发表于: 2020-07-04 23:10:02
1 1808
任务六深度思考
1.后台只允许有列表页和详情页,列表页分为搜索区和列表区和操作区,原因是什么?有没有其他设计方式,相比之下各自的好处是什么?
列表页可以让管理人员快速找到自己需要的功能,不用一个个点开去查看。一个完整的列表页,主体是列表,包含一些对列表的操作,以及搜索。
搜索主要的目的是找到自己想要的功能,即对应的列表选项。
详情页面展示了一个类目下的所有操作,让操作人员不需要切换页面就可以完成操作。
2.什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
计算机集群(英語:computer cluster)是一组松散或紧密连接在一起工作的计算机。 由于这些计算机协同工作,在许多方面它们可以被视为单个系统。 与网格计算机不同,计算机集群将每个节点设置为执行相同的任务,由软件控制和调度。
即多台服务器执行同一个任务,当其中某个服务器宕机之后其他的服务器可以支持业务继续进行。比如后端的负载均衡。
集群使用场景:后端负载均衡、缓存集群、数据库集群
实现方案:
通过代理(nginx)的 upstream
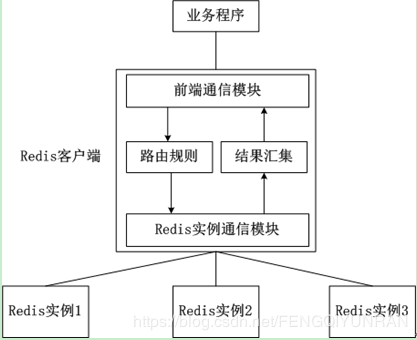
客户端分片:客户端分片是把分片的逻辑放在Redis客户端实现,通过Redis客户端预先定义好的路由规则,把对Key的访问转发到不同的Redis实例中,最后把返回结果汇集。这种方案的模式如图所示
3.什么是压测,为什么要进行压力测试?JMETER工具的使用
压力测试是通过不断向被测系统施加“压力”,测试系统在压力情况下的性能表现,考察当前软硬件环境下系统所能承受的最大负荷并帮助找出系统瓶颈所在,也就是我们可以模拟巨大的工作负荷以查看应用程序在峰值使用情况下如何执行操作。
【今天晚上技能树有点问题,图贴不了,jmeter 的使用步骤就不写了,之前日报写过】
4.Memcache和Redis可否做集群?什么样的情况下应该做集群?
都可以做集群。
后端要做负载均衡的时候缓存也要做负载均衡。
比如我们使用 session 做用户登录认证,这和时候就需要使用 redis 来缓存 session 再各个后台服务器之间共享 session。
5.什么是脏数据,缓存中是否可能产生脏数据,如果出现脏数据该怎么处理?
当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
缓存中可能产生脏数据。
对缓存进行双删,跟新数据库之前删除缓存,更新完之后间隔几百毫秒再删一次。
6.插入,更新和查询数据的时候,读写缓存和DB的顺序应该是怎么样的?
常见缓存更新策略有四种:cache aside、read through、write through、write behind caching
cache aside:
更新/插入:先存数据库再更新缓存
查询:查缓存,缓存失效再查数据库并且更新缓存
read/write through
read through:查询缓存的时候发现失效再更新缓存
write through:更新的时候如果没有命中缓存则更新数据库再更新缓存。命中缓存则先更新缓存再更新数据库。
write behind caching:更新数据的之后只更新缓存,不更新数据库。数据库由缓存异步批量跟新。
7.JVM缓存和Memcache这种缓存的区别在哪里?是否可以不使用Memcache,只用虚拟机内存做缓存?
JVM缓存: 在系统中,有些数据量不大、不常变化,但是访问十分频繁,例如省、市、区数据。针对这种场景,可以将数据加载到应用的内存中,以提升系统的访问效率,减少无谓的数据库和网路的访问。
内部缓存的限制就是存放的数据总量不能超出内存容量,毕竟还是在 JVM 里的。
比如 java 的 map、list
功能强大的内部缓存 - Guava Cache / Caffeine
本地缓存的优点:
直接使用内存,速度快,通常存取的性能可以达到每秒千万级 可以直接使用 Java 对象存取 本
地缓存的缺点: 数据保存在当前实例中,无法共享 重启应用会丢失
最著名的外部缓存 - Redis / Memcached
Redis有很多优点: 很容易做数据分片、分布式,可以做到很大的容量 使用基数比较大,库比较成熟
同时也有一些缺点: Java 对象需要序列化才能保存 如果服务器重启,再不做持久化的情况下会丢失数据,即使有持久化也容易出现各种各样的问题
8.缓存应该在Service里,还是应该存放在Controller里,为什么?
controller 缓存适合长时间不更新、变量少的数据。
service 适合缓存经常更新的数据。
9.什么叫穿透DB?什么情况下会发生,穿透DB后会发生什么事情?
就是指用户不断发起请求的数据,在缓存和DB中都没有。
这样的功击会导致DB的压力过大,严重的话就是把DB搞挂了。因为每次都绕开了缓存直接查询DB。
解决方法:
参数校验,缓存null,布隆过滤
10.什么叫命中率?正常来讲,命中率应该控制在多少?
终端用户访问加速节点时,如果该节点有缓存住了要被访问的数据时就叫做命中,如果没有的话需要回原服务器取,就是没有命中。取数据的过程与用户访问是同步进行的,所以即使是重新取的新数据,用户也不会感觉到有延时。 命中率=命中数/(命中数+没有命中数), 缓存命中率是判断加速效果好坏的重要因素之一。
11.什么样的数据适合存在缓存中?缓存的淘汰算法有哪些?
需要频繁读取但是跟新较少的小段数据适合缓存。
LFU 算法:使用的少的数据被淘汰
LRU:长时间不访问的被淘汰
12.什么叫一致性哈希,通常用来解决什么问题?
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对K/n 个关键字重新映射,其中 K是关键字的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
应用场景:缓存集群的时候常见的方式是对一个 key 进行hash处理,得出它应该存到哪台缓存服务器。那么当我们需要扩容的时候就需要重新多所有的数据进行再次 hash 后分配服务器。一致性哈希就是为了解决这个问题,让我们扩容的时候不会影响到其他服务器数据的存储路径,同时去掉缓存服务器的时候会自动分配到附近的服务器上。
13.缓存的失效策略有哪几种,分别适合什么场景?
FIFO:使用队列实现,一头放新数据,另一头淘汰数据。
适合用于数据的缓冲。
LRU:在队列的基础上,队列中被命中的数据更新到新增数据的一头,最后队尾的被淘汰
适用于内存管理、页面置换。
LFU:按照数据的访问次数排序,最少访问的被淘汰
14.Memcache和Redis的区别是什么?
redis
数据类型: string set list hash k/v ···
支持数据持久化
支持 主从复制模式
memcached
只支持 k/v 数据
不可持久化
只能做一致性哈希分布
memcached key不可长于250字节,单 item 不可以超过 1m
15.怎么预估自己系统可承载的日活数?
压力测试,测到不宕机且 90% line 在可接受范围内的最大值就是网站的可承载日活。
16.什么是JMeter?Jmeter是否可以在多台机器上分布式部署?为什么要分布式部署?
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。
可以分布式部署。
单台计算机的性能不够测试服务器,需要集群一起测试。
17.什么是TPS,什么是每秒并发数,什么是90%Line?分别应该到达多少算符合系统上线的要求?
tps:每秒处理事务数
每秒并发数:就是说服务器在一秒的时间内处理了多少个请求。
90% line:意思是90%请求的时间在某个值以下。




评论