发表于: 2020-08-30 23:40:11
1 2176
今天完成的事情
1.梳理小程序后端登录注册流程
2.Java 内存模型
结合计算机硬件的一些工作机制来看的话可以很清晰的了解 JVM 为什么要这样设计,但是这一块我没法用自己的语言描述清楚。
3. 使用函数处理数据
每一个数据库管理系统支持的函数都不太一样,写法的差异也很大,没什么东西好写。
收获
1. 微信小程序的注册与登录
上面是微信文档给出的小程序登录流程,一个完整的登录或者注册需要多方参与。
微信小程序调用 wx.login 生成 code
在用户注册或者每次登录的时候都需要从这一个步骤开始,这个 code 的信息无法被开发者直接使用。
开发者服务器获取 code 信息
得到了用户端小程序传来的 code 之后需要开发者的服务器结合 appid 与 appsecret 获取到用户的唯一 openid(对于同一个小程序来说是唯一且不变的)与会话加密密钥 session_key。
openid 和 session_key 应该都要持久化。
对于开发者来说,一个 openid 就是一个用户,如果我们数据库内没有这个用户那么我们就需要走注册流程,否则我们就可以结合 session_key 进行下一步操作。
这里有一个词是【自定义登录态】我的理解是在完成了 openid 和 session_key 的获取之后,这时开发者服务器已经可以辨识用户的身份了,此时我们可以根据业务的需求来给用户分发一个 token 用于业务上的校验,这是开发者服务器在一个 session_key 生命周期内用来辨识用户身份的自定义标识。比如用户账户的激活与冻结或者获取数据的权限,这个时候就和常规的账号密码登录之后的处理方法一致了。
注册用户数据表的设计可以参照上次日报的那两张表的设计,在登陆表中插入 openid 和 session_key。
开发者服务器在获取到 openid 与 session_key 之后需要去数据库检索 openid 并且更新 session_key。
这里需要特别注意的是 session_key 过期时间是由微信决定的,且第三方无法推算,这里主要有两种解决方法:
a,开发者服务器向微信 api 获取数据的时候发现过期返回信息给用户提示重新登录
b,微信小程序端在每次登录的时候主动先校验 session_key 是否过期
这里还是选择在小程序端主动探测比较好,首先避免了开发者服务器做更多的校验逻辑,减少了无谓的网络通信耗时。其次小程序端主动探测到失效后立马提示用户重新登录的流程体验也更好。
(这个地方我有个疑问,session_key 会不会在用户打开小程序用到一半就失效了? 微信如果注重用户体验的话应该不会这样做,而且小程序目标就是用完即走,这样的话等到下一次登录微信再判定失效问题也不大)
2. Java 内存模型
JVM 内存模型分为 heap 与 stack。然而这个和硬件是没有关系的,stack 与 heap 的数据分布于硬件的内存与 CPU 的各级缓存中。
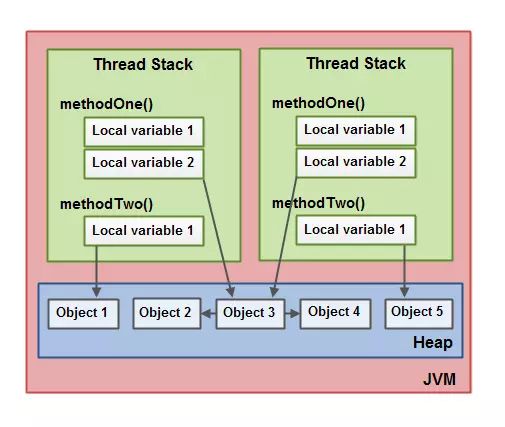
线程栈与堆上的数据分布满足以下条件:
- 一个本地变量可能是原始类型,在这种情况下,它总是“呆在”线程栈上。
- 一个本地变量也可能是指向一个对象的一个引用。在这种情况下,引用(这个本地变量)存放在线程栈上,但是对象本身存放在堆上。
- 一个对象可能包含方法,这些方法可能包含本地变量。这些本地变量仍然存放在线程栈上,即使这些方法所属的对象存放在堆上。
- 一个对象的成员变量可能随着这个对象自身存放在堆上。不管这个成员变量是原始类型还是引用类型。
- 静态成员变量跟随着类定义一起也存放在堆上。
- 存放在堆上的对象可以被所有持有对这个对象引用的线程访问。当一个线程可以访问一个对象时,它也可以访问这个对象的成员变量。如果两个线程同时调用同一个对象上的同一个方法,它们将会都访问这个对象的成员变量,但是每一个线程都拥有这个成员变量的私有拷贝。
然而我们都知道在实际的硬件中并不是这么回事,如果不谈文件的读取的话一个 Java 程序的数据可能位于内存、CPU 各级缓存与 CPU 寄存器中。现代计算机都是多核多线程,当我们运行一个多线程 Java 程序之后情况就变得更加复杂了。
多线程的数据交互需要经过以下步骤:
一:线程 A 把本地内存数据保存到主内存中
二:线程 B 去主内存读取线程 A 更新的数据
3. 同步代码块
在物理机中数据的分布方式与 Java 内存模型是有区别的,一个多线程类中全局变量 int 在 JVM 中只有一份,但是在硬件中这个变量除了在主内存中有一份,还会有很多副本存在于各种缓存。这就导致了开发者以为只有一份,但是实际上多个线程操作的是各自的副本,最终导致结果不符合预期。
如以下程序所示:

在这个程序中,我们预期的结果是 10000,但是实际上每次运行的结果都不一样。比如我运行的结果是:
9888产生这种现象是因为 ++n 这个操作并不是原子的,我们可以通过在 inc() 这个方法上加上 synchronized 关键字。这个自增方法内部就是一个同步代码块。所有使用这个方法的线程都要等待前面的线程执行完毕释放锁之后才能使用。这个时候再运行结果就是正常的了。
private static synchronized void inc() {
++n;
}
4. volatile
用实例代码来说明:
public class VolatileTest {
volatile long a = 1L; // 使用 volatile 声明 64 位的 long 型
public void set(long l) {
a = l; //单个 volatile 变量的写
}
public long get() {
return a; //单个 volatile 变量的读
}
public void getAndIncreament() {
a++; // 复合(多个) volatile 变量的读 /写
}
}
字段 a 使用了关键字 volatile 来定义,那么当多线程执行的时候相当于如下代码
public class VolatileTest {
long a = 1L; // 64 位的 long 型普通变量
public synchronized void set(long l) { //对单个普通变量的写用同一个锁同步
a = l;
}
public synchronized long get() { //对单个普通变量的读用同一个锁同步
return a;
}
public void getAndIncreament() { //普通方法调用
long temp = get(); //调用已同步的读方法
temp += 1L; //普通写操作
set(temp); //调用已同步的写方法
}
}
这意味着对于这个字段的读与写方法都是线程同步的,那么每一个线程在读的时候都能读到最新的内容。
但是 a++ 这种读写复合的操作却任然不具有原子性。




评论