深度思考:
1.后台只允许有列表页和详情页,列表页分为搜索区和列表区和操作区,原因是什么?有没有其他设计方式,相比之下各自的好处是什么?
列表页 和 详情页 类似下图
列表页作用:
使管理员根据列表名称快速定位需要操作的业务,尽快完成操作。
搜索区的作用是在列表页无法找到业务的情况下,快速查找所需要操作的业务。
都是为了方便管理员快速找到需操作的业务,提高工作效率。
列表页设计原则:
第一条:根据场景提供展示的业务列。
第二条:产品新数据行能够便捷地看到。
第三条:操作宜少不宜多。
详情页作用:
起到业务展示的作用,并在其中涵盖着对具体业务的操作。
列表页和详情页的设计,是经过了相关产品、市场的重重考验,被证明了是行之有效的,很多公司网站后台管理系统都是这种设计方式。
2.什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
单机结构,集群,分布式概念:
单机结构:
所有的代码都放在一个项目中,这个项目部署在一台服务器上。整个项目所有的服务都由这台服务器提供。
缺点:处理能力有限,业务大量增长时,服务器就难顶了。
集群结构:
所有的代码都放在一个项目中,这个项目部署在N台服务器上,每个服务器都提供相同的服务。
通过负载均衡,让这些服务器一起处理请求。(可以通过负载均衡服务器(nginx)来做到)
优势:
集群结构的好处就是系统扩展非常容易。如果随着你们系统业务的发展,当前的系统又支撑不住了,那么给这个集群再增加节点就行了。(疯狂增加服务器)
问题:
当你的业务发展到一定程度的时候,你会发现一个问题——无论怎么增加节点,貌似整个集群性能的提升效果并不明显了。这时候,你就需要使用分布式结构了。
分布式结构:
将一个完整的系统,按照业务功能,拆分成一个个独立的子系统(如订单管理,商品管理,用户管理), 在分布式结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。
优势:
系统之间的耦合度大大降低,可以独立开发、独立部署、独立测试,系统与系统之间的边界非常明确,排错也变得相当容易,开发效率大大提升。
系统之间的耦合度降低,从而系统更易于扩展。我们可以针对性地扩展某些服务。假设这个商城要搞一次大促,下单量可能会大大提升,因此我们可以针对性地提升订单系统、产品系统的节点数量,而对于后台管理系统、数据分析系统而言,节点数量维持原有水平即可。
服务的复用性更高。比如,当我们将用户系统作为单独的服务后,该公司所有的产品都可以使用该系统作为用户系统,无需重复开发。
总结:
分布式:一个业务拆分为多个子业务,部署在多个服务器上 。
集群:同一个业务,部署在多个服务器上 。
集群:多个人在一起作同样的事 。
分布式 :多个人在一起作不同的事 。
缓存在什么情况下使用集群:
对于很少变化但是大量高并发读的数据,通过缓存集群来抗高并发读,防止数据库压力过大。
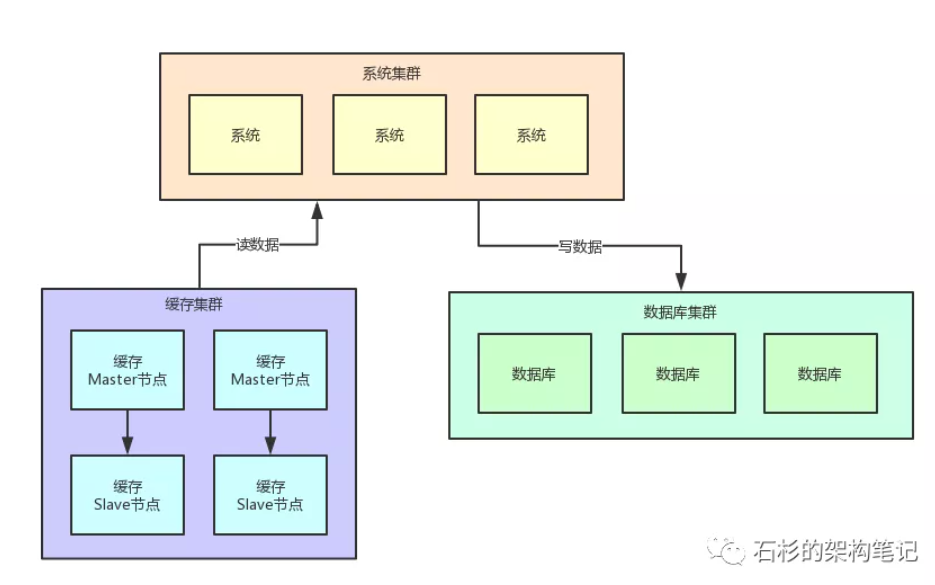
缺点: 碰到下面两种情况就GG,还需要使用热点缓存技术。
热key,就是你的缓存集群中的某个key瞬间被数万甚至十万的并发请求打爆。
大value,就是你的某个key对应的value可能有GB级的大小,导致查询value的时候导致网络相关的故障问题。
参考:https://blog.csdn.net/qq_28474017/article/details/97142604
实现集群方案:
1.客户端分片(client Sharding)
2.Twemproxy
3. Redis Cluster
4. Proxy+Redis Cluster
参考: https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247486494&idx=1&sn=f8bbe491a0569445e7fc065112361b33&source=41#wechat_redirect
3.什么是压测,为什么要进行压力测试?JMETER工具的使用
压力测试的分类:
性能测试:通过调整线程及并发数 查看在什么条件下能满足我们的具体业务需求
(在什么情况下 系统能在500ms返回)
负载测试: 通过不断增加线程数 和 事务数量(访问次数)来测量系统的负载,且都能正常运行。
压力测试: 超过增加预期负载,来查看系统崩溃时运行情况。
作用: 测验系统最大处理能力,找到程序崩溃的临界点,考察其功能极限及隐患
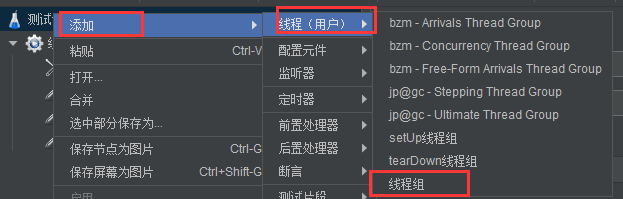
jmeter的使用(基础功能)
1.测试计划 右击-添加-线程-线程组
线程组 右击_添加-配置元件 -http请求默认器 (请求网址 和 端口 如www.baidu.com)
线程组 右击_添加-取样器-http请求 (请求网址的url后缀 如 /test /test2)
4.线程组 右击-添加-监听器- 聚合报告(可以选多个)
简单版:
badboy录制脚本 存储本地Jmx文件
jmeter直接打开本地Jmx文件,添加监听器即可
4.Memcache和Redis可否做集群?什么样的情况下应该做集群?
可以
memcache实现集群: repcached、memagent、 memcached-ha等。
redis实现集群:client Sharding、Twemproxy、Redis Cluster、Proxy+Redis Cluster
同上: 对于很少变化但是大量高并发读的数据,通过缓存集群来抗高并发读,防止数据库压力过大。
5.什么是脏数据,缓存中是否可能产生脏数据,如果出现脏数据该怎么处理?
脏数据: 从目标中取出的数据已经过期、错误或者没有意义,这种数据就叫做脏数据。
脏读:读取出来脏数据就叫脏读。
缓存中有可能产生脏数据。
比如用户A 对student表进行了删除操作,数据库数据更新了,缓存还没更新时。
用户B进行了查询操作,那么B取出的缓存是插入前的数据,那么就产生了脏数据。
如何处理脏数据:
1、主动更新:后台点击更新缓存按钮,从DB查找最新数据集合,删除原缓存数据,存储新数据到缓存(或者用定时任务来做)
问题:更新过程中删除掉缓存后刚好有业务在查询,那么这个时候返回的数据会是空,会影响用户体验,如果高并发穿透DB,可能导致服务器崩溃
2、由用户触发更新:前台获取数据时发现没有缓存数据就会去数据库同步数据到缓存
问题:当并发请求获取缓存数据不存在的时候,就会产生并发的查询数据的操作
3、提前加载好数据:后台点击更新缓存按钮,从DB查找最新数据集合,这里不删除缓存,通过遍历数据覆盖和删除掉无效的数据
问题:逻辑相对麻烦,而且更新机制无法通用
6.插入,更新和查询数据的时候,读写缓存和DB的顺序应该是怎么样的?
插入:
1.先插入DB
2.再查询缓存
3.如果有缓存 用查询出的结果来更新缓存。
4.如果没缓存,用查询出的结果新增缓存。
@Override
public int AddStudent(student student) {
logger.info("添加的数据为" + student);
//添加数据
studentMapper.AddStudent(student);
//刷新缓存
//取出增加所有学员后所有学生的缓存
List<student> rs = (List<student>) client.get("AllStudent");
logger.info("查看现有缓存值:" + rs);
//如果缓存不为空 更改缓存数据
if (rs != null) {
logger.info("缓存值不为空");
//更改缓存数据
try {
logger.info("开始更新缓存");
boolean state = client.replace("AllStudent", rs);
logger.info("更新缓存结果+"+state );
} catch (Exception e) {
logger.info("更改缓存值失败"+e.toString());
e.printStackTrace();
}
}else{
try {
logger.info("开始新增缓存");
boolean state = client.set("AllStudent",rs);
logger.info("新增缓存结果+"+state );
} catch (Exception e) {
logger.info("新增缓存值失败"+e.toString());
e.printStackTrace();
}
}
//返回刚刚插入用户的id
return student.getId();
}
更新:
1.先更新DB 2. 再删除缓存
产生脏数据的概率较小,但是会出现一致性的问题;若更新操作的时候,同时进行查询操作,若hit,则查询得到的数据是旧的数据。但是不会影响后面的查询。(代价较小)
@Override
public boolean PutStudent(student student) {
//需要更新的数据
logger.info("更改的数据为" + student);
//更新DB
boolean state = studentMapper.PutStudent(student);
//更新DB成功
if(state = true) {
logger.info("更改DB成功!");
//删除缓存
boolean Delstate = client.delete("AllStudent");
if(Delstate=true){
logger.info("删除缓存成功!");
return true;
}else{
//虽然删除缓存失败,但还是要返回正确的更改DB结果true
logger.info("删除缓存失败!");
return true;
}
}else {
logger.info("更改DB失败!");
return false;
}
}
查询数据库:
1.先获取缓存 有就返回缓存
2.没有缓存就去查询DB , 用查询出的数据再新建一个缓存值,返回数据
public List<student> FindAll() {
//取出所有学生的缓存
List<student> rs = (List<student>) client.get("JsonMem");
logger.info("查询出的缓存值为" + rs);
//如果缓存为空 返回缓存数据
if (rs != null) {
logger.info("缓存值不为空,现在返回缓存");
return rs;
} else {
//如果没有该条缓存,则从数据库里进行查询 再添加新缓存
logger.info("缓存为空,现在从数据库查询数据");
List<student> rss = studentMapper.FindAll();
logger.info("从数据库中查询处的数据为" + rss);
//把从数据库查出的的数据放进缓存
try {
boolean state = client.set("JsonMem", rss);
logger.info("添加新缓存的key为:AllStudent ========= value为" + rss);
logger.info("是否已经进缓存"+state);
} catch (Exception e) {
logger.info("添加新缓存失败");
e.printStackTrace();
}
return rss;
}
}
7.JVM缓存和Memcache这种缓存的区别在哪里?是否可以不使用Memcache,只用虚拟机内存做缓存?
JVM 缓存用的是虚拟机内存,Memcache缓存用的是系统内存
可以只用jvm作缓存,但是jvm内存有限,所以还是需要memcache来缓存。
8.缓存应该在Service里,还是应该存放在Controller里,为什么?
放在controller层
好处:可以单个Controller进行控制,每个controller中有各自对数据的键,以及缓存时间等
缺点: 每个controller需要写一份几乎一模一样的代码,增加代码量,很繁琐。
放在service层
好处: 统一管理,复用性高,controller层不需要理会数据是从缓存中获取还是从mysql中获取,controller完全解放出来了。
缺点:controller失去了对缓存的控制权。
综上所属: 放service层 ,可以减少controller代码量,方便缓存的复用。
9.什么叫穿透DB?什么情况下会发生,穿透DB后会发生什么事情?
当缓存失效时,容易出现高并发的查询DB,导致DB压力骤然上升,这种现象我们称之为缓存穿透。
会使数据库压力过大,引起数据库崩溃。
以下三种情况,都会引起穿透DB:
缓存穿透: 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
缓存雪崩,是指在某一个时间段,缓存集中过期失效。
产生雪崩的原因之一,比如马上就要到双十一零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
10.什么叫命中率?正常来讲,命中率应该控制在多少?
终端用户访问加速节点时,如果该节点有缓存住了要被访问的数据时就叫做命中,如果没有的话需要回原服务器取,就是没有命中。
命中率=命中数/(命中数+没有命中数), 缓存命中率是判断加速效果好坏的重要因素之一。
一个缓存失效机制和过期时间设计良好的系统,命中率应该达到95%以上
11.什么样的数据适合存在缓存中?缓存的淘汰算法有哪些?
那些访问量大的,变化比较小的,适合放在缓存中
最不经常使用算法(LFU)
最近最少使用算法(LRU)
自适应缓存替换算法(ARC)
先进先出算法(FIFO)
最近最常使用算法(MRU)
12.什么叫一致性哈希,通常用来解决什么问题?
在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用。
但是普通的余数hash(hash(比如用户id)%服务器机器数)算法伸缩性很差,当新增或者下线服务器机器时候,用户id与服务器的映射关系会大量失效。一致性hash则利用hash环对其进行了改进。
后面具体算法就难懂了... 明天再看看
参考:
https://www.jianshu.com/p/735a3d4789fc13.缓存的失效策略有哪几种,分别适合什么场景?
当缓存需要被清理时(比如空间占用已经接近临界值了),需要使用某种淘汰算法来决定清理掉哪些数据。常用的淘汰算法有下面几种:
1、FIFO:First In First Out,先进先出。判断被存储的时间,离目前最远的数据优先被淘汰。
2、LRU:Least Recently Used,最近最少使用。判断最近被使用的时间,目前最远的数据优先被淘汰。
3、LFU:Least Frequently Used,最不经常使用。在一段时间内,数据被使用次数最少的,优先被淘汰。
14.Memcache和Redis的区别是什么?
Redis 和 Memcache 都是基于内存的数据存储系统。
Memcached是高性能分布式内存缓存服务;Redis是一个开源的key-value存储系统。
区别:
1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等;
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储;
3、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘;
4、过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10;
5、分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从;
6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化);
7、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
8、Redis支持数据的备份,即master-slave模式的数据备份;
9、应用场景不一样:Redis出来作为NoSQL数据库使用外,还能用做消息队列、数据堆栈和数据缓存等;Memcached适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和session等。
15.怎么预估自己系统可承载的日活数?
用jmeter进行压力测试
在最大压力测试下保持的连接数,(接近崩溃) 就是网站可承载的最大日活。
在90%Line都在 500MS以下 ,就是网站可承载的最佳日活。
16.什么是JMeter?Jmeter是否可以在多台机器上分布式部署?为什么要分布式部署?
jmeter是 基于Java的压力测试工具,用于对软件做压力测试,
可以分布式部署。
在使用JMeter进行性能测试时,如果并发数比较大(比如,需要支持10000并发),单台电脑的配置(CPU和内存)可能无法支持,这时可以使用JMeter提供的分布式测试的功能,使多台机器同时产生负载的功能。
17.什么是TPS,什么是每秒并发数,什么是90%Line?分别应该到达多少算符合系统上线的要求?
TPS(Transactions Per Second)(每秒传输的事物处理个数,或者说每秒系统接收的任务数量) 是衡量系统性能的一个非常重要的指标. 同一时间段
每秒并发数: 系统同时处理的request/事务数 同一时间点
90%Line 测试出的10个数字 永远排在第9位的 就是90%Line
没啥人用的服务 tps 20/300ms就行了
十万到百万级的服务,响应能达到tps50 /200ms就可以了
后台服务,能达到tps 20 / 200ms即可(通常后台同时使用也没多少人)
秒杀类的短时间高并发……TPS100或200 在100ms内响应 (具体情况还是要看业务量)
修真院的要求是页面数据在200ms内返回, 90%Line在500ms以下。




评论