发表于: 2020-09-18 22:26:12
1 2370
今天完成的事情:完成接口的改动,数据库表设计。
明天计划的事情:方案评审没过,明天团队一起协作,考虑多种方案。
遇到的问题:方案没有设计好
收获:
数据库设计知识点整理
1. mysql5.0版本以后,char(n),varchar(n)其中的n表示的是字符个数,不管是一个字母还是一个汉字,只是不同编码,它底层存储时大小不一,比如UTF-8的话,一个字母占1字节,一个汉字占3字节,Unicode编码都是2个字节。
2. char是定长,不管实际的value,都会占用指定的n个字符空间,varchar是可变长,占用空间+1<=n。
当varchar大于某些数值的时候,其会自动转换为text,大概规则如下:
- 大于varchar(255)变为 tinytext
- 大于varchar(500)变为 text
- 大于varchar(20000)变为 mediumtext
3. utf8mb4相比utf8最大的作用 ,如果文本文件中有Emoji,就是表情,以及生僻字就要用到utf8mb4。在utf8mb4字符集下,字符串的char类型会多消耗一些空间,建议utf8mb4字符集下,使用varchar代替char类型。
4. 在数据量很大的情况下,分页查询很慢,怎么优化?
一般分页查询是
select [*|字段列表] from table_name where expresion limit m,n;
--m:数据检索的起始位置,也就是偏移量
--n:每页显示的数据条数
下面就是实例
select * from orders_history where type=8 limit 1000,10;
这种情况查找时候,每次分页查询都是全局从前到后,数据量大的情况下,速度很慢。
优化的方法:
4.1 使用子查询id优化
先定位偏移位置id,然后查询,适用于id连续自增的情况
例如原查询
select * from orders_history limit 100000,300;
优化后
select * from user where id>=(select id from user limit 8008,1) limit 300;
4.2 使用 id 限定优化
与上面有点类似,如果在连续自增的id情况下,把id限定到我们需要的区间,可以使用 id between and 来查询。还可以用in
select * from user where id between 80000 and 80200 limit 200;
4.3 使用临时表优化
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
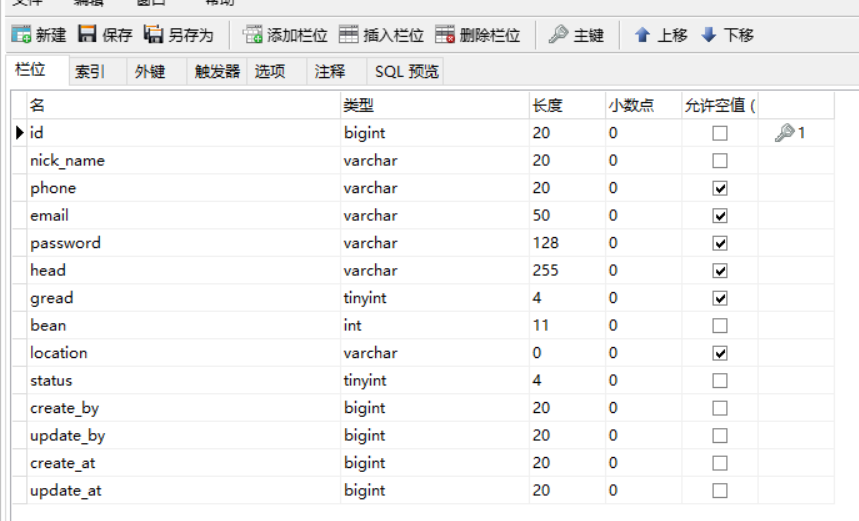
数据库表
由于文章内容用Emoji表情,所以我们所有的表的编码设置的是UTF-8utf8mb4
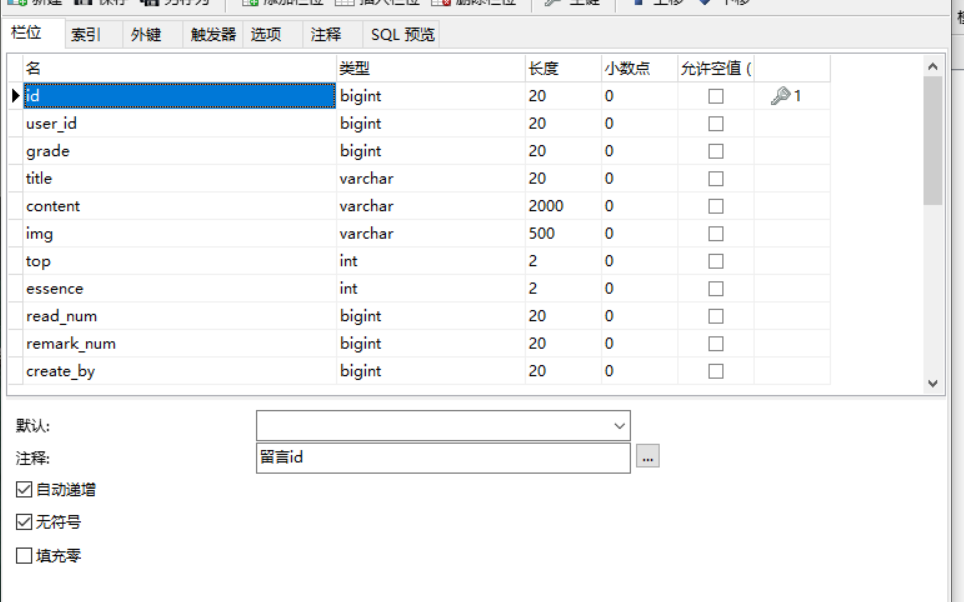
留言板card
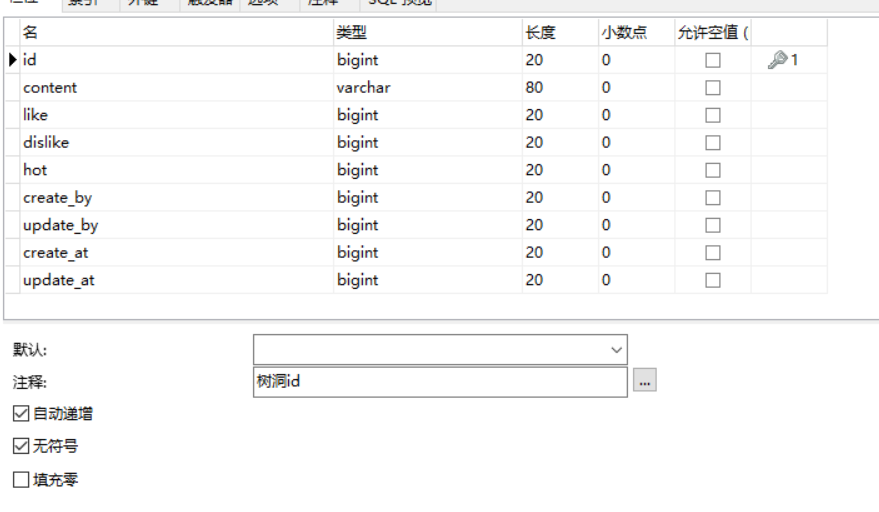
树洞表hole
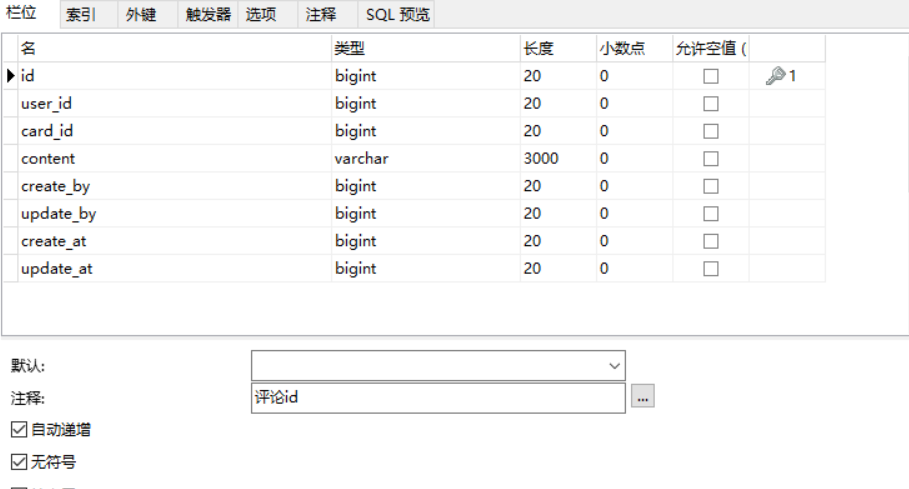
评论表remark
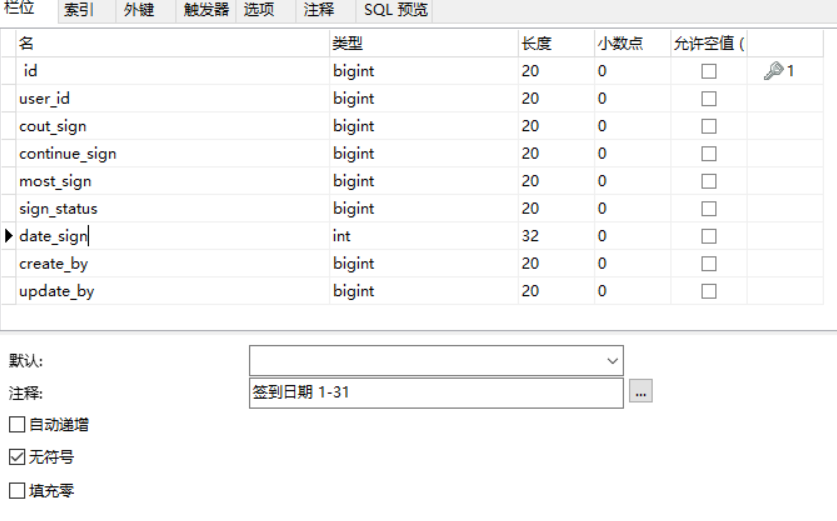
签到表signs
用户表user




评论