发表于: 2020-06-11 21:18:24
1 1814
今天完成的事情:今天完成了数据库表设计,banner接口文档的编写,深度思考,复习了下JSTL常用标签。
明天计划的事情:开始着手开发项目。
遇到的问题:暂无
收获:
根据昨天设计数据库表的问题,自己学习了一对多和多对多应该怎么设计表?
1. 概念
实体表:就是实际对象对应的表,像学生表,老师表。
关系表:当多对多的情况下,一个老师有很多学生,一个学生有很多学科的老师,就建立学生表,老师表,以及学生老师关系表。
首先这种一对一,一对多,多对多说的是数据库中数据的对应关系,而不是表和表。
一对一:一个学生就一个身份证,一张身份证也只对应唯一的一个人
一对多:一个学生属于一个班级,但是一个班级有很多学生
多对多:学生和学科老师对应关系
2. 利用上面对应关系事例的数据库设计和实体类设计:
一对一:就在学生类中添加身份证字段就行;
一对多:设计学生表和班级表,学生表中添加班级id;
多对多:设计学生表,老师表,老师_学生关系表。老师_关系表中设置学生id,老师id对应关系;
一对一在实体类中多加一个属性,一对多在实体类中多加一个集合属性,多对多就是在两个实体类中各加一个集合属性;
3. 为什么不建议通过添加主外键约束 ?
因为在数据库层面通过使用外键的方式进行“硬绑定”,会带来很多额外的资源消耗来进行一致性和完整性校验,即使很多时候我们并不需要这个校验。
所以一般不建议在数据库中使用外键约束来保证数据的一致性和完整性。
然后接下来我是修改了我的数据库表
留言表和作品表是一对多情况。即一个留言属于一个作品,一个作品有很多留言。就在作品表中添加留言id。
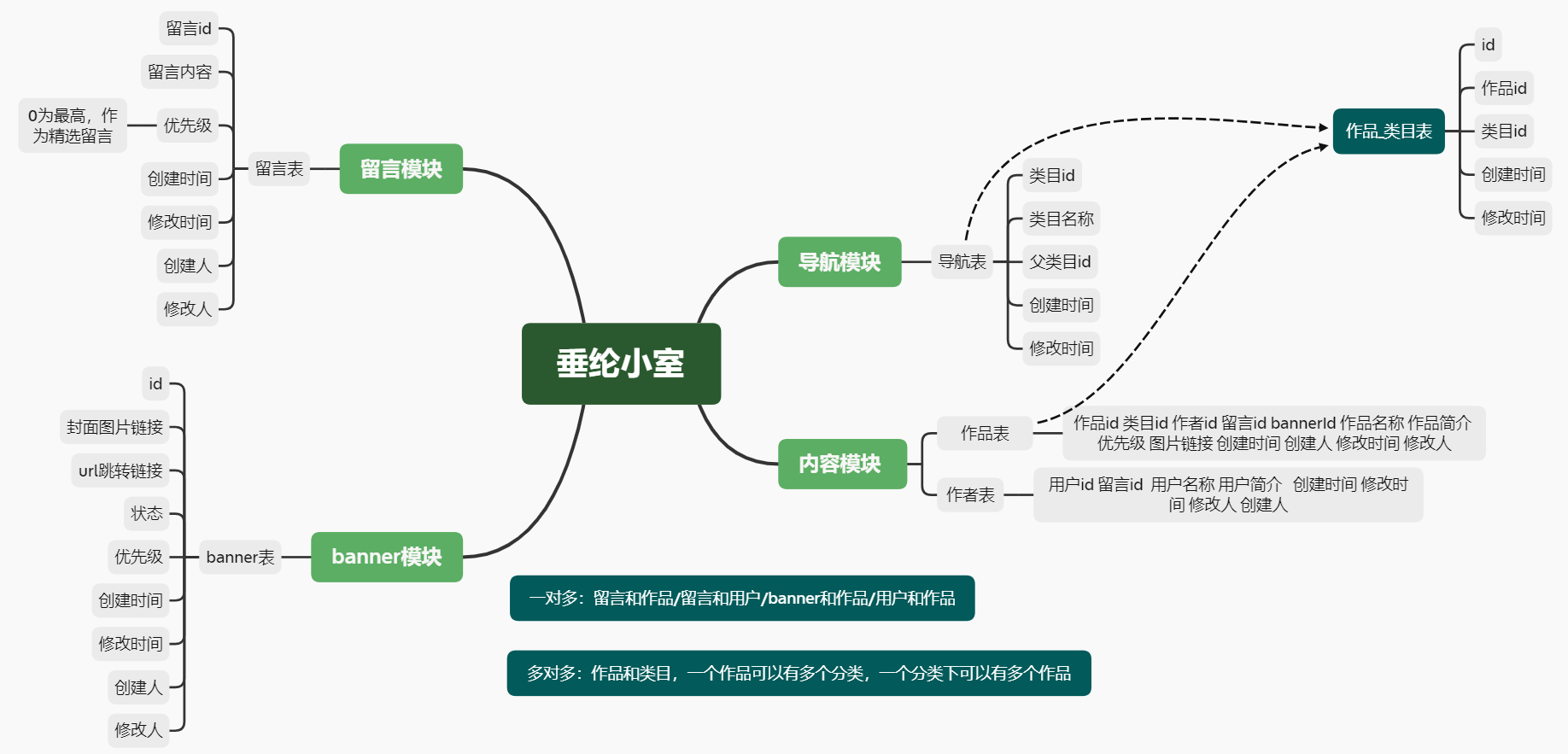
数据库表设计
catalog导航目录表
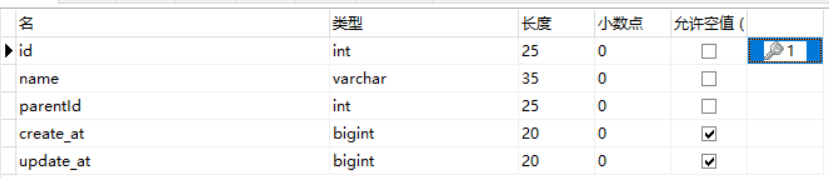
picture作品表
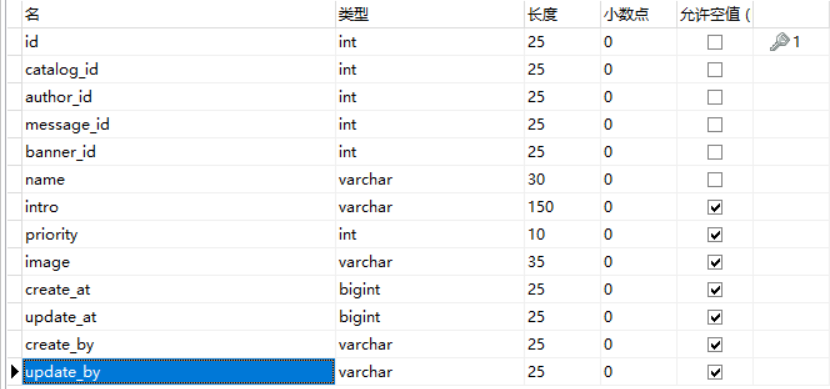
author作者表
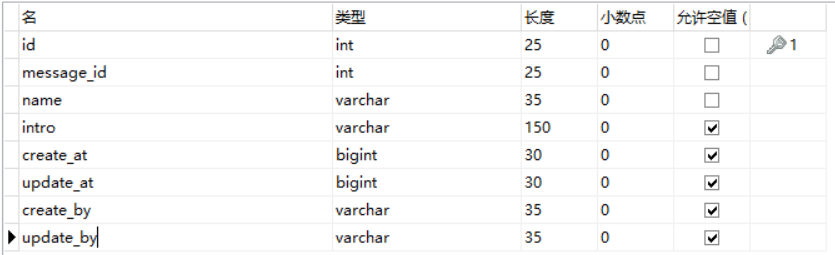
message留言表
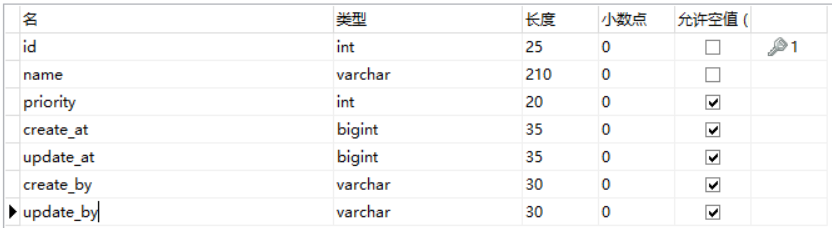
banner表
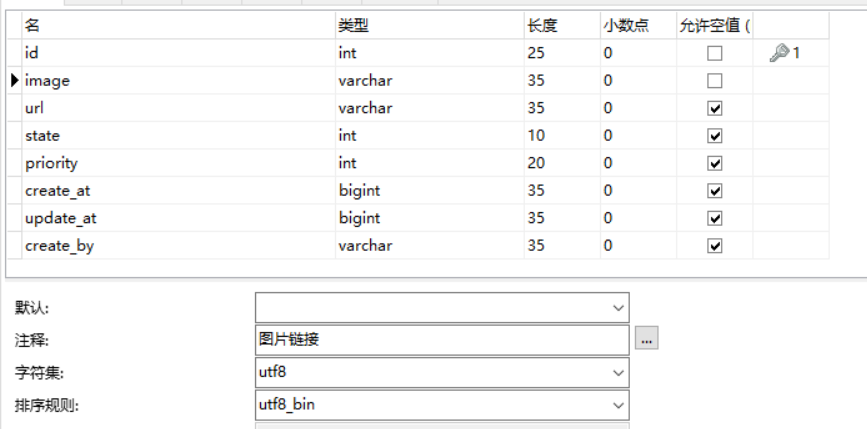
pic_log作品目录表
banner接口文档
接口功能
- banner插入接口
请求URL:
- POST
/banner
参数:
| 参数名 | 说明 | 类型 | 备注 | 是否必填 |
|---|---|---|---|---|
| image | 缩略图链接 | String | 是 | |
| url | url链接 | String | 是 | |
| state | 状态 | int | 0为下架,1为上架 | 是 |
| priority | 优先级 | int | 是 | |
| createAt | 创建时间 | long | 是 | |
| updateAt | 修改时间 | long | 是 | |
| createBy | 创建人 | String | 是 | |
| updateBy | 修改人 | String | 是 |
返回示例
{"code": 201,"message": "banner创建成功!","data": {}}
接口功能:
- banner查询
请求URL:
- get
/banner
返回参数
| 参数名 | 说明 | 类型 | 备注 | 是否必填 |
|---|---|---|---|---|
| code | 响应码 | number | 是 | |
| message | 信息 | String | 是 | |
| data | banner对象 | object | 是 |
data:
| 参数名 | 说明 | 类型 | 备注 | 是否必填 |
|---|---|---|---|---|
| image | 缩略图链接 | String | 是 | |
| url | url链接 | String | 是 |
返回示例
{"code": 202,"message": "banner查询成功!","data": {"image":"http://test.com/xxx.jpg","url","http://test.com/xxx"}}
接口功能:
- banner修改
请求URL:
- put
/banner/{id}/{state}
请求参数
| 参数名 | 说明 | 类型 | 备注 | 是否必填 |
|---|---|---|---|---|
| id | id | Integer | 是 | |
| state | 状态 | Integer | 是 |
返回参数
| 参数名 | 说明 | 类型 | 备注 | 是否必填 |
|---|---|---|---|---|
| code | 响应码 | number | 是 | |
| message | 信息 | String | 是 |
返回示例
{"code": 203,"message": "banner修改成功!","data": {}}
接口功能:
- banner删除
请求URL:
- delete
/banner/{id}
请求参数
| 参数名 | 说明 | 类型 | 备注 | 是否必填 |
|---|---|---|---|---|
| id | id | Integer | 是 |
返回参数
| 参数名 | 说明 | 类型 | 备注 | 是否必填 |
|---|---|---|---|---|
| code | 响应码 | number | 是 | |
| message | 信息 | String | 是 |
返回示例
{"code": 204,"message": "banner删除成功!","data": {}}
14.端口是什么含义,怎么判断一个端口是否被占用了,如何判断一个端口是否被防火墙拦截,怎么用Telnet判断端口号是否打开?
端口:是英文port的意译,可以认为是设备与外界通讯交流的出口。端口可分为虚拟端口和物理端口,其中虚拟端口指计算机内部或交换机路由器内的端口,不可见。例如计算机中的80端口、21端口、23端口等。物理端口又称为接口,是可见端口,计算机背板的RJ45网口,交换机路由器集线器等RJ45端口。电话使用RJ11插口也属于物理端口的范畴。
(3)动态和/或私有端口(Dynamic and/or Private Ports):从49152到65535。理论上,不应为服务分配这些端口。实际上,机器通常从1024起分配动态端口。但也有例外:SUN的RPC端口从32768开始。
Linux端口号查询的命令:
使用netstat tasklist taskkill netstat -an 更常用是netstat -tnlp | grep :8080,还有就是ps -ef | grep tomcat
Netstat 显示协议统计和当前的 TCP/IP 网络连接。该命令只有在安装了 TCP/IP 协议后才可以使用。
防火墙查看命令:
firewall-cmd --state这个命令查看防火墙状态
firewall-cmd --zone=public --list-ports 查看当前打开的所有端口

15.WEB服务器通常要配置哪几个端口,如果一台服务器上有多个不同的WEB服务,该怎么规划端口的使用,修真院的端口分配是怎么样的?
web 服务器一般要开放 80(http)、443(https)、3306(mysql)、22 (ssh) 21(ftp)端口。一般一台服务器只部署一个 WEB 服务。这样单台服务器挂掉不会影响其他服务
16.常用的性能统计命令有哪些,Top,Vmstat,free等命令都有什么用处,CPU占用率,内存使用分别代表什么含义?到什么情况下,应该产生报警信息?
top:查看服务器整体的性能;(uptime)
vmstat:查看CPU的性能;vmstat -n 2 3
free:查看内存使用的情况; free -m
iostat:查看磁盘读取速度; iostat -d 2 3(需要sysstat包);
ping:查看网络连通性,与Windows类似
netstat:查看端口号,一般都不使用这个命令,一般情况下都使用ps命令来查看
什么情况下应该注意服务器性能?
一般情况下,使用top命令后,load average 中 三个数据的平均值大于 0.6后,就应该注意是否有僵尸程序或异常程序在占用资源
什么情况下使用这些服务器命令?什么异常日志打印不出来?
这些命令主要解决服务器性能慢的问题,一些僵尸程序,日志中是无法体现的(例如压测过后,或产生一个僵尸程序,占用90%以上的资源),还有一种可能,就是写的某些程序造成了与之前代码的冲突,产生莫名的死循环,这种情况也是日志打印不出来的.
权限怎么会造成系统问题?
没有权限的话,会造成访问不了相关的程序(例如在安装mysql的时候,就需要赋予相关的权限,否则运行部了程序),一般而言都是将权限付为chmod 777
top
top -d 10指定每两次屏幕信息刷新之间的时间间隔为10秒。
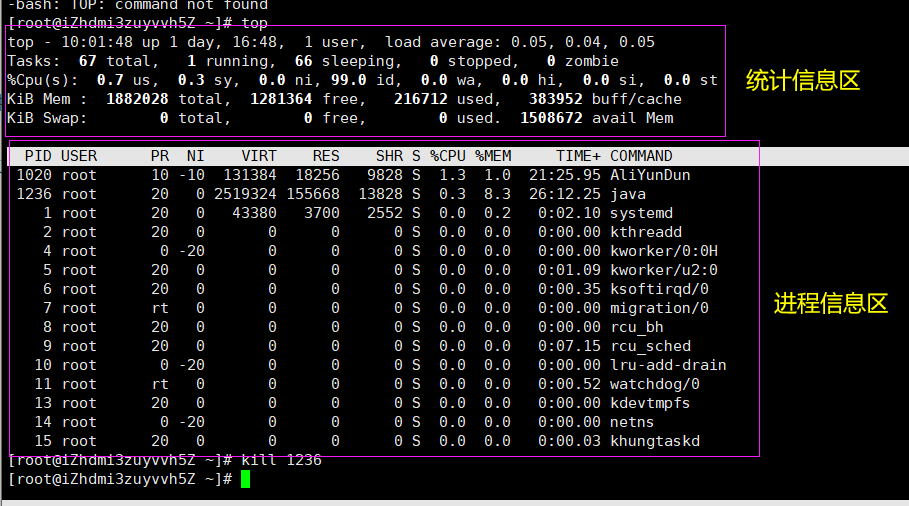
统计信息区
前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
| 10:37:35 | 当前时间 |
| up 25 days, 17:29 | 系统运行时间,格式为时:分 |
| 1 user | 当前登录用户数 |
| load average: 0.00, 0.02, 0.05 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
| Tasks: 104 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 103 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
| Cpu(s): 0.1%us | 用户空间占用CPU百分比 |
| 0.0%sy | 内核空间占用CPU百分比 |
| 0.0%ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 99.9%id | 空闲CPU百分比 |
| 0.0%wa | 等待输入输出的CPU时间百分比 |
| 0.0% hi | |
| 0.0% si | |
| 0.0%st |
最后两行为内存信息。内容如下:
| Mem: 2067816k total | 物理内存总量 |
| 2007264k used | 使用的物理内存总量 |
| 60552k free | 空闲内存总量 |
| 73752k buffers | 用作内核缓存的内存量 |
| Swap: 524284k total | 交换区总量 |
| 315424k used | 使用的交换区总量 |
| 208860k free | 空闲交换区总量 |
| 625832k cached | 缓冲的交换区总量。 内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖, 该数值即为这些内容已存在于内存中的交换区的大小。 相应的内存再次被换出时可不必再对交换区写入。 |
进程信息区
统计信息区域的下方显示了各个进程的详细信息。首先来认识一下各列的含义。
| 序号 | 列名 | 含义 |
| a | PID | 进程id |
| b | PPID | 父进程id |
| c | RUSER | Real user name |
| d | UID | 进程所有者的用户id |
| e | USER | 进程所有者的用户名 |
| f | GROUP | 进程所有者的组名 |
| g | TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| h | PR | 优先级 |
| i | NI | nice值。负值表示高优先级,正值表示低优先级 |
| j | P | 最后使用的CPU,仅在多CPU环境下有意义 |
| k | %CPU | 上次更新到现在的CPU时间占用百分比 |
| l | TIME | 进程使用的CPU时间总计,单位秒 |
| m | TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| n | %MEM | 进程使用的物理内存百分比 |
| o | VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| p | SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb。 |
| q | RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| r | CODE | 可执行代码占用的物理内存大小,单位kb |
| s | DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| t | SHR | 共享内存大小,单位kb |
| u | nFLT | 页面错误次数 |
| v | nDRT | 最后一次写入到现在,被修改过的页面数。 |
| w | S | 进程状态。 D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| x | COMMAND | 命令名/命令行 |
| y | WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| z | Flags | 任务标志,参考 sched.h |
17.为什么要知道响应时间的分布情况,如果一个请求很慢,它的时间可能会被耗费在哪里?
响应时间的分布情况可以及时的获悉异常,或者获取到其它重要信息,如果是程序代码,可以手动优化,如果是服务器,数据库我们可以找到优化方案。
请求耗时一般是几个地方:1.网络波动;2.服务器db连接过多;3.服务器负载过高;4.资源加载
18.怎么查看Resin或者是Tomcat中的DB访问时间和Controller时间,有没有可能用Aop的方法自动记录Controller的时间和DB时间?Controller时间和DB时间的区别是什么,在你写的业务逻辑里,相差有多大?
查看Resin和Tomcat的DB和Controller访问时间,一般是出现响应时间过长,性能低。
这个时候会考虑做性能优化,简单的用户个人信息这种请求,应该在50MS左右,List的数据,差不多在100MS左右。这是比较正常的数据。多少MS才算慢?通常来说,人的眼睛对于200MS以上的时延是有反应的,所以一般而言,整个页面都应该在200MS之内完成。
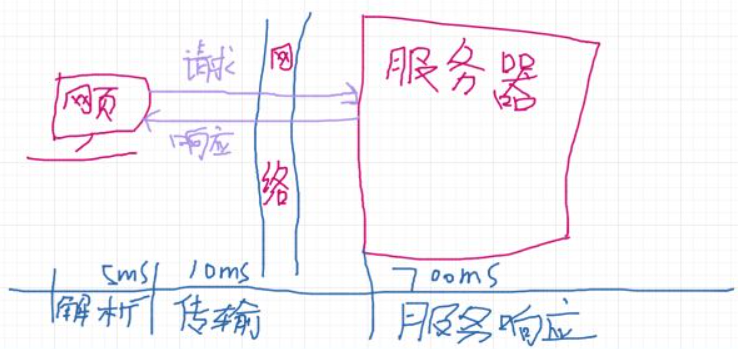
这表示,对于一个网络请求来说,第一个层面,你需要知道的时间的损耗可以分解成三大部分。
第一部分前端的响应,一般包括解析和渲染,这部分的性能跟前端的代码,前端硬件有关系。
第二部分就是网络延迟,这部分的代码正常来讲是在8~16MS左右,是的,Http请求就是差不多这个性能,如果是WebSocket几乎可以做到零延迟
第三部分就是服务器端的响应,我们说的是网站慢,一般而言,也就是主要在这里,要做性能优化的地方
Access.log里会记录服务器端自己的响应时间,这是后端查看性能的重要依据
通过Aop的方法可以在Controller方法执行前后来切入记录日志。使用了环绕方法切入Controller和ServiceImpl来获取访问时间。
Tomcat响应的时间可以分为: 1.Controller的处理时间 2.Service的调用时间 3.返回结果的处理时间
controller本身的处理事情,一般都会是在开始和结束各打一条毫秒数这是所有的业务逻辑处理的总时间。调用各Service的时间包含网络传输和Service的响应时间。返回结果的时间一般都是解析成Json的时间。
https://www.zhihu.com/question/58481553这是老大的知乎文章,讲的很棒,而且还有福利,哈哈。
19.怎么判断WEB容器是否收到了一个Http请求,WEB容器中的Access.log是什么意思,包含哪些字段,代表什么含义,是哪里配置修改字段的。
通过日志判断。
access.log就是使用日志,包含了基本上所有的访问信息。
nginx是在conf文件夹下的nginx.conf文件配置的:
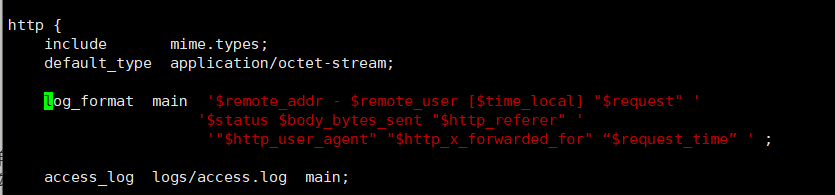
具体属性如下:$remote_addr与$http_x_forwarded_for(反向)用以记录客户端的ip地址;
$remote_user:用来记录客户端用户名称;
$time_local: 用来记录访问时间与时区;
$request: 用来记录请求的url与http协议;
$status: 用来记录请求状态;成功是200;
$body_bytes_sent :记录发送给客户端文件主体内容大小;
$http_referer:用来记录从那个页面链接访问过来的;
$http_user_agent:记录客户浏览器的相关信息;
20.为什么通常都是将部署文件放置在/data/盘下,在云服务器中数据盘和系统盘的区别是什么?
部署文件集中在一起比较容易管理,2.习惯data一般都是部署网站的根目录
数据盘和系统盘就像是win的d盘和c盘,一般数据都不推荐放在系统盘
21.常用的主流数据库有哪些,Mysql有几种安装方式?
关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
NoSQL 划分为 4 种类型:键值数据库、列式数据库、文档数据库和图形数据库。
Yum安装Mysql,rpm安装Mysql ,二进制安装
22.有哪些常用云服务器公司,Linux服务器和Windows服务器的差别是什么,Linux有哪些主流的版本,不同版本之间的差别在哪里?
云服务器公司:阿里云,腾讯云,西部数码,华为云
目前绝大多数互联网公司采用的都是Linux服务器,可见Windows服务器在服务器领域是处于劣势。
1.Linux在安全性和稳定性方面是非常出众的。
2.Linux开源免费,为企业节省相当一部分开支。当然收费版本的Linux提供的服务要更好一些,这就给企业提供了更多的选择。
3.Linux占用系统资源少,这就在大大降低对硬件要求的同时,在更大程度上提升了系统的性能。
4.Linux系统与Apache、nginx等服务器的先天相容性。Linux内核是采用C语言编写的,众多的服务器软件都是采用C语言编写,这就在代码层大大提高了服务器提供服务的能力
综上,Linux服务器要比Windows服务器优势明显。
主流版本:
CentOS用于 Linux 服务器的最有名、最常用的发行版,但是它的桌面版本还在继续不断完善中。另外,它的稳健性、稳定性、和 100% 的二进制兼容性.
Ubuntu 基于知名的 Debian Linux 发展而来,界面友好,容易上手,对硬件的支持非常全面,是目前最适合做桌面系统的 Linux 发行版本,而且 Ubuntu 的所有发行版本都免费提供。
SuSE Linux 可以非常方便地实现与 Windows 的交互,硬件检测非常优秀,拥有界面友好的安装过程、图形管理工具,对于终端用户和管理员来说使用非常方便。如果你需要使用数据库高级服务和电子邮件网络应用,则可以选择 SuSE。
Gentoo由于编译软件需要消耗大量的时间,所以,如果你所有的软件都由自己编译,并安装 KDE 桌面系统等比较大的软件包,则可能需要花费很长时间,想非常灵活地定制自己的 Linux 系统,那就选择 Gentoo。
如果你对系统稳定性要求很高,则可以考虑 FreeBSD。还有其他很多。
23.什么是ssh?如何在linux服务器上从网站下载文件?
wget http://xxx.xxx.x.xxxx.tar.gz 而且linux也有自己的维护社区,也可以使用yum来进行安装,比如yum install xxx
24.C标签是什么,为什么要使用C标签,有哪些常见的指令?
1. C标签即JSP标准标签库(JSTL)是一个JSP标签集合,它封装了JSP应用的通用核心功能。
JSTL支持通用的、结构化的任务,比如迭代,条件判断,XML文档操作,国际化标签,SQL标签。 除了这些,它还提供了一个框架来使用集成JSTL的自定义标签。用于简化jsp开发,提高代码的可读性和可维护性。由SUN(Oracle)定义规范,Apache Tomcat团队实现。
标签库下载地址:http://tomcat.apache.org 在tomcat官网下滑找到
2. 安装JSTL 标签库,JSTL 两种安装方式:
1)将 Jar 文件复制到工程的 /WEB - INF / lib 目录(推荐);
2)将 Jar 文件复制到 Tomcat 安装目录的lib目录;
JSTL有五个标签库 分别是:核心标签库(core)、格式标签库(fmt)、函数标签库(functions)、SQL标签库、XML标签库。
主要用前两者。
3.JSTL核心库运用:在创建的jsp文件加上头文件<%@ taglib uri = "http://java.sun.com/jsp/jstl/core" prefix = "c" %>
JSTL核心库提供了两组判断的标签 ,对应java的if elseif else:
<c:if>单分支判断
<c:choose><c:when><c:otherwise> 多分支判断
遍历集合:<c:forEach> 标签用于遍历集合(Collection) 中的每一个对象; 循环遍历 通常用于存放在request、session、Application 中的集合
例:
<c:forEach var = "stu" items = "${Student}" varStatus="idx">
第 ${idx.index + 1}位 <br/> 姓名:${stu.name} 性别:${stu.sex} 年龄:${stu.age}
</c:forEach>items:数据源,其中Student代表的是List或者是set集合; varStatus:代表的是索引,从 0 开始
4. JSTL格式标签库,在头文件加上<%@ taglib uri="http://java.sun.com/jsp/jstl/fmt" prefix="fmt"%>
fmt 格式化标签库:
例:
<fmt:formatDate value="${requestScope.now }" pattern="yyyy年MM月dd日HH时mm分ss秒SSS毫秒" /><fmt:formatDate value = " " pattern= " " > 格式化日期标签;
<fmt:formatNumber value = " " pattern=" "> 格式化数字标签;
value="":原始的值;pattern="":转换的格式。
yyyy - 四位年 MM = 两位月 dd = 两位日 HH - 24小时制 hh - 12小时制 mm - 分钟 ss - 秒数 SSS - 毫秒




评论