发表于: 2020-06-13 21:49:38
1 1665
加油!!!
今天完成的事:
图片存储在本地,配置Nginx读取

读取图片
配置Nginx关于请求和响应时间的记录

可以看出请求和响应时间为6ms

关于日志的学习
为什么要做日志
原因1:跟踪应用的警告和错误,标识程序运行中的危险操作、错误操作,进而便于在出现问题时排查问题
原因2:跟踪崩溃bug,在开发过程中,日志可以帮助开发者和软件测试人员跟踪程序崩溃的原因
原因3:跟踪性能下降的问题范围,产品所反映出来的性能问题,很难在开发过程中暴露出来,这需要进行全方位的测试跟踪,而通过日志提供的详细执行时间记录可以很方便的找出应用的性能瓶颈
原因4:跟踪操作流程,通过对日志跟踪,你可以获取操作发生的具体环境,操作的结果
补充原因:
了解项目的运行状态
发现潜在的性能问题
价值化(大数据分析)
日志打印的位置:
1、程序入口:在入口打印日志是因为这个时候传递进来的参数没有经过任何处理,将它打印在日志文件中能一眼就知道程序的原始数据是否符合我们的预期,是不是传递进来的原始数据就出现 的问题。
2、计算结果,测试关心的程序的输出结果是否符合预期,那么对于计算过程不应该关心,仅给出计算结果就能判断是否符合预期。
3、重要信息:这一点可能很宽泛,因为不同的业务逻辑重点可能并不一样,例如在有的重要参数不能为空,此时就需要判断是否为空,如果为空则记录到日志中;还有的例如传递进来的参数经过一系列的算法处理过后,此时也需要打印日志来查看是否计算正确。但切记,尽量不要直接在for循环中打印日志,特别是for循环特别大时,这样你的日志可能分分钟被冲得不见踪迹,甚至带来性能上的影响。
4、异常捕获:在异常打印出详细的日志能让你快速定位错误在哪里,例如在程序抛出异常捕获时,在平时我们经常就是直接在控制台打印出堆栈信息e.printStackTrace(),但在实际的生产环境更加艰苦,更别说有IDE来让你查看控制台信息,此时就需要我们将堆栈信息记录在日志中,以便发生异常时我们能准确定位程序在哪里出错。
常见的日志打印处:
1、函数开始结束处
重要函数的开始结束出应该打上log ,这样在看log时会比较直观,什么时候开始什么时候结束就会一目了然,万一中间出异常导致程序退出了,也知道是在哪个函数突然中断的。也同样适用于一个重要逻辑块的开始结束。
2、返回结果时
尽量在重要函数或web接口的每个返回分支打印返回结果。在出现不好分析的异常时,从细节下手,这时log会派上用场。如果跟合作方在数据方面出现争议也可以及时拿出证据。特别是在调用外部系统接口时,一定要打印结果。
3、在多线程中
日志最好要记录线程ID日志还要记录线程ID,否则可能不知道是哪个线程的作业,也无法有条理的来观察一个线程。
4、需要记录程序耗时处
访问一个第三方接口、上传下载文件等可能耗时的操作,都要记录完成这个操作所耗的时间。否则程序性能出了问题,你不知道是网络原因呢,还是你调用的第三方接口性能出现问题呢,还是你自己程序的问题呢。
5、批量操作
涉及到数量的操作要打印log,比如查询数据库和批量拷贝文件、上传下载、批量格式转换等批量操作,设计到的数量要打印出来。
分布式系统追踪请求
RequestID:我们通常用RequestID来对请求进行唯一的标记,目的是可以通过RequestID将一个请求在系统中的执行过程串联起来,这在分布式系统中的威力是巨大的。该RequestID通常会随着响应返回给调用者,如果调用出现问题,调用者也可以通过提供RequestID帮助服务提供者定位问题。
什么时候应该打日志
1、当你遇到问题的时候,只能通过debug功能来确定问题,你应该考虑打日志,良好的系统,是可以通过日志进行问题定位的。
2、经常以功能为核心进行开发,你应该在提交代码前,可以确定通过日志可以看到整个流程。
3、和一个外部系统进行通信时,要记录下你的系统传出和读入的数据,这样以便查明是否为外部系统的问题。系统集成是一件苦差事,而诊断两个应用间的问题(想像下不同的公司,环境,技术团队)尤其困难。
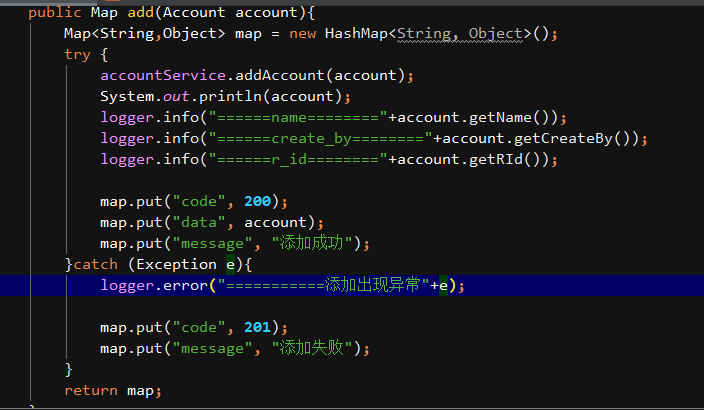
明天计划的事:完成任务三剩下的部分
遇到的困难:
收获:




评论