发表于: 2020-05-24 23:33:41
1 1534
今天完成的事情:任务一结束了
明天计划的事情:做深度思考以及任务二
遇到的问题:堆栈溢出,自己改了下大小;今天晚上修改的代码不知道怎么的没有传上去,然后本地也不见了。哈哈
收获:
插入数据的测试
<!--数据源-->
<!--数据源-->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<!--基本配置信息-->
<property name="driverClassName" value="${druid.driver}"/>
<property name="url" value="${druid.url}"/>
<property name="username" value="${druid.username}"/>
<property name="password" value="${druid.password}"/>
<!-- 初始化连接数量 -->
<property name="initialSize" value="${druid.initialSize}" />
<!-- 最小空闲连接数 -->
<property name="minIdle" value="${druid.minIdle}" />
<!-- 最大并发连接数 -->
<property name="maxActive" value="${druid.maxActive}" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="${druid.maxWait}" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="${druid.timeBetweenEvictionRunsMillis}" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="${druid.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="${druid.validationQuery}" />
<property name="testWhileIdle" value="${druid.testWhileIdle}" />
<property name="testOnBorrow" value="${druid.testOnBorrow}" />
<property name="testOnReturn" value="${druid.testOnReturn}" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 如果用Oracle,则把poolPreparedStatements配置为true,mysql可以配置为false。 -->
<property name="poolPreparedStatements" value="${druid.poolPreparedStatements}" />
<property name="maxPoolPreparedStatementPerConnectionSize"
value="${druid.maxPoolPreparedStatementPerConnectionSize}" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="${druid.filters}" />
</bean>druid.properties的文件druid.driver=com.mysql.jdbc.Driver
druid.url=jdbc:mysql://rm-bp12j1c1v42hsx0myso.mysql.rds.aliyuncs.com:3306/mytable?useUnicode=true&characterEncoding=utf-8&useSSL=true
druid.username=root
druid.password=Hyx122567
druid.initialSize=10
druid.minIdle=6
druid.maxActive=50
druid.maxWait=60000
druid.timeBetweenEvictionRunsMillis=60000
druid.minEvictableIdleTimeMillis=300000
druid.validationQuery=SELECT 'x'
druid.testWhileIdle=true
druid.testOnBorrow=false
druid.testOnReturn=false
druid.poolPreparedStatements=false
druid.maxPoolPreparedStatementPerConnectionSize=20
druid.filters=wall,statmapper配置
<insert id="insert" parameterType="java.util.List" useGeneratedKeys="true" keyProperty="id" >
insert into student (number,name,qq,job,university,link,target,brother,createTime,updateTime)
values
<foreach item="item" collection="list" separator=",">
(#{item.number},#{item.name},#{item.qq},#{item.job},#{item.university},#{item.link},#{item.target},#{item.brother},#{item.createTime},#{item.updateTime})
</foreach>
</insert>foreach元素的属性主要有item,index,collection,open,separator,close。
- item:集合中元素迭代时的别名,该参数为必选。
- index:在list和数组中,index是元素的序号,在map中,index是元素的key,该参数可选
- open:foreach代码的开始符号,一般是(和close=")"合用。常用在in(),values()时。该参数可选
- separator:元素之间的分隔符,例如在in()的时候,separator=","会自动在元素中间用“,“隔开,避免手动输入逗号导致sql错误,如in(1,2,)这样。该参数可选。
- close: foreach代码的关闭符号,一般是)和open="("合用。常用在in(),values()时。该参数可选。
- collection: 要做foreach的对象,作为入参时,List对象默认用"list"代替作为键,数组对象有"array"代替作为键,Map对象没有默认的键。当然在作为入参时可以使用@Param("keyName")来设置键,设置keyName后,list,array将会失效。 除了入参这种情况外,还有一种作为参数对象的某个字段的时候。举个例子:如果User有属性List ids。入参是User对象,那么这个collection = "ids".如果User有属性Ids ids;其中Ids是个对象,Ids有个属性List id;入参是User对象,那么collection = "ids.id"
在使用foreach的时候最关键的也是最容易出错的就是collection属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下3种情况:
- 如果传入的是单参数且参数类型是一个List的时候,collection属性值为list .
- 如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array .
- 如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可以封装成map,实际上如果你在传入参数的时候,在MyBatis里面也是会把它封装成一个Map的,map的key就是参数名,所以这个时候collection属性值就是传入的List或array对象在自己封装的map里面的key.
针对最后一条,我们来看一下官方说法:
注意 你可以将一个 List 实例或者数组作为参数对象传给 MyBatis,当你这么做的时候,MyBatis 会自动将它包装在一个 Map 中并以名称为键。List 实例将会以“list”作为键,而数组实例的键将是“array”。
所以,不管是多参数还是单参数的list,array类型,都可以封装为map进行传递。如果传递的是一个List,则mybatis会封装为一个list为key,list值为object的map,如果是array,则封装成一个array为key,array的值为object的map,如果自己封装呢,则colloection里放的是自己封装的map里的key值。
接口
long insert(List<Student> student);@Test
public void insert100W() throws InterruptedException {
//线程池: 提供一个线程队列,队列中保存着所有等待状态的线程。避免了创建与销毁的额外开销,提高了响应的速度。
//引用线程池,创建固定大小的线程池
ExecutorService executorService = Executors.newFixedThreadPool(1000);
//通过CountDownLatch,我们可以导致线程阻塞,直到其他线程完成给定任务。
//
final CountDownLatch latch = new CountDownLatch(1);
executorService.execute(new Runnable() {
public void run() {
long begin = System.currentTimeMillis();
for (int i=1;i<50;i++) {
List<Student> lists = new ArrayList<Student>();
for (int j = 1; j < 10000; j++) {
Student stu = new Student();
stu.setNumber(j);
stu.setName("周星星");
stu.setUniversity("西南财经大学");
stu.setBrother("周正华");
stu.setJob("PM工程师");
stu.setLink("www.jnshu.com");
stu.setTarget("不入IT誓不还");
Long s = Long.valueOf(new Date().getTime());
stu.setCreateTime(s);
stu.setUpdateTime(s);
stu.setQq("1131023043");
synchronized (stu){lists.add(stu);}
}
try{
studentService.insert(lists);
}
catch (Exception e){
e.printStackTrace();
}
}
System.out.println("......1");
latch.countDown();
long end = System.currentTimeMillis();
logger.info("插入50万条数据耗时:" + (end - begin));
}
});
//开始等待,主线程挂起
latch.await();
}Java的concurrent包里面的CountDownLatch其实可以把它看作一个计数器,只不过这个计数器的操作是原子操作,同时只能有一个线程去操作这个计数器,也就是同时只能有一个线程去减这个计数器里面的值。
你可以向CountDownLatch对象设置一个初始的数字作为计数值,任何调用这个对象上的await()方法都会阻塞,直到这个计数器的计数值被其他的线程减为0为止。
CountDownLatch的一个非常典型的应用场景是:有一个任务想要往下执行,但必须要等到其他的任务执行完毕后才可以继续往下执行。假如我们这个想要继续往下执行的任务调用一个CountDownLatch对象的await()方法,其他的任务执行完自己的任务后调用同一个CountDownLatch对象上的countDown()方法,这个调用await()方法的任务将一直阻塞等待,直到这个CountDownLatch对象的计数值减到0为止。
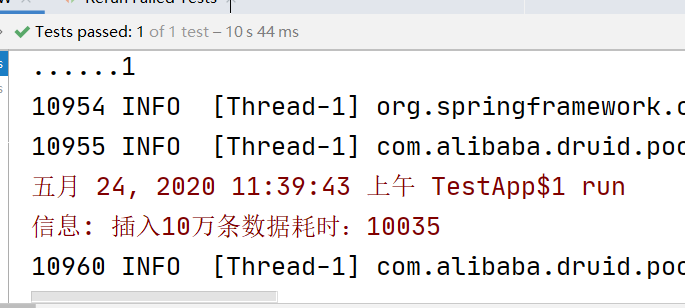 10秒
10秒
 36秒
36秒
 1分钟14秒
1分钟14秒
 10分钟左右
10分钟左右
这样下去预计1亿的数据要花1个半小时多。
检索的时间:
@Test
public void findOne() {
long begin = System.currentTimeMillis();
List<Student> list = studentService.findOne(125487);
for (Student s:list) {
System.out.println(s);
}
long end = System.currentTimeMillis();
logger.info("没有建立索引查找时间:" + (end - begin));
}


差别还是相当的大的。




评论