发表于: 2020-10-29 23:58:17
1 2600
Java源文件经编译器,编译成字节码程序,通过JVM将每一条指令翻译成不同平台机器码,通过特定平台运行。
数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。我们可以通过设定连接池最大连接数来防止系统无尽的与数据库连接。
3.where: where元素知道只有一个以上的if条件有值的情况下才去插入where子句,若有“AND"或者"OR"开头,则where元素也会去将他们删除
5.什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
进行svn操作需要记住很多操作命令,而且每次都要重复输入。小乌龟就是这样一个简化svn操作的软件。极大的方便了svn操作。
每次提交创建一个新的版本,版本号会自动修改。之所以需要版本号是因为我们需要多人协作开发的时候,解决以下列问题:1.备份多个版本,占用磁盘空间大 2.解决代码冲突困难 3.追溯问题代码的修改人和修改时间 4.难于恢复至以前正确版本 5.无法进行权限控制 6.容易引发BUG,项目版本发布困难
6.什么是AOP,适用于哪些场景,AOP的实现方案有哪些?
7.Map,List,Array,Set之间的关系是什么,分别适用于哪些场景,集合大家族还有哪些常见的类?
8.Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
9..JDBCTemplate和JDBC
10.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
11.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
try/catch是java程序员经常用的程序块,怎么用,什么时候catch异常,什么时候抛出异常?用不好,程序可能会有致命性错误。
使用的基本原则
对异常的处理,两种方式,一是添加 throws exceptions,向上抛出,交由方法的调用方处理该异常;二是使用try/catch块,捕捉异常,自己处理。
选择哪种方式,取决于异常应该怎么处理。
使用抛出异常的情景主要有:
1. 异常必须由容器来处理,异常时容器做出不同处理的依据和触发;
例如:有事务处理的方法中,事务相关的逻辑必须抛出异常,而不能捕获异常,否则会导致事务不回滚。
2. 本地方法不知道如何处理,只有调用方才可能知道如何处理异常;
例如:一些底层的方法,其可能出现多种异常,且调用方可能根据不同的异常做出不同的处理,只能抛出异常,而且必须是具体的异常类型,而不能是笼统的Exception类型。
使用try/catch捕获异常的情景主要有:
1. 程序块中语句可能的异常不能引起其他逻辑中断;
例如:缓存逻辑不能影响正常的逻辑运行,故缓存逻辑应该放在try/catch块中。
2. 必须对异常进行处理,否则会降低用户使用体验。
例如:异常到了Controller层,若不处理则会返回404或500错误页面,因此,必须使用try/catch处理各种异常。
如果出现DB断开---->一般是开销太大才会DB断开,一般很少发生
正常状况下mysql对于空闲的链接可能会8小时自动关闭。
12.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
最常用的即是error,warn,info,debug四种了
模块运行日志:模块运行日志包括消息队列的监控、线程的运行状态。该日志应该以INFO级别打印,并且采用间隔打印,或叫做定时打印。以减少日志打印总量。从该角度可以反应出该模块是否有消息队列积压,是否所有线程都运行正常。消息队列的打印可以采用日下格式:
使用统一的关键字Monitor来标示模块运行日志。队列监控日志使用|队列名|消息放入速度|消息取出速度|消息放入个数|消息取出个数|当前队列消息个数|。线程监控日志使用|线程名|线程状态码|,线程状态码可以自己扩展。0表示正常1表示运行结束2表示线程阻塞。
业务日志:业务日志打印用户请求流程,能够清楚的使用某几个关键字可以提取一个用户的业务流程就可以。业务日志要分详细日志,如上BossAgent打印的日志,非常详细,应该都打印DEBUG级别的日志,而另外就需要打印总结性日志,总结性日志以INFO级别打印,包括|请求开始时间|请求结束时间|请求主体|请求类型|请求结果|请求外部资源返回结果|。其中请求主体可以继续扩展,如BossAgent的请求主体可以扩展为|手机号码|省份编码|MM2消息SEQUENCE|,DSS的请求主体可能属性更多一些,|手机号码|手机密码|手机UA|手机MOD|手机MAN|计费类型|套餐类型|白名单|。
模块性能日志:模块的性能日志应该能够通过该日志清晰的反应该模块目前性能,包括外部请求的压力,内部请求处理速度。
模块外部资源日志:模块的外部资源日志需要详细记录,现今单独的模块很少见了,很多大型复杂的系统往往是由多个模块构成,模块间采用或标准或私有协议进行通信。这种场景下爆发的问题往往比较复杂,并且与多个模块都有关系或是责任。所以在模块级别上将该模块所依赖的外部资源都打印出来非常重要,通过这些日志应该能够完成快速定位问题与哪些模块相关联或是哪些模块需要负根本责任。通常模块的外部资源包括数据库,系统间内部模块、第三方系统。如BossAgent的外部资源包括数据库,系统间内部模块为PSS、第三方系统应该是一级Boss。数据库资源的打印应该包括所有的SQL语句,这个非常重要,无论是问题的定位还是后续的SQL优化,还是数据库架构的调整,都需要这些信息能够快读的整理出该模块所有的SQL语句,提供给专业的DBA进行分析。SQL语句的打印还应该包括参数的打印。
13.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
14.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
15.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
控制反转(Inversion of Control) 就是依赖倒置原则的一种代码设计的思路。具体采用的方法就是所谓的依赖注入(Dependency Injection)。
什么是依赖倒置原则?假设我们设计一辆汽车:先设计轮子,然后根据轮子大小设计底盘,接着根据底盘设计车身,最后根据车身设计好整个汽车。这里就出现了一个“依赖”关系:汽车依赖车身,车身依赖底盘,底盘依赖轮子。
但这时候你如果需要修改轮子大小,那么底盘,车身,汽车整个都需要修改。
而依赖倒置是:先定汽车,在来设计车身,底盘,最后设计轮子,这样轮子的修改不会影响到整个汽车的修改。
依赖注入,就是把底层类作为参数传入上层类,实现上层类对下层类的“控制”。这里我们用构造方法传递的依赖注入方式重新写车类的定义。
1.增加耦合,会访问到内部属性
2.更新的地方比较多,难于维护
16.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
领域模型是领域内的概念类或现实世界中对象的可视化表示,又称为概念模型或分析对象模型,它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。
贫血模型是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务逻辑层。有人将我们这里说的贫血模型进一步划分成失血模型(领域对象完全没有业务逻辑)和贫血模型(领域对象有少量的业务逻辑),我们这里就不对此加以区分了。充血模型将大多数业务逻辑和持久化放在领域对象中,业务逻辑(业务门面)只是完成对业务逻辑的封装、事务和权限等的处理。
贫血模型和充血模型的分层架构。更加细粒度的有失血模型,贫血模型,充血模型,胀血模型。贫血模型就是domain ojbect包含了不依赖于持久化的领域逻辑,而那些依赖持久化的领域逻辑被分离到Service层。失血模型简单来说,就是domain object只有属性的getter/setter方法的纯数据类,所有的业务逻辑完全由business object来完成(又称Transaction Script),这种模型下的domain object被Martin Fowler称之为“贫血的domain object”。
充血模型和第二种模型差不多,所不同的就是如何划分业务逻辑,即认为,绝大多业务逻辑都应该被放在domain object里面(包括持久化逻辑),而Service层应该是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层。
优点是系统的层次结构清楚,各层之间单向依赖,Client->(Business Facade)->Business Logic->Data Access(http://ADO.NET)。当然Business Logic是依赖Domain Object的。似乎现在流行的架构就是这样,当然层次还可以细分。
该模型的缺点是不够面向对象,领域对象只是作为保存状态或者传递状态使用,所以就说只有数据没有行为的对象不是真正的对象。在Business Logic里面处理所有的业务逻辑,在POEAA(企业应用架构模式)一书中被称为Transaction Script模式。
充血模型:层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成Client->(Business Facade)->Business Logic->Domain Object->Data Access。
优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。
缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。即使划分好了业务逻辑,由于分散在Business Logic和Domain Object层中,不能更好的分模块开发。熟悉业务逻辑的开发人员需要渗透到Domain Logic中去,而在Domian Logic又包含了持久化,对于开发者来说这十分混乱。 其次,因为Business Logic要控制事务并且为上层提供一个统一的服务调用入口点,它就必须把在Domain Logic里实现的业务逻辑全部重新包装一遍,完全属于重复劳动。
17.clean,install,package,deploy分别代表什么含义?
18.怎么样能让Maven跳过JUnit?
Maven打包项目为什么要跳过测试?
答:执行maven打包发布项目时,如果测试类中有测试用例代码,打包maven默认会将测试用例一起编译,编译不通过则会报错。且容易对数据库的数据造成影响。
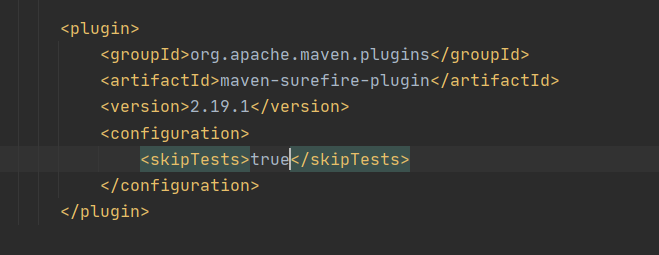
可使用mvn命令
(1) mvn install -Dmaven.test.skip=true
(2) mvn install -DskipTests
在执行run as时候加上参数:
clean install compile -Dmaven.test.skip=true
配置IDEA

1. Log4j就是帮助开发人员进行日志输出管理的API类库。它最重要的特点就可以配置文件灵活的设置日志信息的优先级、日志信息的输出目的地以及日志信息的输出格式。
2. Log4j除了可以记录程序运行日志信息外还有一重要的功能就是用来显示调试信息。
3. 程序员经常会遇到脱离java ide环境调试程序的情况,这时大多数人会选择使用System.out.println语句输出某个变量值的方法进行调试。这样会带来一个非常麻烦的问题:一旦哪天程序员决定不要显示这些System.out.println的东西了就只能一行行的把这些垃圾语句注释掉。若哪天又需调试变量值,则只能再一行行去掉这些注释恢复System.out.println语句。
使用log4j可以很好的处理类似情况。
20.为什么DB的设计中要使用Long来替换掉Date类型?
21.自增ID有什么坏处?什么样的场景下不使用自增ID?
23.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
create_at是在行插入时以当时的时间为值插入。
update_at实在行一旦被修改的时候,以当时时间为值插入。
这两个字段做为数据的属性,不该该调用给外部的接口。
26.修真类型应该是直接存储Varchar,还是应该存储int?
什么是VARCHAR、Text、LongText?
它们都是MySQL数据库的字符串类型,用来存储字符数据。区别是存储的数据长度、大小不一样。我们可以根据需求选择使用哪种字符串类型。
在字符长度不超过255时 使用一个字节存储长度
超过255时用两个字节存储长度
每行的varchar总和不得超过65535字节 如果想存储更长的字符串建议选用text格式
既然varchar是变长的 而且不超过255字符时都是用一个字节来存储长度 那么是不是意味着varchar(4) 与varchar(100) 在存储四个字符长度的内容 比如 "abcd"时是完全一样的呢?
mysql在查询时对于varchar字段在内存中是采用固定宽度而不是储存时的变长宽度 尤其是查询时创建的隐形临时表 所以在选择字段属性时还是适可而止 根据自己的业务来选择最合适的并且最小的长度 从而来提高查询速度 减少数据库服务器的开销
何时选用varchar列来储存?
1 字符串列最大长度比平均长度大很多的列 充分发挥变长的特点
2 字符串列较少被更新的列 因为innodb引擎一个存储页为16k 频繁的更新变长字段可能导致存储页的分裂 产生存储碎片
3 多字节字符集 如utf-8
需要注意的是:
mysql数据库的varcahr类型在4.1以下版本中最大长度限制为255字节
mysql5.0以上的版本中varchar数据类型的长度支持到了65535字节。
Text和LongText 也是长度可变的类型
Text的最大长度是可以存储 65535 (2^16 – 1) 个字符
LongText的最大长度是可以存储4294967295 (2^32 – 1) 个字符。
varchar有系统默认长度,所以必须在括号里定义长度,可以有默认值。
text不能有默认值,存储或检索过程中,不存在大小写转换。
经常变化的字段用varchar,能用varchar的地方不用text(效率上: char>varchar>text)
29.为什么不可以用Select * from table?
1、mysql拿到一条命令,会去解析命令、优化查询,然后去存储引擎执行查找.SELECT * 语句取出表中的所有字段,会解析更多的 对象,字段,权限,属性相关,不论该字段的数据对调用的应用程序是否有用,这会对服务器资源造成浪费,导致优化和效率问题,对服务器的性能产生一定的影响。
2、如果表的结构在以后发生了改变,那么SELECT * 语句可能会取到不正确的数据甚至是出错。
3、执行SELECT * 语句时,select * 语句要对表中所有列进行权限检查,这部分也是开销
4、使用SELECT * 语句将不会使用到覆盖索引,不利于查询的性能优化.(索引覆盖:索引覆盖是一种速度极快,效率极高,业界推荐的一种查询方式.就是select的数据列只用从索引中就能够获得,不必从数据表中读取,也就是查询列要被所使用的索引覆盖)
5、在文档角度来看,SELECT * 语句没有说明将要取出哪些字段进行操作,不具备针对性,不推荐。
6、用 select * 语句插入一个表,以后表结构修改了,如增加或删除了一列,对代码影响很大,如果只是恰好只获取自己需要的那几列,表结构的修改对你的代码影响就会比较小,便于后期项目维护。
30.maven是什么,和Ant有什么区别?




评论