发表于: 2020-07-31 22:42:52
1 2145
今天完成的事:
深度思考:
1.什么是rmi?为什么要使用rmi框架?
RMI(Remote Method Invocation)远程方法调用是一种计算机之间利用远程对象互相调用实现双方通讯的一种通讯机制。使用这种机制,某一台计算机上的对象可以调用另外 一台计算机上的对象来获取远程数据。
RMI大大增强的了Java开发分布式应用的能力,Java RMI支持存储在不同服务器中的程序中的对象之间的互相调用,它允许一个Java虚拟机上的对象调用运行在另一个Java虚拟机上的对象的方法,从而使开发人员可以方便的在网络环境中做分布式运算。
2.部署两台Service,如何在WEB中随机访问任意一台Service?
可以使用Java中的Random类,
Random random = new Random();
random.nextInt(2);
3.RMI的简单介绍
RMI(Remote Method Invocation)远程方法调用是一种计算机之间利用远程对象互相调用实现双方通讯的一种通讯机制。使用这种机制,某一台计算机上的对象可以调用另外 一台计算机上的对象来获取远程数据。
使用RMI开发步骤:
1、定义一个远程接口(远程接口必须继承接口,每个方法必须抛出远程异常,方法参数和方法返回值都必须是可序列化的)
2、实现远程接口
3、定义使用远程对象的客户程序
4、产生远程访问对象的桩和框
5、注册远程对象
6、运行服务器和客户程序
4.什么是RMI,什么是RPC,两者之间的区别是什么?
RPC 的全称是 Remote Procedure Call 是一种进程间通信方式。 它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。 即程序员无论是调用本地的还是远程的,本质上编写的调用代码基本相同。
区别
1、方法调用的方式不同
RMI调用方法是通过在客户端的Stub对象作为远程接口进行远程方法的调用。每个远程方法都具有方法签名。如果一个方法在服务器上执行,但是没有相匹配的签名被添加到这个远程接口(Stub对象)上,那么这个新方法就不能被RMI客户方所调用。简单理解就是,远程方法需要先在远程接口上注册才能使用。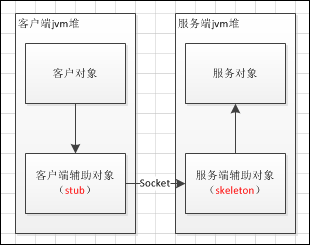
RPC调用函数是通过网络服务协议向远程主机发送请求,请求包含了一个参数集和一个文本值,通常形成【classname.*methodname(参数集)】的形式。这就向RPC服务器表明了,被请求的方法是在classname类中,方法名是methodname。然后RPC服务器就会去搜索与之相匹配的类和方法,并把它作为方法参数类型的输入。这里的参数类型是与PRC请求中的类型相匹配的,一旦匹配成功,这个方法就被调用了,并会将执行结果编码后通过网络协议发回。
2、适用的语言范围不同
RMI只适用Java并支持传输对象
RPC是基于C语言的,是网络服务的协议,与操作系统和语言无关(跨语言),不支持传输对象
3、调用结果的返回形式不同
因为Java是面向对象的,所以RMI也是面向对象的,RMI调用结果可以是对象类型或者是基本数据类型
RPC的返回结果统一由外部数据表示(External Data Representation, XDR) 语言表示, 这种语言抽象了字节序类和数据类型结构之间的差异。只有由 XDR 定义的数据类型才能被传递, 可以说 RMI 是面向对象方式的 Java RPC 。
5.Service和Service之间可以互相调用吗?是应该统一Controller调用Service,还是应该Service调用Service?
可以互相调用,但是不建议这样操作,会增加耦合性,同一层级之间最好不要耦合,比如maven项目中a层的service调用b层的service,那么一定要先启动b层的service,不然a启动就会报错,但是b层的service出了问题,a也会误以为没错。如果a和b互相调用,那么这时该先启动a还是b就是个问题了。
统一Controller调用比较好
6.Service对外暴露的接口粒度应该是怎么样的,是只提供基础的CRUD服务,还是应该将业务逻辑包含进去?
Service对外暴露的接口只提供crud服务比较好,业务逻辑可以写在Service实现类里面
7.Thrift,Protobuffer分别是什么,一般用于什么场景?
Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。
Protocol Buffers 是Google开源的,一种灵活、高效、用于序列化结构化数据的自动化过程。你只需要定义如何组织你的结构化数据一次,然后就可以使用protoc轻松的根据这个定义生成语言相关的源代码(支持多种语言),以便于读写结构化数据。
下面对比一下这两个的区别。参考:http://zhidao.baidu.com/link?url=yNLBeHhWokfwB677UZHoyv4vLyPOZEEQypUMiX__YIhp5E7UmpvIWTArKPMab32xj5gkRo4a6CXoZ1nxore82kXyOzfXdaRRhOAPynxYmB7
1)Thrift: 支持的语言更广泛一些c++, java, python,ruby, csharp, haskell, ocmal, erlang, cocoa, php
protobuf 目前还是只支持c++, java, python
2)Thrift提供的功能更丰富一些: Thrift提供了简单的RPC构架(其实不简单了, block, nonblock的都有了…..)
protobuf好像一心一意做好自己的事情,只提供了序列化和反序列化的功能。
3)Thrift支持多种协议格式. Thrift的代码实现,有专门的TProtocol和TTransport抽象,相互配合,可以实现多种协议,方便集成各种传输方式。至少目前Thrift就能使用json作为序列化协议。
protobuf只安心一种协议,并下决心把这个格式做好。输入输出也是标准的stream.
4)thrift目前不支持Windows平台
protobuf没有这个问题,提供了visual studio的项目文件,可以很顺利的在windows平台下编译。
5)thrift侧重点是构建夸语言的可伸缩的服务,特点就是支持的语言多,同时提供了完整的rpc service framework,可以很方便的直接构建服务,不需要做太多其他的工作。
相同点:
数据类型相对固定的情况下,不论是thrift还是protobuf都会比直接处理xml要方便很多。
Thrift和Protobuf的最大不同,在于Thrift提供了完整的RPC支持,包含了Server/Client,而Protobuf只包括了stub的生成器和格式定义。
8.什么是序列化和反序列化,在RMI中是否要实现 Serializable 接口, serialVersionUID的用处是什么?
内存中的数据对象只有转化为二进制流才可以进行数据持久化和网络传输。将数据转化为二进制的过程称为对象的序列化。 反之,将二进制流恢复为数据对象的过程称之反序列化。序列化需要保留充分的信息以恢复数据对象,但是为了节约存储空间和网络带宽,序列化后的二进制流又要尽可能的小。
RMI中需要实现Serializable接口
看了之前师兄小课堂关于serialVersionUID的用处:
序列化uid是用来确定序列化版本的,当反序列化的时候回根据类的uid转换会对象,如果uid对应不上会出现异常
修改了对象以后是否要修改uid?
如果是不兼容性修改,需要修改uid,如果是兼容性的修改则不能修改uid
9.Controller通过RMI调用服务是否有延迟?10条Long型的ID循环调用1000次,和本地调用之间的时间相差多少?
如果通过本地调用远程会有网络延迟的问题,如果只是查数据,通过可以考虑使用缓存
明天计划的事:学习SpringBoot
遇到的困难:
收获:




评论