发表于: 2020-08-24 23:43:22
1 2293
今天完成的事:
深度思考
1.什么是负载均衡,为什么要做负载均衡?
负载均衡就是使用nginx等代理服务器通过配置多台应用服务器,把用户的请求分摊到这些服务器上。
只配置一台服务器处理用户的请求,如果有多个用户试图同时访问,超出了服务器处理请求的极限,就会发生响应变慢或者根本无法连接的情况,或者因为意外因素这台服务器宕机了导致用户没法访问了。
而通过在后端引入一个负载均衡器和至少一个额外的 web 服务器,可以缓解这个故障。通常情况下,所有的后端服务器会保证提供相同的内容,以便用户无论哪个服务器响应,都能收到一致的内容。
2.为什么要使用memcache?memcache有什么作用?
memcache一般的使用目的是,通过缓存数据库查询的结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。 它是一个基于内存的“键值对”存储,用于存储数据库调用、API调用或页面引用结果的直接数据,如字符串、对象等。
3.后台只允许有列表页和详情页,列表页分为搜索区和列表区和操作区,原因是什么?有没有其他设计方式,相比之下各自的好处是什么?
原因是让用户更直观,更便捷的获取信息。
http://www.woshipm.com/pd/1202556.html
后台两种设计方式:需求驱动设计(RDD),领域驱动设计(DDD)。
需求驱动设计不足:面向过程设计,贫血模型
创建的对象不准确,直接影响产品和开发对业务的正确把握和扩展;
业务逻辑分散,业务难以复用;
业务间耦合度高,迭代及维护成本极高;
名词定义不一致,开发与业务出现沟通问题。
领域驱动设计:面向对象的设计方式,对上面的补充,相对复杂的设计模式。
RDD的模式会很快捷,这个就非常适合初创型、小型的系统设计,当产品复杂到一定程度时,RDD的开发时间会指数上升,而DDD的模式则始终比较平稳,所以DDD会适合复杂的系统设计。
4.什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
集群:单机处理到达瓶颈的时候,把单机复制几份,这样就构成了一个“集群”。集群中每台服务器就叫做这个集群的一个“节点”,所有节点构成了一个集群。每个节点都提供相同的服务,那么这样系统的处理能力就相当于提升了好几倍(有几个节点就相当于提升了这么多倍)。
在缓存里放一些平时不怎么变动的数据,然后用户在查询大量的平时不怎么变动的数据的时候,缓存集群的并发能力是很强的,而且读缓存的性能是很高的。举个例子,假设每秒有2万请求,但是其中90%都是读请求,那么每秒1.8万请求都是在读一些不太变化的数据,而不是写数据。
在网上搜索到的开源集群方案: NetFlix对Dynamo的开源通用实现Dynomite,Twitter的Redis/Memcached代理服务Twemproxy,豌豆荚的 Redis 集群解决方案Codis。
5.什么是压测,为什么要进行压力测试?JMETER工具的使用
压测,即压力测试,是确立系统稳定性的一种测试方法,通常在系统正常运行范围之外运行,以考察其功能的实现和隐患。
因为要确定系统的瓶颈来获得系统能提供的最大服务级别。
jemter工具有GUI,NO GUI两种使用方法,GUI就是在用户界面上选好取样器,监听器,线程组之类的jmeter组件后,点击运行按钮。
noGUI,先通过用户界面生成测试脚本,然后用命令行来执行测试脚本,jmeter -n -t c:\测试脚本.jmx -l c:\test.jtl
-n 非 GUI 模式 -> 在非 GUI 模式下运行 JMeter
-t 测试文件 -> 要运行的 JMeter 测试脚本文件
-l 日志文件 -> 记录结果的文件
应该使用noGUI模式,因为jmeter本身是个java可执行程序,运行起来占用很多系统资源,导致测试的结果不够准确。
6.Memcache和Redis可否做集群?什么样的情况下应该做集群?
可以,对系统的要求达到高并发和高可用的时候。
7.什么是脏数据,缓存中是否可能产生脏数据,如果出现脏数据该怎么处理?
脏数据:从目标中取出的数据已经过期,错误或者没有意义。还有在高并发下, 一个线程是更新操作, 另一个是查询操作,更新操作在删除缓存后, 查询操作没有命中缓存, 先把老数据读出来后放到了缓存, 然后更新操作更新了数据库.于是在缓存中的数据还是老数据, 导致缓存中的数据是脏的。
更新数据之前删除缓存。
8.插入,更新和查询数据的时候,读写缓存和DB的顺序应该是怎么样的?
查询:先查缓存有没有数据,没有就查DB。
更新操作:
1.先删除缓存再更新DB
结论:产生脏数据的概率较大(若出现脏数据,则意味着再不更新的情况下,查询得到的数据均为旧的数据)
比如:两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
2.先更新DB再删除缓存(使用场景多)
结论:产生脏数据的概率较小,但是会出现一致性的问题;若在更新操作的时候,同时进行查询操作,则查询得到的数据是旧的数据。但是不会影响后面的查询。(代价较小)
插入操作:https://www.cnblogs.com/cjjjj/p/12821959.html
一写(线程A)一读(线程B)操作,先操作数据库,再操作缓存。
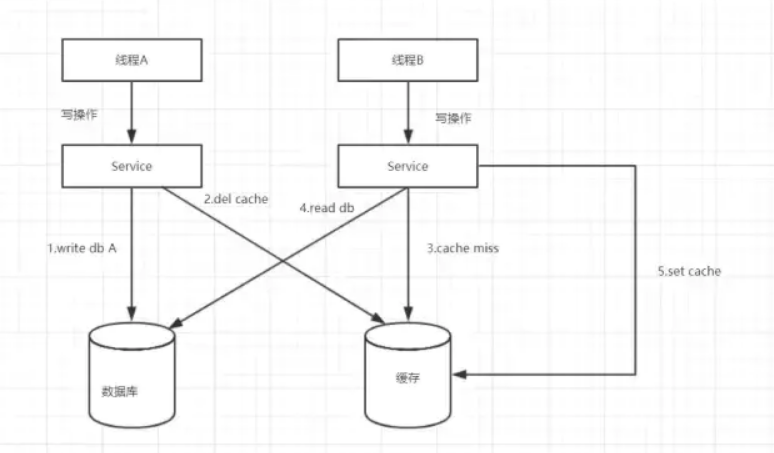
1)线程A发起一个写操作,第一步write DB
2)线程A第二步del cache
3)线程B发起一个读操作,cache miss
4)线程B从DB获取最新数据
5)线程B同时set cache
9.JVM缓存和Memcache这种缓存的区别在哪里?是否可以不使用Memcache,只用虚拟机内存做缓存?
JVM确保Heap区域内的空间足够,如果不够则使用触发GC在内的方法获得空间。
在 Memcached中可以保存的item数据量是没有限制的,只要内存足够 。
可以。
适用本地(JVM)缓存的场景:
1、对性能有非常高的要求。
2、不经常变化。
3、占用内存不大。
4、有访问整个集合的需求。
10.缓存应该在Service里,还是应该存放在Controller里,为什么?
放在Controller中:
好处:可以单个Controller进行控制,每个controller中有各自对数据的键,以及缓存时间等。
坏处:每个controller需要写一份几乎一模一样的代码,很繁琐。即使你写一个公共的方法,那也要在各个地方写上这个公共方法,属于重复工作了。
放在Service中:
好处:统一管理,复用性高,controller层不需要理会数据是从缓存中获取还是从mysql中获取,controller完全解放出来了。
坏处:没法对单个controller进行控制了,controller失去了对缓存的控制权。
11.什么叫穿透DB?什么情况下会发生,穿透DB后会发生什么事情?
用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。穿透DB后,DB会直接崩溃。
12.什么叫命中率?正常来讲,命中率应该控制在多少?
可以直接通过缓存拿到数据的比率。
95%以上。
13.什么样的数据适合存在缓存中?缓存的淘汰算法有哪些?
最不经常使用算法(LFU)
最近最少使用算法(LRU)
自适应缓存替换算法(ARC)
先进先出算法(FIFO)
最近最常使用算法(MRU)
那些访问量大的,变化比较小的数据,适合放在缓存中。
14.什么叫一致性哈希,通常用来解决什么问题?
一致性哈希是一种哈希算法,可以有效解决分布式存储下增加或删除节点所带来的问题。它和hash最关键的区别就是,对节点和数据,都做一次哈希运算,然后比较节点和数据的哈希值,数据取和节点最相近的节点做为存放节点。这样就保证当节点增加或者减少的时候,影响的数据最少。
15.缓存的失效策略有哪几种,分别适合什么场景?
FIFO:First In First Out,先进先出。判断被存储的时间,离目前最远的数据优先被淘汰。
LRU:Least Recently Used,最近最少使用。判断最近被使用的时间,目前最远的数据优先被淘汰。
LFU:Least Frequently Used,最不经常使用。在一段时间内,数据被使用次数最少的,优先被淘汰。
16.Memcache和Redis的区别是什么?
数据类型
Redis支持的数据类型要丰富得多,Redis不仅仅支持简单的k/v类型的数据,同时还提供String,List,Set,Hash,Sorted Set,pub/sub,Transactions数据结构的存储。其中Set是HashMap实现的,value永远为null而已
memcache支持简单数据类型,需要客户端自己处理复杂对象
持久性
redis支持数据落地持久化存储,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
memcache不支持数据持久存储
分布式存储
redis支持master-slave复制模式
memcache可以使用一致性hash做分布式
value大小不同
memcache是一个内存缓存,key的长度小于250字符,单个item存储要小于1M,不适合虚拟机使用
数据一致性不同
Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起Memcached,还是稍有逊色。
redis使用的是单线程模型,保证了数据按顺序提交。
memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作
cpu利用
redis单线程模型只能使用一个cpu,可以开启多个redis进程
17.怎么预估自己系统可承载的日活数?
进行压力测试,查看异常率,响应时间,tps,90%line线这些数据进行综合评估。
18.什么是JMeter?Jmeter是否可以在多台机器上分布式部署?为什么要分布式部署?
Apache JMeter是Apache组织开发的基于Java的压力测试工具。
在使用Jmeter进行接口的性能测试时,由于Jmeter 是JAVA应用,对于CPU和内存的消耗比较大,所以,当需要模拟数以万计的并发用户时,使用单台机器模拟所有的并发用户就有些力不从心,甚至会引起JAVA内存溢出错误。为了让jmeter工具提供更大的负载能力,这时可以使用Jmeter提供的分布式功能来启动多台电脑来分压测试。
19.什么是TPS,什么是每秒并发数,什么是90%Line?分别应该到达多少算符合系统上线的要求?
Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。
TPS包括一条消息入和一条消息出,加上一次用户数据库访问。
每秒并发数:系统可以在一秒内同时处理多少数量的请求。
90%Line:90%的用户请求响应时间不超过某个值。
明天的计划:
给出一份完整的压测报告。
开始任务七。
遇到的问题:
好多题都不在自己的所了解的知识范围里,只能通过百度了解一切肤浅的概念。
收获:
了解缓存的表层概念。




评论