发表于: 2020-07-11 23:30:59
1 1395
今天完成的事:
配置nginx,实现负载均衡

这里我用的resin和tomcat
将项目部署到Linux上,移动到各自的webapp文件夹下
开启memcached,运行jmeter进行压测
加入缓存的


关闭memcached,没有缓存后
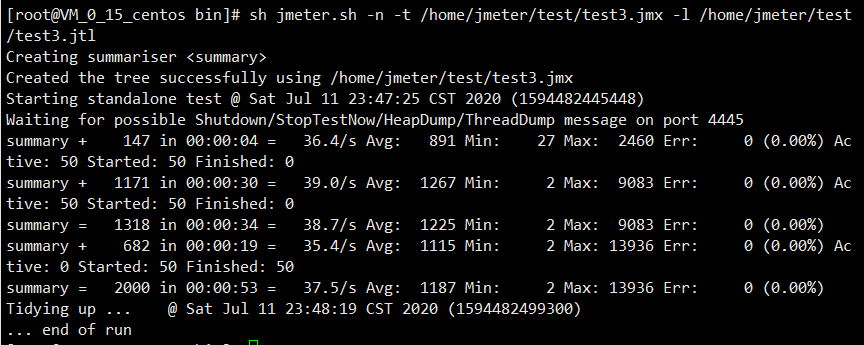

可以看出吞吐量直接从334/s多降到了37.7,和我昨天在本地测试的结果一样,差距十分明显
关于缓存穿透,缓存击穿和缓存雪崩
缓存穿透:
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
1、接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2、从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
缓存击穿:
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
1、设置热点数据永远不过期。
2、加互斥锁,互斥锁
缓存雪崩:
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
设置热点数据永远不过期。
关于redis的过期策略
我们知道很多时候服务器经常会用到redis作为缓存,有很多数据都是临时缓存一下,可能用过之后很久都不会再用到了(比如暂存session,又或者只存放日行情股票数据)那么就会出现一下几个问题了
1、Redis会自己回收清理不用的数据吗?
2、如果能,那如何配置?
3、如果不能,如何防止数据累加后大量占用存储空间的问题?
有一个需求场景,需要清空一些存放在Redis的数据,主要是通过一些时间进行过滤,删除那些不满足的数据,但是这样的工作每天都需要进行,那工作量就比较大了,而且每天都需要按时去手动清理,这样做也不切实际。
Redis中有个设置时间过期的功能,即对存储在Redis数据库中的值可以设置一个过期时间。作为一个缓存数据库,这是非常实用的。这就是我们要讲到的Redis过期机制。其实这个机制运用的场景十分广泛,比如我们一般项目中的token或者一些登录信息,尤其是短信验证码都是有时间限制的,或者是限制请求次数,如果按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
1、设置过期时间
Redis对存储值的过期处理实际上是针对该值的键(key)处理的,即时间的设置也是设置key的有效时间。Expires字典保存了所有键的过期时间,Expires也被称为过期字段。
expire key time(以秒为单位)--这是最常用的方式
setex(String key, int seconds, String value)--字符串独有的方式
注:
1、除了字符串自己独有设置过期时间的方法外,其他方法都需要依靠expire方法来设置时间
2、如果没有设置时间,那缓存就是永不过期
3、如果设置了过期时间,之后又想让缓存永不过期,使用persist key
一般主要包括4种处理过期方,其中expire都是以秒为单位,pexpire都是以毫秒为单位的。
1 EXPIRE key seconds //将key的生存时间设置为ttl秒
2 PEXPIRE key milliseconds //将key的生成时间设置为ttl毫秒
3 EXPIREAT key timestamp //将key的过期时间设置为timestamp所代表的的秒数的时间戳
4 PEXPIREAT key milliseconds-timestamp //将key的过期时间设置为timestamp所代表的的毫秒数的时间戳
2、3种过期策略
定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:
若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
没人用
惰性删除
含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
定期删除
含义:每隔一段时间执行一次删除(在redis.conf配置文件设置hz,1s刷新的频率)过期key操作
优点:
通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点
定期删除过期key--处理"惰性删除"的缺点
缺点
在内存友好方面,不如"定时删除"
在CPU时间友好方面,不如"惰性删除"
难点
合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
看完上面三种策略后可以得出以下结论:
定时删除和定期删除为主动删除:Redis会定期主动淘汰一批已过去的key
惰性删除为被动删除:用到的时候才会去检验key是不是已过期,过期就删除
惰性删除为redis服务器内置策略
定期删除可以通过:
第一、配置redis.conf 的hz选项,默认为10 (即1秒执行10次,100ms一次,值越大说明刷新频率越快,最Redis性能损耗也越大)
第二、配置redis.conf的maxmemory最大值,当已用内存超过maxmemory限定时,就会触发主动清理策略
注意:
上边所说的数据库指的是内存数据库,默认情况下每一台redis服务器有16个数据库(关于数据库的设置,看下边代码),默认使用0号数据库,所有的操作都是对0号数据库的操作,关于redis数据库的存储结构,查看 第八章 Redis数据库结构与读写原理
# 设置数据库数量。默认为16个库,默认使用DB 0,可以使用"select 1"来选择一号数据库
# 注意:由于默认使用0号数据库,那么我们所做的所有的缓存操作都存在0号数据库上,
# 当你在1号数据库上去查找的时候,就查不到之前set过得缓存
# 若想将0号数据库上的缓存移动到1号数据库,可以使用"move key 1"
databases 16
memcached只是用了惰性删除,而Redis同时使用了惰性删除与定期删除,这也是二者的一个不同点(可以看做是redis优于memcached的一点)
对于惰性删除而言,并不是只有获取key的时候才会检查key是否过期,在某些设置key的方法上也会检查(eg.setnx key2 value2:该方法类似于memcached的add方法,如果设置的key2已经存在,那么该方法返回false,什么都不做;如果设置的key2不存在,那么该方法设置缓存key2-value2。假设调用此方法的时候,发现redis中已经存在了key2,但是该key2已经过期了,如果此时不执行删除操作的话,setnx方法将会直接返回false,也就是说此时并没有重新设置key2-value2成功,所以对于一定要在setnx执行之前,对key2进行过期检查)
3、redis采用的过期策略
惰性删除+定期删除
惰性删除流程
在进行get或setnx等操作时,先检查key是否过期,
若过期,删除key,然后执行相应操作;
若没过期,直接执行相应操作
定期删除流程(简单而言,对指定个数个库的每一个库随机删除小于等于指定个数个过期key)
遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。
在redis整合ssm框架中,我们设置过期时间的具体操作写了一个简单的例子
@Controller
public class Test {
@Resource
MemCachedClient memCachedClient;
@RequestMapping("/n")
@ResponseBody
public String MapBmb() {
String a = "ss=1";
String t = (String) memCachedClient.get("test1");
System.out.println("===="+t);
if(t != null){
System.out.println("memcached执行了");
}else {
memCachedClient.add("test1",a);
System.out.println(a);
}
return "vvvvv";
}
}
测试结果,可以看到时间到后,缓存中的数据就没了

今天在部署项目的时候遇到resin关于webapp头文件不支持的情况,真是头大
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee
http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
非得写下面这个才支持,也是看了师兄之前的文件才发现的,任务二的时候使用resin也碰到过,后面忘了记录,搞了好一会儿,哎
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0" metadata-complete="false">
关于redis的多实例化------实现主从配置
可以参考下这篇博客
明天计划的事:提交任务代码,做深度思考
遇到的困难;
收获:




评论