(判断是否存在),resultMap的实现,select * from table 的缺点,扫描所有字段,修改数据库结构,在使用可能会出错,无法使用索引,created_time(插入字段的时间)和updated_time(修改字段的时间),hosts文件的了解,知道可以用自定义域名去绑定一个ip,这个可以通过这个域名访问这个ip,也可以不使用域名,直接访问ip




评论