发表于: 2020-07-04 19:49:32
1 1855
今天完成的事情:任务六深度思考
1.后台只允许有列表页和详情页,列表页分为搜索区和列表区和操作区,原因是什么?有没有其他设计方式,相比之下各自的好处是什么?
我认为后台分为列表页和详情页,可以方便后台操作人员更好的切换业务,列表页就像是一本书的目录,详情页相当于内容,通过查看目录页数可以快速定位到内容
搜索区可以帮助后台操作人员快速定位想要操作的业务。
2.什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
https://juejin.im/post/5d1b15cff265da1b971a8df3
单机结构 一个系统业务量很小的时候所有的代码都放在一个项目中就好了,然后这个项目部署在一台服务器上就好了。整个项目所有的服务都由这台服务器提供
集群 在多台不同的服务器中部署相同应用或服务模块,构成一个集群,通过负载均衡设备对外提供服务。
分布式 在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。


很少变化但是大量高并发读的数据,通过缓存集群来抗高并发读,是非常合适的。
实现方案(Redis)
官方cluster方案
twemproxy代理方案
哨兵模式
codis
客户端分片
3.什么是压测,为什么要进行压力测试?JMETER工具的使用
压测,即压力测试,是确立系统稳定性的一种测试方法,通常在系统正常运作范围之外进行,以考察其功能极限和隐患。
为了确定一个系统的瓶颈或者不能接收的性能点,来获得系统能提供的最大服务级别的测试。一款产品上线前,研发团队或运营商是会对其进行压力测试的, 目的是为了了解服务器的承受能力。以便更好的有目的的进行运营或研发。 主要检测服务器的承受能力,包括用户承受能力、流量承受等。
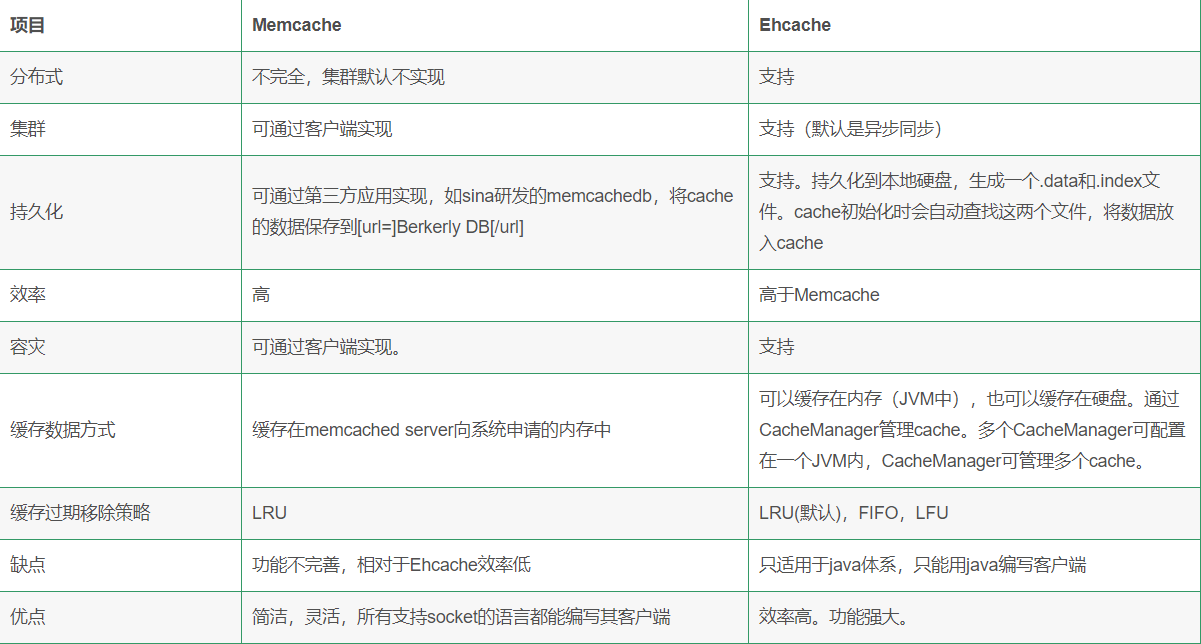
4.Memcache和Redis可否做集群?什么样的情况下应该做集群?
都可以做集群
Memcached集群方案 magent代理 moxi代理 twemproxy代理 mcrouter
对于很少变化但是大量高并发读的数据,通过缓存集群来抗高并发读,防止数据库压力过大
5.什么是脏数据,缓存中是否可能产生脏数据,如果出现脏数据该怎么处理?
脏数据就是 过期数据 ,影响系统正常运行的数据
缓存中有可能产生脏数据
处理脏数据
主动更新
先向后fill NA, 然后向前fill NA,然后把数据plot出来。
一般先处理数据的格式,频率和排序,再处理缺失值。然后做一些探索性分析,再做merge, reshape之类的操作。
6.插入,更新和查询数据的时候,读写缓存和DB的顺序应该是怎么样的?
...就跟在业务层写的逻辑一样
插入 先插入DB,.再查询缓存 .如果有缓存 用查询出的结果来更新缓存。如果没缓存,用查询出的结果新增缓存。
更新 先更新DB, 删除缓存
查询 先获取缓存,有就返回缓存,没有就去查询DB,用查询出的数据再建一个缓存值
7.JVM缓存和Memcache这种缓存的区别在哪里?是否可以不使用Memcache,只用虚拟机内存做缓存?
JVM 缓存就是Ehcache缓存
最好不要,虚拟内存有限,就那么大地方。还是用memcache好些
8.缓存应该在Service里,还是应该存放在Controller里,为什么?
应该放在Service层写逻辑
如果缓存脏读,那么就可以回滚
各层加事务的区别
第一:controller层事务
这一般是针对那些安全性要求较高的系统来说的。例如电子商务网站。粒度小,一般系统用不着这么细。
第二:service层事务
这是一常见的事务划分, 将事务设置在业务逻辑上,只要业务逻辑出错或异常就事务回滚。粒度较小,一般推荐这种方式。
第三:dao层数据务
也就是常说的数据库事务。这种事务在安全性方面要求低。就是给一个简单的增删改之类的操作增加事务操作。粒度大。
给Service层配置事务,因为一个Service层方法操作可以关联到多个DAO的操作。在Service层执行这些Dao操作,多DAO操作有失败全部回滚,成功则全部提交。
事务分为业务事务和系统事务,业务事务也就是业务逻辑上操作的一致性,系统事务自然就是指真正的数据库事务,
Spring配置事务的是为了什么进行管理,当然是为业务逻辑进行事务管理,保证业务逻辑上数据的原子性;
Dao层是什么,数据访问层,是不应该包含业务逻辑的,这就是和Service层的不同;
Service层就是业务逻辑层,事务的管理就是为Service层上的保证。
9.什么叫穿透DB?什么情况下会发生,穿透DB后会发生什么事情?
缓存雪崩:
- 现象:
影响轻则,查询变慢,重则当请求并发更高时,出来大面积服务不可用。
- 现象:
- 原因:
同一时间缓存大面积失效,就像没有缓存一样,所有的请求直接打到数据库上来,DB扛不住挂了,如果是重要的库,例如用户库,那牵联就一大片了,瞬间倒一片。
- 原因:
- 案例:
电商首页缓存,如果首页的key全部都在某一时刻失效,刚好在那一时刻有秒杀活动,那这样的话就所有的请求都被打到了DB。并发大的情况下DB必然扛不住,没有其他降级之类的方案的话,DBA也只能重启DB,但是这样又会被新的流量搞挂。
- 案例:
- 解决方案:
批量往redis存数据的时候,把每个key的失效时间加上个随机数,这样的话就能保证数据不会在同一个时间大面积失效。
- 解决方案:
缓存穿透:
- 现象与原因:
就是指用户不断发起请求的数据,在缓存和DB中都没有,比如DB中的用户ID是自增的,但是用户请求传了-1,或者是一个特别大的数字,这个时候用户很有可能就是一个攻击者,这样的功击会导致DB的压力过大,严重的话就是把DB搞挂了。因为每次都绕开了缓存直接查询DB
- 现象与原因:
- 解决方案:
- 方法一:在接口层增加校验,不合法的参数直接返回。不相信任务调用方,根据自己提供的API接口规范来,作为被调用方,要考虑可能任何的参数传值。
- 方法二:在缓存查不到,DB中也没有的情况,可以将对应的key的value写为null,或者其他特殊值写入缓存,同时将过期失效时间设置短一点,以免影响正常情况。这样是可以防止反复用同一个ID来暴力攻击。
- 方法三:正常用户是不会这样暴力功击,只有是恶意者才会这样做,可以在网关NG作一个配置项,为每一个IP设置访问阀值。
- 方法四:高级用户布隆过滤器(Bloom Filter),这个也能很好地防止缓存穿透。原理就是利用高效的数据结构和算法快速判断出你这个Key是否在DB中存在,不存在你return就好了,存在你就去查了DB刷新KV再return。
- 解决方案:
缓存击穿:
- 现象与原因:
跟缓存雪崩类似,但是又有点不一样。雪崩是因为大面积缓存失效,请求全打到DB;而缓存击穿是指一个key是热点,不停地扛住大并发请求,全都集中访问此key,而当此key过期瞬间,持续的大并发就击穿缓存,全都打在DB上。就又引发雪崩的问题。
- 现象与原因:
- 解决方案:
设置热点key不过期。或者加上互斥锁。
- 解决方案:
https://juejin.im/post/5dc416866fb9a04a972e6e3d
10.什么叫命中率?正常来讲,命中率应该控制在多少?
可以直接通过缓存获取到需要的数据的概率。
一个缓存失效机制和过期时间设计良好的系统,命中率应该达到95%以上
11.什么样的数据适合存在缓存中?缓存的淘汰算法有哪些?
变化小的,访问量大的数据可以存放在缓存中
FIFO(先入先出)
LRU(最近最少被使用)
LUF(最不经常使用)
2Q
LRU-K
ARC
12.什么叫一致性哈希,通常用来解决什么问题?
应用场景 在做缓存集群时,为了缓解服务器的压力,会部署多台缓存服务器,把数据资源均匀的分配到每个服务器上,分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集。
13.缓存的失效策略有哪几种,分别适合什么场景?
2、LRU:Least Recently Used,最近最少使用。判断最近被使用的时间,目前最远的数据优先被淘汰。
3、LFU:Least Frequently Used,最不经常使用。在一段时间内,数据被使用次数最少的,优先被淘汰。
14.Memcache和Redis的区别是什么?
1、 Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等。
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3、虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4、过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
5、分布式–设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
6、存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
7、灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8、Redis支持数据的备份,即master-slave模式的数据备份。
15.怎么预估自己系统可承载的日活数?
16.什么是JMeter?Jmeter是否可以在多台机器上分布式部署?为什么要分布式部署?
Jmeter 基于java的压力测试工具
可以
单台电脑的配置(CPU和内存)可能无法支持,使用JMeter提供的分布式测试的功能,使多台机器同时产生负载的功能。
17.什么是TPS,什么是每秒并发数,什么是90%Line?分别应该到达多少算符合系统上线的要求?
TPS 吞吐量 (每秒传输的事物处理个数,或者说每秒系统接收的任务数量)
每秒并发数: 系统同时处理的request/事务数
90%line 按顺序排列的一组数据中居于90%位置的数
没啥人用的服务 tps 20,返回有300ms就行了
十万到百万级的服务,响应能达到tps50 /200ms就可以了
后台服务,能达到tps 20 / 200ms即可(通常后台同时使用也没多少人)
秒杀类的短时间高并发……TPS100或200 在 100ms内响应 应该也能撑一段时间(具体情况还是要看业务量)
https://blog.csdn.net/weixin_43639512/article/details/100118274
任务总结:
任务名称:java-task6
成果链接:https://github.com/JOJO-Boot/ITXZY
任务耗时:6.28~7.4耗时7天
任务脑图:
官方脑图

任务总结:
学会使用Jmeter压测
安装配置memcached,使用spring集成memcached并放到服务器上。
学习使用nginx进行动静分离,和负载均衡。然后对服务器进行测试。
跑通之后,尝试学习Redis,发现用法和memcached相差不大。
对Redis进行集成,并放到服务器上。
明天计划的事情,尝试任务七




评论