发表于: 2020-07-03 22:15:07
1 1682
今天完成的事情:
完善昨天的代码使用SpringAOP来编写一个日志类记录各方法耗费的时间
昨天使用的xml配置,今天学习一下用注解的方式来使用AOP
package com.jnshu.util;
import org.apache.log4j.Logger;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
@Component("logger")
@Aspect//表示当前类是一个切面
public class LoggerAop {
@Pointcut("execution( * com.jnshu.service.StudentServiceImpl.selectStudent())")
private void pt1(){}
private static final Logger logger = Logger.getLogger(LoggerAop.class);
//环绕通知
@Around("pt1()")
public Object printLog(ProceedingJoinPoint pjp){
Object rtValue = null;
try{
Object[] args = pjp.getArgs();
Long start = System.currentTimeMillis();
rtValue = pjp.proceed();
Long end = System.currentTimeMillis();
Long taketime = end - start;
logger.info("请求总耗时:" + taketime + "毫秒");
return rtValue;
}catch (Throwable t){
throw new RuntimeException(t);
}
}
}
然后配置文件里加上:
<aop:aspectj-autoproxy></aop:aspectj-autoproxy>
再修改一下,加入识别当前方法名,并且将controller层也配置切面:
package com.jnshu.util;
import org.apache.log4j.Logger;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
@Component("logger")
@Aspect//表示当前类是一个切面
public class LoggerAop {
@Pointcut("execution( * com.jnshu.service.*.*(..))||execution( * com.jnshu.controller.*.*(..))")
private void pt1(){}
private static final Logger logger = Logger.getLogger(LoggerAop.class);
//环绕通知
@Around("pt1()")
public Object printLog(ProceedingJoinPoint pjp){
Object rtValue = null;
String methodName = pjp.getSignature().getName();
try{
Object[] args = pjp.getArgs();
Long start = System.currentTimeMillis();
rtValue = pjp.proceed();
Long end = System.currentTimeMillis();
Long taketime = end - start;
logger.info(methodName + "请求总耗时:" + taketime + "毫秒");
return rtValue;
}catch (Throwable t){
throw new RuntimeException(t);
}
}
}
测试一下效果:

可以看到各个方法所耗费的时间了,发现消耗的时间主要再selectStudent方法。
学习Memcache.
一、memcache概述
1、memcache就是一个数据库、但是数据存在内存中。常用来做缓存服务器、将从数据库查询的数据缓存起来,减少数据库查询、加快查询速度。
2、明确使用场景:缓存服务器
3、适合存储的数据:
①访问比较频繁的数据,安全性差的数据,丢失无所谓的数据。
②数据更新,比较频繁的数据,比如用户的在线状态。
③数据的单个键值不能太大,不要超过1Mb数据。
什么是Memcache?
Memcache集群环境下缓存解决方案
Memcache是一个高性能的分布式的内存对象缓存系统,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。简单的说就是将数据调用到内存中,然后从内存中读取,从而大大提高读取速度。
Memcache是danga的一个项目,最早是LiveJournal 服务的,最初为了加速 LiveJournal 访问速度而开发的,后来被很多大型的网站采用。
Memcached是以守护程序方式运行于一个或多个服务器中,随时会接收客户端的连接和操作
为什么会有Memcache和memcached两种名称?
其实Memcache是这个项目的名称,而memcached是它服务器端的主程序文件名。一个是项目名称,一个是主程序文件名.
Memcached是高性能的,分布式的内存对象缓存系统,用于在动态应用中减少数据库负载,提升访问速度。Memcached由Danga Interactive开发,用于提升LiveJournal.com访问速度的。LJ每秒动态页面访问量几千次,用户700万。Memcached将数据库负载大幅度降低,更好的分配资源,更快速访问。
昨天已经安装了Memcached
以管理员身份运行cmd,输入memcached -d start启动
输入telnet 127.0.0.1 11211链接Memcached,进入以下界面:

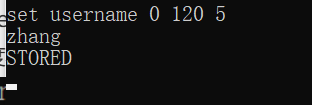
输入set username 0 120 5
作用:set命令用于向memcache存储一对键值对数据
username[key] 0[是否压缩] 120[存活时长] 5[字符长度]
如果字符长度不符会报错:
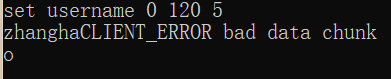
如果符合则:
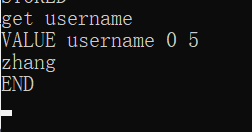
输入get username来查看key:
add和set类似,不过如果key已经存在,使用add不会更新并提示NOT_STORED,而使用set会覆盖之前的key
delete key 可以删除key
flush_all 可以删除memcached中所有的key及value
incr 可以对key存在的value进行相加操作
decr 可以对key存在的value进行相减操作
stats 返回memcached统计信息(比如set、get总数,连接数等....)
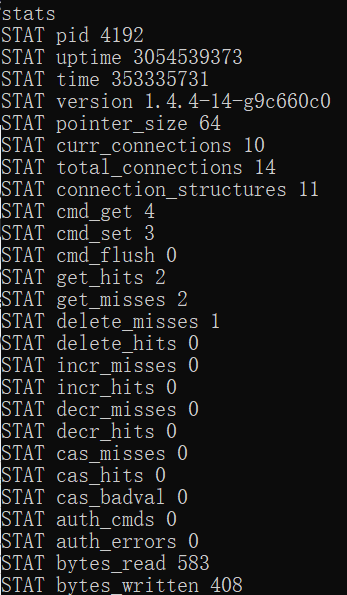
1、cmd_get:执行get请求次数
1、cmd_set:执行set请求次数
3、get_misses:get指令未命中次数
4、get_hits:get指令命中次数
5、curr_connections:当前连接数
整合memcached:
Memcached Client目前有3种:
Memcached Client for Java
SpyMemcached
XMemcached
这三种Client一直存在各种争议:
Memcached Client for Java 比 SpyMemcached更稳定、更早、更广泛;
SpyMemcached 比 Memcached Client for Java更高效;
XMemcached 比 SpyMemcache并发效果更好。
XMemcached特性:
高性能
支持完整的memcached文本协议,二进制协议。
支持JMX,可以通过MBean调整性能参数、动态添加/移除server、查看统计等。
支持客户端统计
支持memcached节点的动态增减。
支持memcached分布:余数分布和一致性哈希分布。
更多的性能调整选项。
此外,XMemcached更容易与Spring集成。
Spring整合Memcached:
导入依赖:
<!-- https://mvnrepository.com/artifact/com.whalin/Memcached-Java-Client -->
<dependency>
<groupId>com.whalin</groupId>
<artifactId>Memcached-Java-Client</artifactId>
<version>3.0.2</version>
</dependency>
创建配置文件:memcached.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="memCachedPool" class= "com.whalin.MemCached.SockIOPool"
factory-method="getInstance" init-method="initialize"
lazy-init="false" destroy-method="shutDown">
<!-- 构造函数 -->
<constructor-arg value="memCachedPool"/>
<!-- 可以设置多个memcachePool服务器 -->
<property name="servers">
<list>
<value>127.0.0.1:11211</value>
</list>
</property>
<!-- 每台服务器的初始连接 -->
<property name="initConn" value="10"/>
<!-- 每台服务器的最小连接 -->
<property name="minConn" value="5"/>
<!-- 每台服务器的最大连接数 -->
<property name="maxConn" value="250"/>
<!-- 主线程睡眠时间 -->
<property name="maintSleep" value="30"/>
<!-- Tcp/Socket 的参数, 如果是true在写数据时不会缓冲, 会立即发出 -->
<property name="nagle" value="false"/>
<!-- 连接超时/阻塞读取时间的超时时间 -->
<property name="socketTO" value="3000"/>
</bean>
<bean id="memCachedClient" class= "com.whalin.MemCached.MemCachedClient" lazy-init="false">
<constructor-arg value="memCachedPool"/>
</bean>
</beans>
同时在applicationContext.xml中配置:
<import resource="memcached.xml"/>
修改业务层:
package com.jnshu.service;
import com.jnshu.dao.StudentMapper;
import com.jnshu.pojo.Student;
import com.whalin.MemCached.MemCachedClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class StudentServiceImpl implements StudentService {
@Autowired private StudentMapper studentMapper;
@Autowired
private MemCachedClient memCachedClient;
@Override
public int deleteByPrimaryKey(Long id) {
int i = studentMapper.deleteByPrimaryKey(id);
if(i>0){
//同时删除缓存
System.out.println("删除缓存。。。" + id);
memCachedClient.delete("student" + id);
}
return i;
}
@Override
public int insert(Student record) {
int i = studentMapper.insert(record);
if(i>0){
System.out.println("存入缓存" + record);
memCachedClient.add("student" + record.getId(),record);
}
return i;
}
@Override
public Student selectByPrimaryKey(Long id) {
//先查询缓存中是否存在,若存在则直接从缓存中取
Student student = (Student)memCachedClient.get("student"+id);
if(student != null){
System.out.println("从缓存中查询");
}else{
//若缓存中不存在,则从数据库中查询,并存入缓存
System.out.println("从数据库中查询");
student = studentMapper.selectByPrimaryKey(id);
memCachedClient.add("student"+ id ,student);
}
return student;
}
@Override
public List<Student> selectStudent() {
List<Student> list = (List<Student>)memCachedClient.get("AllStudent");
if(list != null){
System.out.println("从缓存中查询。。。");
}else{
System.out.println("从数据库中查询。。。");
list = studentMapper.selectStudent();
memCachedClient.add("AllStudent",list);
}
return studentMapper.selectStudent();
}
@Override
public int selectByLearning() {
return studentMapper.selectByLearning();
}
@Override
public int selectByWorking() {
return studentMapper.selectByWorking();
}
@Override
public int updateByPrimaryKeySelective(Student record) {
int i = studentMapper.updateByPrimaryKeySelective(record);
if(i>0){
memCachedClient.replace("student"+record.getId(),record);
}
return i;
}
}
测试一下:


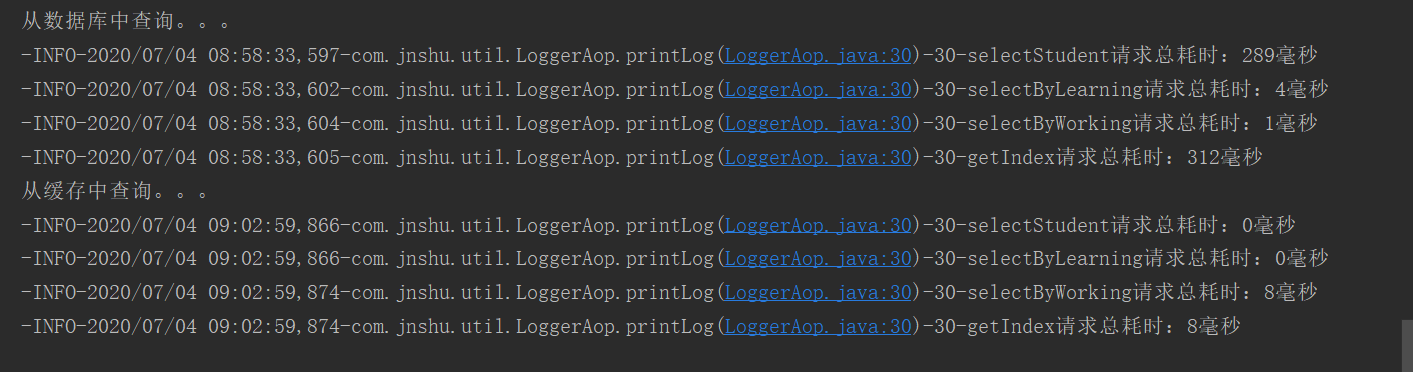
查询速度显著提升!
使用JMeter进行压力测试:
线程数设500都很快:
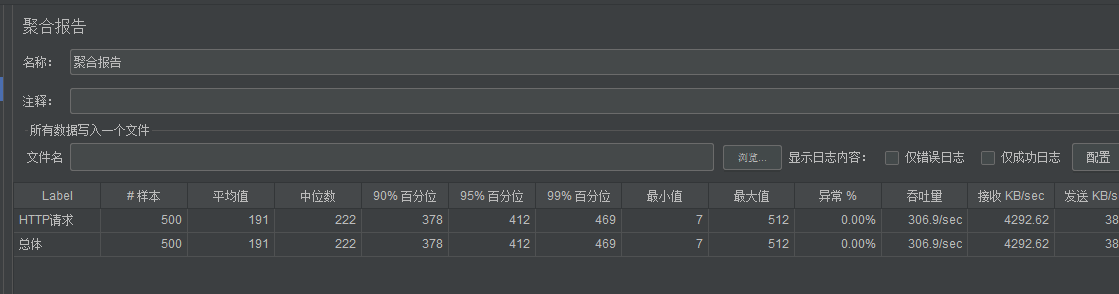
后面直接加到2000站点就挂了。。。
收获:完成了使用SpingAOP编写日志模块,初步整合Memcached。
碰到的问题:现在站点挂了进不去了,重启tomcat也没用。。。
明天计划的事情:
继续任务六。




评论