发表于: 2020-06-06 19:17:28
1 1754
任务三深度思考
- time_namelookup:DNS 域名解析的时候,就是把 https://zhihu.com 转换成 ip 地址的过程
- time_connect:TCP 连接建立的时间,就是三次握手的时间
- time_appconnect:SSL/SSH 等上层协议建立连接的时间,比如 connect/handshake 的时间
- time_redirect:从开始到最后一个请求事务的时间
- time_pretransfer:从请求开始到响应开始传输的时间
- time_starttransfer:从请求开始到第一个字节将要传输的时间
- time_total:这次请求花费的全部时间
1. 什么是代码生成,mybatis generator代码生成是怎么实现的,还有什么办法可以生成代码?
Mybatis generator 生成的文件分两大块,共四种:实体(实体类 pojo.java、条件查询类 pojoExample.java)映射(映射文件 pojoMapper.xml、接口 pojoMapper.java)
MBG 连接数据库后会扫描指定的数据库与表,并且得到他们的所有字段、类型、长度、主键信息来建立实体类。
其中字段名会按照配置文件的规则进行格式化,MBG 中有一个类型映射表,根据 mysql 中的类型及长度信息转换为 java 的类型。
其中会遇到一些问题,对于 mysql 中的 int tinyint bigint 来说,长度信息并不会影响他们的存储长度,只会在开启自动填充零的时候对其显示效果产生影响。但是在 MBG 的默认映射表中,tinyint(1) 会转换为 java 中的 boolean。这个时候我们可以通过修改配置文件来改变映射。
在 example 类中,会生成很多条件查询、排序的方法,主要的作用是对 sql 进行拼接,内部的方法非常多,有针对每一个字段的 or and between noteuals eqals 方法,使用的时候可以根据需求进行自由拼接。
另外还可以设置排序方式,当然这部分就需要用户来自定义一段 sql 语句了。
其他的自动生成代码方法:
Velocity 模板引擎快速生成代码
https://www.ibm.com/developerworks/cn/java/j-lo-velocity1/index.html
FreeMarker
http://freemarker.foofun.cn/index.html
2.Mysql 的一般而言应该配置多大的内存, 多大的硬盘 ,多大的连接数?
一般来说 Mysql 的内存设置应该尽量接近物理机的内存,但又要给其他的服务与系统留下足够的内存空间。
Mysql 内存占用计算器:http://www.mysqlcalculator.com/
详解:
key_buffer_size决定了 myisam 索引块缓存区的大小,影响着 myisam 表的存取效率。一般来说应该把 1/4 的可用内存分配给 key_buffer_size
query_cache_size:作用于 select 语句,对其结果集做了缓存,所以不适用于那些更新频繁的表。
innodb_buffer_pool_size:定义了 InnoDB 存储引擎的表数据和索引数据的最大内存缓冲区,可以缓存数据块与索引键。
max_connections:允许的同时客户数量,应该尽量调整为更大的值,否则将会经常出现 too many connections。
3.在端到端的请求当中,建立Http连接需要多久,Model通过JSP转成Json需要多久,Nginx调用Resin需要多久,Service访问DB需要多久,一个Sql语句执行的时间是多久。
使用 curl 的 -w 参数可以获取连接建立过程中各部分所占用的时间,以修真院的官网为例,命令如下:

其中 curl-format.txt 内容如下:
time_namelookup: %{time_namelookup}\n
time_connect: %{time_connect}\n
time_appconnect: %{time_appconnect}\n
time_redirect: %{time_redirect}\n
time_pretransfer: %{time_pretransfer}\n
time_starttransfer: %{time_starttransfer}\n
----------\n
time_total: %{time_total}\n
来自 <https://cizixs.com/2017/04/11/use-curl-to-analyze-request/>
可以算出修真院官网的 DNS 查询时间:17 ms
TCP 连接时间:157-17=140 ms
服务器处理时间:193-157=26 ms
内容传输时间:接近 0 ms
model通过jsp转json怎么算时间我真的没想出来,直接 return modelandview,之后就是渲染都不知道去哪里插入时间戳。
4.什么是Sql注入,应该怎么解决?对于未做SQL注入防范的程序,你可以直接通过调用接口删掉表吗?
用户通过一些特殊的字符串输入使得我们预定义的 sql 语句的语义发生了变化,严重的时候可能会对数据造成损伤。
解决方法有多种:
a,通过替换的方式把我们知道的可能会造成 sql 注入的特殊字符剔除掉
b,不要给应用服务器过高的数据库权限
c,使用预编译的 sql 语句,可以完全避免 sql 注入
5.在内存里拼装数据会节省时间吗?如果不能,为什么要选择单表查询,而不是直接拼装成Sql语句。
不懂这个【内存里拼接数据】是指什么。我理解为多个单表查询(即多个单表数据载入内存后处理得到所需数据)是否比逻辑写入 sql 中由 mysql 直接返回所需数据快。
我觉得还是在 mysql 中直接处理更快,毕竟没有了数传输的耗时。
【为什么选择单表查询,而不是直接拼接成 sql 】我理解为为什么不用 join 或者其他的多表查询方式?
a,不利于写操作,join 执行读操作就会同时锁住多张表,影响其他业务的几率提升了很多。
b,不利于维护,如果其中有表发生了变化(分表),那么需要重写 sql,这个时候多表查询语句的改动可能比较繁琐。
6.为什么一般而言,不允许使用连表查询,不允许使用复杂的Group By等语句,为什么不允许使用存储过程?
优点:
a,简化了代码逻辑
b,减少了不必要的数据传输,毕竟查询完很多数据都是不需要的
缺点:
a,数据表如果由修改那么连表查询就需要做修改,工作量未知
b,连表查询会锁表,不利于写操作
c,sql 中可能会有复杂的嵌套,写完就忘
7.为什么响应时间一般不允许超过200MS,怎么查看一个请求从发起到结束,耗费在什么地方了?
查看 access log,或者自己去关键节点打日志。
第三个问题写了用 curl 来获取建立连接的耗时。
200ms 以内的响应用户体验会比较好吧。
8.为什么要自测,仅仅使用Postman来测试足够吗?什么是本地测试,什么是在开发环境测试?在开发过程中,应该每天部署代码到开发环境吗,为什么?
为什么要自测?因为很多问题在开发阶段就要解决掉,避免给其他人(比如前端)的工作造成困扰。
只用 postman 应该还是不够的,但是目前能满足我的需求。
本地测试:在自己的电脑上启动项目测试,好处是快。
开发环境测试:模拟真实的运行环境进行的测试。
还是应该每天一部署,方便测试,及时发现问题。
9.保存图片有几种方式?什么样的情景下应该使用哪一种?
还没做过图片保存,不过看到有用 MultipartFile、MultipartHttpServletRequest 做图片保存的。
10.为什么要先写单元测试?单元测试应该包括哪些?在正式打包的过程中,什么样的单元测试应该被屏蔽?在Maven里用什么方法可以跳过单元测试,单元测试应该被跳过吗。
在我的学习过程中都是先实现再测试,完全是因为一些方法没有定下来,没法先写测试。我想这也是我今后要努力的方向,项目做好拆分,写好测试单元最后实现。
涉及数据库的写入、删除、更改的测试用力必须要屏蔽掉,我打包都是跳过所有的单元测试编译,主要是部署的数据库与本地的不一致,就算打包进去了测试也通不过。
Maven 跳过单元测试打包的方法:
a,修改 pom 文件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
</build>
b,打包的时候带参数
mvn clean install -Dmaven.test.skip=true
11.为什么提供假数据的时候要求,直接Controller接收请求,在JSP中写死数据返回以用做假数据?为什么提供假数据的时候要求数据完整,有分页尽可能给分页,数据尽可能真实?
因为刚开始开发可能数据库都没有,更别说实体类了,要么用 map list 什么的自己堆一个数据返回,要么用 jsp 写死,我肯定选择用 jsp,用起来非常方便快捷。
一个 controller 加若干 jsp 就能返回假数据,看起来直观,修改起来也方便。
12.为什么要写假数据,前后端联调的时候,应该什么时候商定接口文档,接口文档应该谁来维护,如果不提供假数据,会发生什么问题?
开始项目的时候就要一起定好接口文档。
维护应该还是要由后端来吧。
不提供假数据前端不好调试。
13.接口应该怎么定义?一个页面应该只对应一个接口吗?还是一个实体对应一个接口,让前端去组装数据?两者的使用场景是什么?
遵从 rest 风格。一个页面可以多个接口,也不应该就是一个实体对应一个接口,接口应该根据业务的需求来确定,毕竟软件即服务。
14.多层分类应该怎么设计表结构,分别有什么问题?像文章分类这种需求,如果分类不确定,级别不确定,有可能动态调整,数据量和访问量又比较大,该怎么去设计?
任务三就遇到了这个问题,最终我采用了这样的设计:
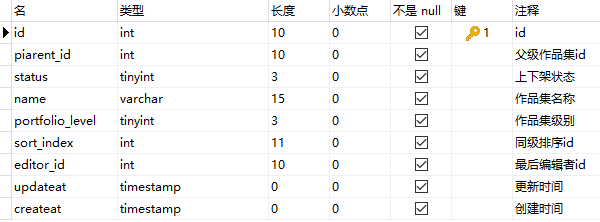
效果如下:
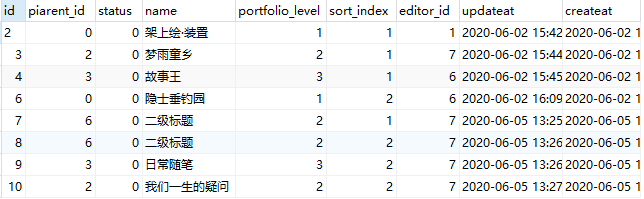
子分类带上父分类的 id,这样分再多层也没有问题,实际使用的时候应该不会超过5层吧。
15.什么是实体表,什么是关系表,一对多和多对多应该怎么设计表?
实体表即对应实体类,可以被实例化。关系表即存储表之间的关联、映射,不被实例化。
一对多:一张表就够了,比如一个学校里有多个学生
一对一:一个人只有一个身份证号码
多对一:多个学生在同一个班级,这时可以加一张关系表,更简单的是学生表加一个班级字段。
多对多:一个班级有多个学生,每个学生都可以选择多个课程。可以拆分为多个映射表。
16.什么是外键,用处是什么,为什么不建议使用外键做关联?
外键:两个表,一个主表,一个从表,主表的主键,放到从表的表格内,然后这个从表和主表就通过外键关联了,这个从表的这个一列和主键有关系的数据,就是从表的外键。目的是控制存储在外键表中的数据,使两张表形成关联。
优点:
a,保障数据的完整性
b,使用数据库的外键约束程序的行为(这条数据不能删,因为他在从表中还有数据)
缺点:性能差
我感觉可以中和一下,开发与测试的时候数据库设置外键但是不用,纯用于约束不规范的业务逻辑,上线的时候不用就好了。
17.什么是数据库范式,是否应该严格遵守范式,什么情况下应该不遵守范式?
数据库范式:看了一下百度百科没看懂··· 知乎上有个回答能让我懂点味道,这里贴一下:
如何理解关系型数据库的常见设计范式? - 刘慰的回答 - 知乎
https://www.zhihu.com/question/24696366/answer/29189700
遵从范式的好处是冗余数据会很少,节约了存储空间,增删改查的时候能够确认数据数是唯一的,只需要对一处做修改。




评论