发表于: 2020-07-07 22:37:03
1 2063
今天完成的事情:
任务小结:
任务六一共耗时6天(7.1-7.6)
主要是通过Jmeter工具来进行压力测试,学习Memcached和Redis的使用,理解缓存的概念,学习使用nginx来进行负载均衡。
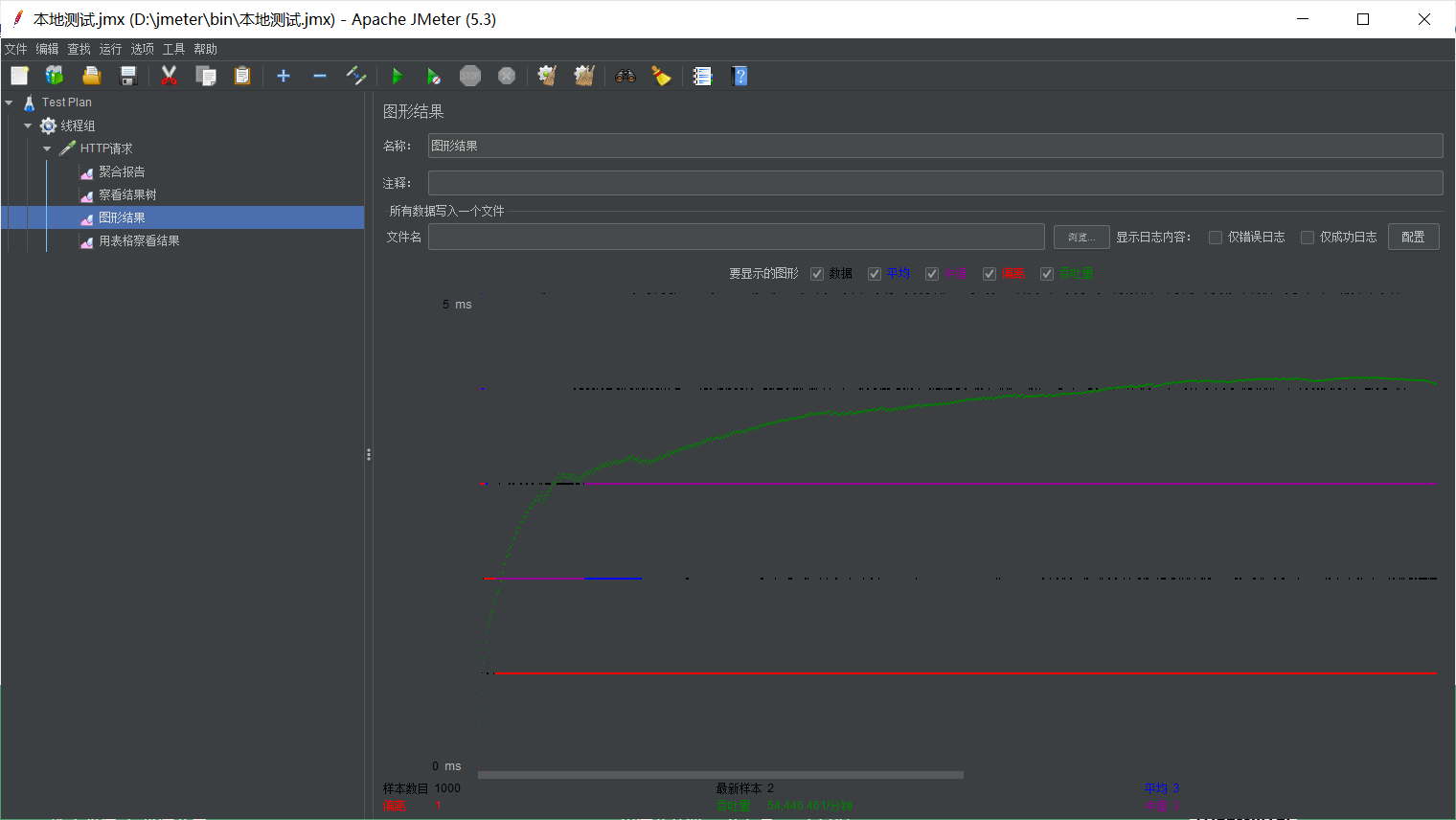
整理了一下之前测试的结果:
不开memcached,tomcat:

平均139毫秒,吞吐量131
打开memcached,tomcat:

平均15毫秒,吞吐量321
不开memcached,resin:

平均110毫秒,吞吐量154
打开memcached,resin:

平均6毫秒,吞吐量858
使用nginx负载均衡:

平均25毫秒,吞吐量471
使用Redis:
本地:

平均3毫秒,吞吐量907,速度比Memcached快很多,吞吐量也大了许多。
服务器端:

平均30毫秒,吞吐量420.
深度思考:
1.为什么要使用memcache?memcache有什么作用?
使用MemCache可以减轻数据库的压力,它能在内存中缓存数据和对象来减少读取数据库的次数,从而提高网站访问的速度。
2.什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
所谓集群是指一组独立的计算机系统构成的一个松耦合的多处理器系统,它们之间通过网络实现进程间的通信。应用程序可以通过网络共享内存进行消息传送,实现分布式计算机。通俗一点来说,就是让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份。
使用缓存集群的时候,最怕的就是热key、大value这两种情况,那啥叫热key大value呢?
简单来说,热key,就是你的缓存集群中的某个key瞬间被数万甚至十万的并发请求打爆。大value,就是你的某个key对应的value可能有GB级的大小,导致查询value的时候导致网络相关的故障问题。
常用的集群又分以下几种:
load balance cluster(负载均衡集群)
High availability cluster(高可用集群)
(双机热备)
(双机双工)
(双机互备)
high computing clustering(高性能计算集群)
3.什么是压测,为什么要进行压力测试?
压力测试是通过不断向被测系统施加“压力”,测试系统在压力情况下的性能表现,考察当前软硬件环境下系统所能承受的最大负荷并帮助找出系统瓶颈所在,也就是我们可以模拟巨大的工作负荷以查看应用程序在峰值使用情况下如何执行操作。 为什么要进行压力测试? 压力测试其实有两个目的,一是测试应用在高并发情况下是否会报错,进程是否会挂掉; 二是测试应用的抗压能力,预估应用的承载能力,为后面的运维提供扩容的依据。
4.什么是脏数据,缓存中是否可能产生脏数据,如果出现脏数据该怎么处理?
从目标中取出的数据已经过期、错误或者没有意义,这种数据就叫做脏数据。
解决办法:
写部分:
if(redis存在数据){
读取redis数据
}else{
数据库读取,同时存redis+设置超时时间
更新部分:
if(数据库update){
更新redis+设置超时时间
5.插入,更新和查询数据的时候,读写缓存和DB的顺序应该是怎么样的?
插入,更新的时候先更新DB再读写缓存。查询时先读写缓存再查询DB。
6.缓存应该在Service里,还是应该存放在Controller里,为什么?
这个我查了一下,好像各种情况都有,根据项目实际情况,项目规模、前后端框架、代码复杂程度来决定。一般持久层讲究和业务低耦合,脱离业务不受太多影响,所以建议放业务层比较合适。
7.什么叫穿透DB?什么情况下会发生,穿透DB后会发生什么事情?
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,会导致数据库压力过大。
8.什么叫命中率?正常来讲,命中率应该控制在多少?
命中率=从缓存中读取数据的次数/所有访问数据次数(磁盘读取次数+缓存读取次数)
读盘总量/客户机上机总时长*(100%-缓存命中率)≤存放游戏磁盘的随机读取速度。
如果结果是这样的,那么这个命中率就不低,如果结果是相反的,那么说明命中率确实低了。
读盘总量:是系统虚拟盘控制台上的一个数据,可以直接在控制台上看到。
客户机上机总时长:可以通过计费软件来统计,Pubwin可以在营业报表中看到这项统计。
缓存命中率:就是游戏虚拟盘控制台上的显示内容了。
9.什么样的数据适合存在缓存中?缓存的淘汰算法有哪些?
数据量不大,访问频率高,数据更改频率低的数据适合存在缓存中。缓存的淘汰算法常见类型包括LFU、LRU、ARC、FIFO、MRU。
10.缓存的失效策略有哪几种,分别适合什么场景?
1.FIFO(First In First out):先见先出,淘汰最先近来的页面,新进来的页面最迟被淘汰,完全符合队列。
2.LRU(Least recently used):最近最少使用,淘汰最近不使用的页面
3.LFU(Least frequently used): 最近使用次数最少, 淘汰使用次数最少的页面
11.Memcache和Redis的区别是什么?
1、 Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等。
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4、过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
5、分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
7、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8、Redis支持数据的备份,即master-slave模式的数据备份。
12.怎么预估自己系统可承载的日活数?
在预测系统的QPS前,我们需要有一些已知的经验型数据,如日志QPS在6-10w、 RPC的QPS在 10W ,Redis的QPS是8-10w,MySQL大致6k-1W。以上是大体范围,不同机器不同配置有不同结果。
抛开其他的不谈,我们需要看看,我们一次请求调用,有多少次写日志、多少次读写底层资源、多少次RPC调用,然后取其中最低的个值,这是我们预测系统能够达到的最大值。
13.什么是JMeter?Jmeter是否可以在多台机器上分布式部署?为什么要分布式部署?
JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它可以在多台机器上分布式部署。如果项目要求大并发去压测服务端的话,jmeter单节点难以完成大并发的请求,这时就需要对jmeter进行分布式测试。
14.什么是TPS,什么是每秒并发数,什么是90%Line?分别应该到达多少算符合系统上线的要求?
Transactions Per Second(每秒传输的事物处理个数,或者说每秒系统接收的任务数量),系统接收到任务后会有一个处理时间。
在压力测试时,测试人员会主动按一定tps的量来主动发起接口请求,比如tps=50,就是每秒请求50次,获取一个平均的响应时间(单位一般都是毫秒ms)。压力测试人员口中的TPS50 200ms返回,就是指每秒测试人员主动发起50次请求,这些请求会在平均200ms返回。
由于其他技术指标如QPS(数据的每秒查询个数)等性能都会在tps这个维度上展示出来,因此可通过tps对系统性能进行简单判断,以满足日常性能测试需求。
一般来说:
没啥人用的服务 tps 20,返回有300ms就行了
十万到百万级的服务,响应能达到tps50 /200ms就可以了
后台服务,能达到tps 20 / 200ms即可(通常后台同时使用也没多少人)
秒杀类的短时间高并发……TPS100或200 在 100ms内响应
明天计划完成的事情:
开始任务七




评论