发表于: 2020-05-26 23:56:26
2 1541
今天完成的事情:深度思考结束,任务一提交了。
明天计划的事情:任务二规划下
遇到的问题:
1.找不到xml配置:
<!--把java文件下的xml文件也编译进去-->
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
2.db.properties 配置文件 ${username} 变量值的问题

因为 Spring 在使用 <context:place-holder> 指定配置文件时候,会先去系统的环境变量中读取。Windows10 系统中正好存在了 username 这个变量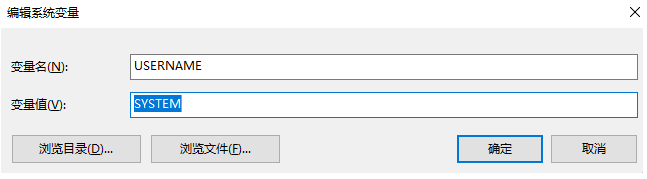
而 SYSTEM 指向了我的计算机用户名 admin。这个问题只有在 windows系统中可能会出现。解决方法就是,将 username 替换成 jdbc.username,然后避免该被覆盖。(以后的配置文件中变量名最好制定前缀,类似于 jdbc.XXX)

参考该文章:https://blog.csdn.net/u013536829/article/details/80027391
3.Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.12.4
写入pom文件,
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.4.2</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
收获:如下
提交我的任务一
回声“#Test1App” >> README.md
git init
git add README.md
git commit -m“首次提交”
git remote add origin https://github.com/hyxcc/Test1App.git
git push -u origin master
如何从git提交到github: https://baijiahao.baidu.com/s?id=1619544681032320225&wfr=spider&for=pc
深度思考
11.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
日志分为操作日志和系统日志
操作日志,主要针对的是用户,例如在Photoshop软件中会记录自己操作的步骤,便于用户自己查看。
系统日志,主要针对的是软件开发人员(包括测试、维护人员),也就是说这部分的日志用户是看不到的,也就是我们通常所说的debug日志。
日志打在何处:
1.程序入口
在入口打印日志是因为这个时候传递进来的参数没有经过任何处理,将它打印在日志文件中能一眼就知道程序的原始数据是否符合我们的预期,是不是传递进来的原始数据就出现 的问题。
2.异常捕获
在异常打印出详细的日志能让你快速定位错误在哪里,例如在程序抛出异常捕获时,在平时我们经常就是直接在控制台打印出堆栈信息e.printStackTrace(),但在实际的生产环境更加艰苦,更别说有IDE来让你查看控制台信息,此时就需要我们将堆栈信息记录在日志中,以便发生异常时我们能准确定位程序在哪里出错。
3.重要信息
这一点可能很宽泛,因为不同的业务逻辑重点可能并不一样,例如在有的重要参数不能为空,此时就需要判断是否为空,如果为空则记录到日志中;还有的例如传递进来的参数经过一系列的算法处理过后,此时也需要打印日志来查看是否计算正确。但切记,尽量不要直接在for循环中打印日志,特别是for循环特别大时,这样你的日志可能分分钟被冲得不见踪迹,甚至带来性能上的影响。
该打什么级别的日志:
日志打印通常有四种级别,从高到底分别是:ERROR、WARN、INFO、DEBUG。
在你的系统中如果开启了某一级别的日志后,就不会打印比它级别低的日志。例如,程序如果开启了INFO级别日志,DEBUG日志就不会打印,但不打印不代表不产生,这在后面会提到。通常在生产环境中开启INFO日志。
INFO级别的日志应该是能帮助测试人员判断这是否是一个真正的bug,而不是自己操作失误造成的。DEBUG级别的日志应该是能帮助开发人员分析定位bug所在的位置。
INFO
- 程序入口,这能让开发人员确认参数是否为自己所为。
- 计算结果,测试关心的程序的输出结果是否符合预期,那么对于计算过程不应该关心,仅给出计算结果就能判断是否符合预期。
DEBUG
对于DEBUG级别,我认为更关心的是过程,以及更为具体的相关信息,因为帮助它的定位在于帮助开发人员定位bug,定位bug就需要较为详细的参数信息才能定位。例如对于某个具体的算法过程,可以使用DEBUG打印,开发人员不仅关心结果,同时在结果不正确时应该能根据DEBUG日志查询计算过程是否出现偏差
WARN
某个不常走到的分支,对于常规的操作是不应该打印WARN日志的,只有在满足某个条件才能走到的分支,且这个分支引起了“警觉”,此时就应该打印WARN日志。
ERROR
毫无疑问出现错误,程序不能继续运行下去就应该打印ERROR日志,这个错误并不是业务上的错误。例如,新增某个用户发现已经存在时,此时虽然新增失败,但不能说程序出现错误就打印ERROR日志;在删除某个用户发现用户已经被锁定时,此时也不能说因为程序不能按照删除的逻辑继续运行下去就应该打印ERROR日志。
在每个类中都定义一个Logger对象,这样的代码相对于业务逻辑来说实际是不想关,此时就可以利用Spring中的AOP面向切面编程打印日志。
日志内容:
应该打印什么内容?打印的内容一定要从实际出发。也就是说如果在实际的生产环境中,你的用户量很大,日志在不停地刷新,如何定位某个用户的整个登录以及后续的操作呢?当然就是根据用户名来跟踪。所以打印内容的第一要素就是要能便于定位;定位过后也许用户在好几个模板中进行操作,还是定位,这个时候定的是模块的位;还有一点当然就是用户操作时的具体参数;最后一点就是用户干了什么。
总结就是,[id, module, params, content](关键字,模块,参数,内容)。
12.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试能够跟踪代码的执行过程,查看到执行和传递的参数是否是预期期望值。还能进入源码查看底层内部的详细信息。
13.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
一般情况下,我们会在程序中打各种log,调试,找出问题,修改,测试,部署到服务器,再测试。但如果在真实项目中的呢,这样做虽然也可以,显然是不方便的。
真实项目中,我们可以通过远程连接的方式,进行调试
远程调试:服务端程序运行在一台远程服务器上,我们可以在本地服务端的代码(前提是本地的代码必须和远程服务器运行的代码一致)中设置断点,每当有请求到远程服务器时时能够在本地知道远程服务端的此时的内部状态。
14.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
领域模型是对领域内的概念类或现实世界中对象的可视化表示。领域模型是对领域内的概念类或现实世界中对象的可视化表示。
1.什么是贫血模型?
简单来说,就是domain ojbect包含了不依赖于持久化的领域逻辑,而那些依赖持久化的领域逻辑被分离到Service层。Service(业务逻辑,事务封装) --> DAO ---> domain object
这种模型的优点:
1、各层单向依赖,结构清楚,易于实现和维护
2、设计简单易行,底层模型非常稳定
这种模型的缺点:
1、domain object的部分比较紧密依赖的持久化domain logic被分离到Service层,显得不够OO
2、Service层过于厚重
2.什么是充血模型?
即认为,绝大多业务逻辑都应该被放在domain object里面(包括持久化逻辑),而Service层应该是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
Service(事务封装) ---> domain object <---> DAO
这种模型的优点:
1、更加符合OO的原则
2、Service层很薄,只充当Facade的角色,不和DAO打交道。
这种模型的缺点:
1、DAO和domain object形成了双向依赖,复杂的双向依赖会导致很多潜在的问题。
2、如何划分Service层逻辑和domain层逻辑是非常含混的,在实际项目中,由于设计和开发人员的水平差异,可能导致整个结构的混乱无序。
3、考虑到Service层的事务封装特性,Service层必须对所有的domain object的逻辑提供相应的事务封装方法,其结果就是Service完全重定义一遍所有的domain logic,非常烦琐,而且Service的事务化封装其意义就等于把OO的domain logic转换为过程的Service TransactionScript。该充血模型辛辛苦苦在domain层实现的OO在Service层又变成了过程式,对于Web层程序员的角度来看,和贫血模型没有什么区别了 。
16.clean,install,package,deploy分别代表什么含义?
1、Mvn compile
执行 mvn compile命令,完成编译操作,执行完毕后,会生成target目录,该目录中存放了编译后的字节码文件。
Mvn clean
执行 mvn clean命令执行完毕后,会将target目录删除。
Mvn test
执行 mvn test命令,完成单元测试操作执行完毕后,会在target目录中生成三个文件夹:surefire、surefire-reports(测试报告)、test-classes(测试的字节码文件)
Mvn package
执行 mvn package命令,完成打包操作执行完毕后,会在target目录中生成一个文件,该文件可以是jar、war等
Mvn install
执行 mvn install命令,完成将打好的jar包安装到本地仓库的操作执行完毕后,会在本地仓库中出现安装后的jar包,方便其他工程引用
Mvn deploy
将打好的包拷贝到远程的repository,使得其他的开发者或者工程可以共享。
17.怎么样能让Maven跳过JUnit?
pom文件中加入

18.为什么要用Log4j来替代System.out.println?
Log4j有三个主要的组件:Loggers(记录器),Appenders (输出源)和Layouts(布局)。这里可简单理解为日志类别,日志要输出的地方和日志以何种形式输出。
Loggers组件在此系统中被分为五个级别:DEBUG、INFO、WARN、ERROR和FATAL。
这五个级别是有顺序的,DEBUG < INFO < WARN< ERROR < FATAL,分别用来指定这条日志信息的重要程度。
Log4j有一个规则:只输出级别不低于设定级别的日志信息。
Appenders 配置日志信息输出。
Layouts 设置日志输出的格式,Layouts提供四种日志输出样式,如根据HTML样式、自由指定样式、包含日志级别与信息的样式和包含日志时间、线程、类别等信息的样式。
log4j的配置文件中有输出到文件的相关配置,这就是它和sout的区别,查找日志信息的时候就可以到相应的日志文件中去查看,如果是sout的话,程序关闭,信息就丢失了。
28.maven是什么,和Ant有什么区别?
Maven是一款跨平台的项目管理工具,作为Apache组织中的一个颇为成功的开源项目,Maven主要是服务于基于Java平台的项目构建、依赖管理和项目信息管理,Maven使用其项目对象模型(POM)和一组插件来构建项目。
Ant是软件构建工具,跨平台的Ant是java的生成工具,在项目的运行编辑打包等过程都需要依赖于 ant 构建工具。
二者的区别:
第一:ant脚本是可以直接运行在maven中的。maven和ant最大的差别就是在于maven的编译以及所有的脚本都有一个基础,就是POM(project object model)。这个模型定义了项目的方方面面,然后各式各样的脚本在这个模型上工作,而ant完全是自己定义,显然maven更胜一筹。
第二:Maven对所依赖的包有明确的定义,如使用那个包,版本是多少,一目了然。而ant则通常是简单的inclde 所有的jar。导致的最终结果就是,你根本无法确定JBoss中的lib下的common-logging 是哪个版本的,唯一的方法就是打开 META-INF 目录下MANIFEST.MF。
第三:Maven是基于中央仓库的编译,即把编译所需要的资源放在一个中央仓库里,如jar,tld,pom,等。当编译的时候,maven会自动在仓库中找到相应的包,如果本地仓库没有,则从设定好的远程仓库中下载到本地。这一切都是自动的,而ant需要自己定义了。这个好处导致的结果就是,用maven编译的项目在发布的时候只需要发布源码,小得很,而反之,ant的发布则要把所有的包一起发布,显然maven又胜了一筹。
第四:maven有大量的重用脚本可以利用,如生成网站,生成javadoc,sourcecode reference,等。而ant都需要自己去写。
第五:maven目前不足的地方就是没有象ant那样成熟的GUI界面,不过mavengui正在努力中。目前使用maven最好的方法还是命令行,又快又方便。




评论