发表于: 2020-07-06 23:36:10
1 2077
今天完成的事情:
将原来的Memcached替换成Redis:
package com.jnshu.service;
import com.jnshu.dao.StudentMapper;
import com.jnshu.pojo.Student;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class StudentServiceImpl implements StudentService {
@Autowired private StudentMapper studentMapper;
@Autowired
private RedisTemplate redisTemplate;
@Override
public int deleteByPrimaryKey(Long id) {
return studentMapper.deleteByPrimaryKey(id);
}
@Override
public int insert(Student record) {
return studentMapper.insert(record);
}
@Override
public Student selectByPrimaryKey(Long id) {
return studentMapper.selectByPrimaryKey(id);
}
@Override
public List<Student> selectStudent() {
List<Student> list = (List<Student>) redisTemplate.opsForValue().get("GoodStudent");
if(list != null){
System.out.println("从Redis查询的。。。。");
}else{
list = studentMapper.selectStudent();
redisTemplate.opsForValue().set("GoodStudent", list);
System.out.println("从数据库查询的。。。。");
}
return list;
}
@Override
public int selectByLearning() {
int i = 0;
if(redisTemplate.opsForValue().get("LearningStudent") != null){
System.out.println("从Redis中查询的。。。");
i =(int)redisTemplate.opsForValue().get("LearningStudent");
}else{
System.out.println("从数据库中查询的。。。");
i = studentMapper.selectByLearning();
redisTemplate.opsForValue().set("LearningStudent",i);
}
return i;
}
@Override
public int selectByWorking() {
int i = 0;
if(redisTemplate.opsForValue().get("WorkingStudent") != null){
System.out.println("从Redis中查询的。。。");
i =(int)redisTemplate.opsForValue().get("WorkingStudent");
}else{
System.out.println("从数据库中查询的。。。");
i = studentMapper.selectByWorking();
redisTemplate.opsForValue().set("WorkingStudent",i);
}
return i;
}
@Override
public int updateByPrimaryKeySelective(Student record) {
return studentMapper.updateByPrimaryKeySelective(record);
}
}
测试一下:


这里有一点要注意一下,往redis中存对象和list时要设置一下序列化方法,不然会报错:
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="connectionFactory" ref="connectionFactory"/>
<!-- 将键值序列化 如果不配置Serializer,那么存储的时候智能使用String,如果用User类型存储,那么会提示错误User can't cast to String -->
<!-- key 使用StringRedisSerializer 序列化-->
<property name="keySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer"/>
</property>
<!-- value 使用JdkSerializationRedisSerializer 序列化-->
<property name="valueSerializer">
<bean class="org.springframework.data.redis.serializer.JdkSerializationRedisSerializer"/>
</property>
</bean>
进行压力测试,还是20并发,循环50次:

平均3毫秒,吞吐量907,速度比Memcached快很多,吞吐量也大了许多。
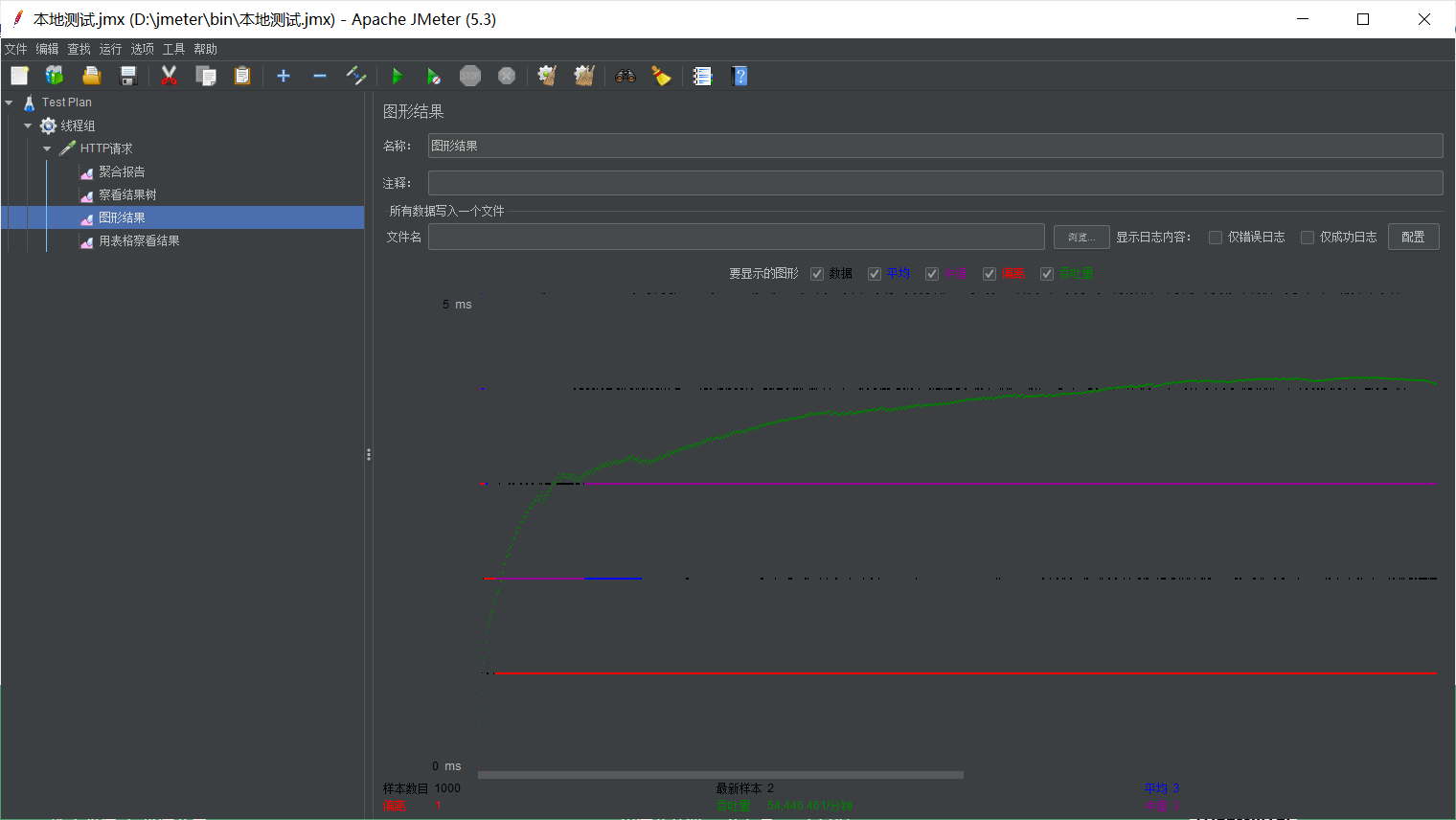
最后部署到服务器测试:
20线程循环50次:

平均30毫秒,吞吐量420.
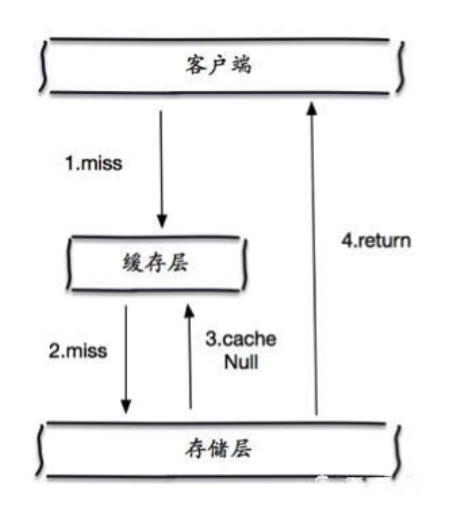
缓存穿透:
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存和数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
Nginx实现负载均衡的方式有多个:
轮询 (默认):每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除.
upstream backserver {
server 192.168.0.14;
server 192.168.0.15;
}weight:指定轮询几率, weight和访问比率成正比, 用于后端服务器性能不均的情况. 权重越, 在被访问的概率越大。
upstream backserver {
server 192.168.0.14;
server 192.168.0.15;
}
ip_hash:
上述方式存在一个问题就是说, 在负载均衡系统中, 假如用户在某台服务器上登录了, 那么该用户第二次请求的时候, 因为我们是负载均衡系统, 每次请求都会重新定位到服务器集群中的某一个, 那么已经登录某一个服务器的用户再重新定位到另一个服务器, 其登录信息将会丢失, 这样显然是不妥的.
我们可以采用ip_hash指令解决这个问题, 如果客户已经访问了某个服务器, 当用户再次访问时, 会将该请求通过哈希算法, 自动定位到该服务器.
每个请求按访问ip的hash结果分配, 这样每个访客固定访问一个后端服务器, 可以解决session的问题.
upstream backserver {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
}fair (第三方):按后端服务器的响应时间来分配请求, 响应时间短的优先分配.
upstream backserver {
server server1;
server server2;
fair;
}url_hash (第三方):按访问url的hash结果来分配请求, 使每个url定向到同一个后端服务器, 后端服务器为缓存时比较有效.
upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}任务六差不多做完了。
收获:
学会了在java中整合redis,了解了缓存穿透和缓存击穿,了解了nginx分发请求的规则。
明天计划完成的事情:
深度思考,开始任务七




评论