发表于: 2020-05-19 16:32:23
2 1277
任务一深度思考汇总:
1.Mybatis有哪些常用标签?怎么使用标签来完成动态查询?
以下内容来自 mybatis 文档:https://mybatis.org/mybatis-3/zh/dynamic-sql.html
常用标签:
if
choose ( when, otherwise)
trim ( where, set)
foreach
(a)if
这是很常用的标签,但是通常和 where 等标签一起使用,这里简单写一下单独使用的情况
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
(b)choose where otherwise
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
(c)trim where set
这些标签一般与 if 标签搭配使用
上面的标签都无法解决一个情况:任意选择想查询的字段或不选择任何字段。
仅使用 if 标签(查询失败):
SELECT * FROM BLOG WHERE
仅使用 choose where otherwise 标签(查询失败):
SELECT * FROM BLOG WHERE AND title like ‘someTitle’
这时,我们可以使用 where 标签:
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
where 标签中,会自动去掉拼接后 sql 语句最前面的 AND。
或者我们可以使用 trim 标签自定义一个 where 标签(以下标签与 where 标签等价):
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
</trim>
trim 标签有几个特殊属性:
prefix 增加指定的前缀文本
prefixOverrides 属性会去掉指定的前缀文本
suffix 增加指定后缀文本
suffixOverrides 去除指定的后缀文本
set 语句用于包含需要更新的字段
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
set 标签中,会自动去掉拼接后的 sql 中最后面的逗号。
等价的 trim 表达如下:
<trim prefix="SET" suffixOverrides=",">
...
</trim>
(d)foreach
foreach 用于对集合进行遍历(尤其是构建 IN 语句的时候)
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
WHERE ID in
<foreach item="item" index="index" collection="list"
open="(" separator="," close=")">
#{item}
</foreach>
</select>
foreach 非常强大,可以让我们指定一个集合(任何可以迭代的对象Map,List,set 等),声明可以在元素体内使用的集合项(item)和索引(index)变量。
index 是当前迭代的序号,item 是本次迭代获取到的元素。
2.什么叫反射?反射的坏处是什么?有哪些反射的应用场景?
反射是指程序可以访问,检测和修改本身状态或者行为的一种能力。
在 java 语言中,反射是指在 java 运行时:
1.给定的一个 class 对象,通过反射获取这个 class 对象的所有成员结构
2.给定一个具体的对象,能够动态的调用它的方法以及对任意属性值进行获取和赋值
这种动态获取类的内容,创建对象,以及动态调用对象的方法及操作属性的机制为反射,集是该对象的类型在编译期间是未知,该类的 .class 文件不存在,也可以通过反射直接创建对象
优势:
增加程序的灵活性,避免将固有的逻辑程序写死
代码简洁,可读性强,可以提高代码的复用率
劣势:
相较于直接调用,在大量的情境下反射性能下降
存在一些内部暴露和安全隐患
应用场景:
1. JDBC 的数据库连接
使用 Class.forName() 来加载驱动
2.Spring 框架的使用
通过 xml 配置来装载 Bean 的过程,解析 xml 或者 properties 里面的内容,获取对应的实体类字节码字符串以及相应的属性,使用反射机制获取某个 class 的实例
3.什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
Subversion(SVN) 是一个开源的版本控制系統, 也就是说 Subversion 管理着随时间改变的数据。 这些数据放置在一个中央资料档案库(repository) 中。 这个档案库很像一个普通的文件服务器, 不过它会记住每一次文件的变动。 这样你就可以把档案恢复到旧的版本, 或是浏览文件的变动历史。
TortoiseSVN(小乌龟) 是 Subversion 版本控制系统的一个免费开源客户端。
SVN 中任意多文件与目录的修改作为一次原子操作,每接收到一次提交都会为文件系统创建一个新状态叫做一个版本号,后一个版本号比前一个大 1,初始版本号为 0。
GIT:
分布式存储,每个开发人员本地都有一份克隆,可以断网工作,联网推送到服务器。
按照元数据的方式存储,每一份克隆都有历史版本信息。
版本号是按照文件的内容或者目录计算出的 SHA-1 哈希值,全球唯一,只有发生改变的文件和目录才会更新版本号,没有一个全局版本号。
git 下一旦克隆,那么所有的代码和历史都会被他人知道,不可以分别设置权限。
git 采用哈希值确定版本号,同时也可以确保内容的完整,一旦发生篡改能够及时发现。
SVN:
集中存放在服务器,只能联网工作。
按照版本存放代码,里面没有历史版本信息。
版本号可以推测,全局唯一,无论文件有无更新,每次推送都会更新版本号。
可以按照目录设置权限,安全性更好。
GUI 工具更加友好。
4.什么是AOP,适用于哪些场景,AOP的实现方案有哪些?
AOP 为 Aspect Oriented Programming 的缩写,意为:面向切面编程,通过预编译方式和运行期间动态代理实现程序功能的统一维护的一种技术。AOP是OOP的延续,是软件开发中的一个热点,也是Spring框架中的一个重要内容。利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
适用场景:
记录日志
监控方法运行时间
权限控制
事务管理
实现方案:
静态 AOP(AspectJ)在编译的时候将 AOP 逻辑织入到代码中,需要专有的编译器与织入器。
优点:完成后织入的代码不影响性能
缺点:不够灵活
动态 AOP(JDK 动态代理)在运行期,目标类加载后,为接口动态生成代理类,将切面植入到代理类中。
动态字节码生成:在运行期,目标类加载后,动态构建字节码文件生成目标类的子类,将切面逻辑加入到子类中。
优点:没有接口也可以织入,灵活
缺点:扩展类的实例方法为 final 的时候无法织入代码
自定义类加载器:在运行前,目标加载前,将切面逻辑加到目标字节码中。
可以考虑javassist来实现。Javassist 是一个编辑字节码的框架,可以让你很简单地操作字节码。它可以在运行期定义或修改Class。使用Javassist实现AOP的原理是在字节码加载前直接修改需要切入的方法。
优点:可以对对大部分类织入
缺点:如果用了其他的类加载器则这些类无法织入
5.Map,List,Array,Set之间的关系是什么,分别适用于哪些场景,集合大家族还有哪些常见的类?
Array 数组是固定长度的,并且只能存放同一类型的数据。Java 集合可以存储与操作一组数目不固定的数据,所有的 java 集合类都位于 java.util 包中,并且只能存放引用类型的数据,不能存放基本数据类型。
集合实际上是对数组的扩展
常见的接口:
Collection是最基本的集合接口,声明了适用于JAVA集合(只包括Set和List)的通用方法。 Set 和List 都继承了Conllection。
Set是最简单的一种集合。集合中的对象不按特定的方式排序,并且没有重复对象。
List的特征是其元素以线性方式存储,集合中可以存放重复对象,有顺序。
Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口。从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
6.Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
以下内容摘自:Spring依赖注入的四种方式
IOC (Inversion of Control)控制反转,是一种设计思想。在 java 开发中, IOC 意味着把设计好的对象交给容器管理,而不是传统的在对象内部直接控制。
传统的 java se 程序设计都是通过 new 来创建对象;IOC 则是有一个专门的容器来控制对象的创建;主要是控制外部资源的获取(对象,容器等)
传统的应用程序都是由我们在程序中直接获取依赖对象,这被称为正转;反转就是由容器来帮忙查找、创建以及注入依赖对象,而我们是被动的接受依赖对象,所以是正转;是依赖对象的获取被反转了。
传统开发:

IOC:

在 spring 中有四种依赖注入,分别是:
a 接口注入
b setter 方法注入
c 构造方法注入
d 注解注入
接口注入(没用过,看不懂):
public class ClassA { private <span interfaceb<="" span="" style="word-break: break-all;"><span clzb<="" span="" style="word-break: break-all;">; public void doSomething() { <span ojbect<="" span="" style="word-break: break-all;"> <span obj<="" span="" style="word-break: break-all;">= <span class<="" span="" style="word-break: break-all;">.forName(<span config<="" span="" style="word-break: break-all;">.BImplementation).newInstance(); <span clzb<="" span="" style="word-break: break-all;"> = (<span interfaceb<="" span="" style="word-break: break-all;">)<span obj<="" span="" style="word-break: break-all;">; <span clzb<="" span="" style="word-break: break-all;">.doIt(); } ……
setter 注入(在做 service 与 dao 分开的时候用过,下例摘自当时项目的代码):
spring 配置文件:
<!-- 配置数据库相关参数properties的属性:${url} -->
<context:property-placeholder location="classpath:db.properties" />
<!--配置c3p0连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close">
<property name="driverClass" value="${jdbc.driver}"></property>
<property name="jdbcUrl" value="${jdbc.url}"></property>
<property name="user" value="${jdbc.username}"></property>
<property name="password" value="${jdbc.password}"></property>
</bean>
<!--配置sqlSqlSessionFactory-->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!--注入mybatis核心配置文件-->
<property name="configLocation" value="mybatis-config.xml"></property>
<!--注入数据源-->
<property name="dataSource" ref="dataSource"></property>
</bean>
<!--给 dao 注入上面配置好的 sqlSqlSessionFactory-->
<bean id="discipleDao" class="cn.mogeek.dao.DiscipleDaoImpl">
<property name="sqlSessionFactory" ref="sqlSessionFactory"></property>
</bean>
<!--给 service 注入上面配置好的 dao-->
<bean id="service" class="cn.mogeek.service.ServiceImpl">
<property name="discipleDao" ref="discipleDao"></property>
</bean>
serviceImpl.java
public class ServiceImpl implements Service {
private DiscipleDao discipleDao;
public void setDiscipleDao(DiscipleDao discipleDao){ this.discipleDao = discipleDao; }public DiscipleDao getDiscipleDao(){ return discipleDao; }
···
}
构造器注入:
spring 配置文件(配置文件和 setter 一样,只是在代码中表示依赖的方式不同):
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.1.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.1.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.1.xsd"> <!-- 使用spring管理对象的创建,还有对象的依赖关系 --> <bean id="userDao4Mysql" "com.tgb.spring.dao.UserDao4MysqlImpl"/> <bean id="userDao4Oracle" "com.tgb.spring.dao.UserDao4OracleImpl"/> <bean id="userManager" "com.tgb.spring.manager.UserManagerImpl"> <!-- (1)userManager使用了userDao,Ioc是自动创建相应的UserDao实现,都是由容器管理--> <!-- (2)在UserManager中提供构造函数,让spring将UserDao实现注入(DI)过来 --> <!-- (3)让spring管理我们对象的创建和依赖关系,必须将依赖关系配置到spring的核心配置文件中 --> <constructor-arg ref="userDao4Oracle"/> </bean> </beans>
构造器表示依赖关系的写法:
import com.tgb.spring.dao.UserDao; public class UserManagerImpl implements <span usermanager<="" span="" style="word-break: break-all;">{ private <span userdao<="" span="" style="word-break: break-all;"><span userdao<="" span="" style="word-break: break-all;">; //使用构造方式赋值 public UserManagerImpl(<span userdao<="" span="" style="word-break: break-all;"> <span userdao<="" span="" style="word-break: break-all;">) { this.userDao = <span userdao<="" span="" style="word-break: break-all;">; } <span @override public void addUser(<span string<="" span="" style="word-break: break-all;"> <span username<="" span="" style="word-break: break-all;">, <span string<="" span="" style="word-break: break-all;"><span password<="" span="" style="word-break: break-all;">) { <span userdao<="" span="" style="word-break: break-all;">.addUser(<span username<="" span="" style="word-break: break-all;">, <span password<="" span="" style="word-break: break-all;">); } }
注解方式(这种方式我用过但比较陌生):
spring 中注入依赖可以分为手工装配与自动装配,实际开发中建议使用手工装配,因为自动装配会产生无法预见的结果。
手工装配又分为两种方式:
(a)在 spring 配置文件中,通过 bean 节点配置,然后在代码中用 setter 或者构造器方法注入。
(b)在 java 代码中使用注解的方式进行装配,在代码中加入 @Resource 或者 @Autowired
Autowired 是自动注入,自动在 spring 上下文中找到合适的 bean 来注入
Resource 用来指定名称注入
Qualifier 和 Autowires 配合使用,指定 bean 名称,如下:
@Autowired@Qualifier("userDAO")private UserDAO userDAO;
spring 配置文件:
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd "> <beans> …… <context:annotation-config></context:annotation-config> …… </beans> <bean id="userDao" "com.springtest.dao.impl.UserDAOImpl"></bean> <bean id="userBiz" "com.springtest.biz.impl.UserBizImpl"></bean></beans>
在需要注入依赖的类中,声明一个依赖对象,并且添加注释:
public class UserBizImpl implements UserBiz { <span @resource<="" span="" style="word-break: break-all;">(<span name<="" span="" style="word-break: break-all;">="userDao") private <span userdao<="" span="" style="word-break: break-all;"><span userdao<="" span="" style="word-break: break-all;">= null; public void addUser() { this.userDao.addUser(); } }
区别:
接口注入:具备侵入性,要求组件必须与特定的接口想关联,因此不被看好,实际使用有限。
setter注入:用 setter 方法设定依赖关系比较直观,如果依赖关系较为复杂,那么构造子注入模式的构造函数也会相当庞大。
构造器注入:所有的依赖关系在构造函数中集中体现,组件一旦创建则处于稳定状态。
注解注入:不用在配置文件中配置大量的依赖对象,易于维护。
实际使用时更推荐使用注解注入。
7..JDBCTemplate和JDBC
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API, 可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
JDBCTemplate 是 Spring 对 JDBC 的封装,通俗点说就是 Spring 对 jdbc 的封装的模板, Spring 对数据库的操作在 jdbc 上面做了深层次的封装,使用 spring 的注入功能,可以把DataSource 注入到 JdbcTemplate 之中。
8.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
使用 new 来创建实例有以下弊端:
使用起来非常繁琐,而且需要了解整个依赖链条并全部实例化。
当之前的依赖发生改变的时候之后所有的实例都需要修改。这导致了耦合非常紧密,不利于业务的开发。
这是一种硬编码,违反了面向接口编程的原则。
频繁创建对象,浪费了资源。
使用 IOC 之后,只管向容器索取 bean 即可:
bean 之间解耦,在运行期间会动态的进行依赖设置。
需要更改 dao 的时候只需要修改 daoImpl,不会破坏其他的代码。
不需要手动整理其依赖关系。
9.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
为什么使用 interface:
1.定义了一个统一的接口,方便开发人员并行合作。
2.代码简洁,便于查看
3.需要修改的时候只需要修改其实现,对外暴露的接口不用变
10.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
在实际的运行环境中,总有开发者无法预料甚至无关管控的情况发生,为了不让这些意外情况产生不可预测的后果,我们需要主动处理异常。
另外,有时候一个模块出现的错误在本模块中无法进行处理,需要抛出给调用它的模块来处理,这个时候也就需要调用模块处理异常。
11.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
打印日志应该使用框架,而不是 System.out.print``` ,否则日志不会保存下来,不利于排错。
应该选择正确的日志级别,Log最常用的级别就是DEBUG,INFO,WARN,ERROR。
需要打印的关键信息:
时间、类名及函数名
重要函数的开始结束
重要函数或web接口的每个返回分支
堆栈信息
12.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试可以随意的暂停,查看上下文变量的值来分析具体错误产生的原因。
(IDE 怎么找到源码的不太清楚,只找到了一些原理)
java 的 debug 依赖于 JPDA(Java Platform Debugger Architecture)java 平台调试体系结构。
java 程序运行在 JVM 之上,调试的时候实际上就是向 JVM 来请求当前程序运行的状态,JPDA 就是虚拟机提供的一套 java 调试工具与接口。
JPDA 分为三个部分,分别是Java虚拟机工具接口(JVMTI),Java调试线协议(JDWP)以及Java调试接口(JDI)。
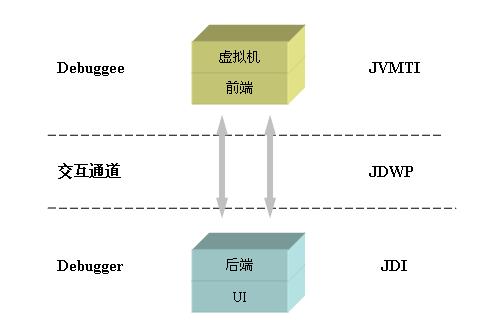
13.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
可以做到,但是不应该这么做。
以下内容摘自:排查Java线上服务故障的方法和实例分析
排查方案:
(1) 紧急处理 :立刻追查最近线上系统是否有更改,立刻回滚更新
(2) 添加监控
(3) 使用JDK性能监控工具 :
(1)首先要查看日志,看看有没有Exception。另外日志中常常有对接口调用,缓存使用的监控告警信息。
(2)看看目前gc的状况如何,使用JDK自带的工具就可以。jstat -gc -h 10 vmid 5000,每5秒打出一次。我遇到过两次线上故障,都是简单的通过jstat就找到了问题。一次是Permanent区分配过小,JVM内存溢出。另一次是发生了过多的Full GC,使得系统停止响应。内存造成的问题通过简单的重启服务就可以使得服务恢复,但重启之后往往很快又出现问题。这个期间你要监控gc,看看期间发生了什么事情。如果是old区增长的过快,就可能是内存泄露。这个时候,你需要看看到底是什么对象占用了你的内存。
(3)jmap -histo vmid > jmap.log,该命令会打出所有对象,包括占用的byte数和实例个数。
(4) 分析源代码。从治标不治本,到治标又治本。
14.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层。
优点是系统的层次结构清楚,各层之间单向依赖,Client->(Business Facade)->Business Logic->Data Access
充血模型: 层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成Client->(Business Facade)->Business Logic->Domain Object->Data Access。
贫血模型只负责存储数据,剥离了业务代码,整个代码结构更加清晰,并且抽象出各种结构,方便开发人员协同工作。
15.为什么不可以用Select * from table?
(a)当数据表的结构发生变化的时候可能查询失败
(b)性能低
(c)引入了不必要的数据,传输效率低
16.clean,install,package,deploy分别代表什么含义?
Maven 有三个互相独立的生命周期
(a)CleanLifeCycle(清理生命周期):在开始构建工作前的清理工作
pre-clean:执行清理之前的工作
clean:一处上一次构建生成的文件
post-clean:执行需要在清理结束后立刻完成的工作
(b)DefaultLifeCycle(部署生命周期):构建的核心部分,编译,测试,打包,部署等
compile:编译项目的源代码
test:使用合适的测试框架运行测试代码
package:将编译好的代码打包成可分发的格式
install:安装包至本地仓库,方便本地的其他项目引用
deploy:分发包至远程仓库,供其他开发人员使用
(c)SiteLifeCycle(生成生命周期):生成项目的报告,站点,发布站点
pre-post:执行一些需要在生成站点文档之前的准备工作
site:生成项目的站点文档
post-site:执行需要在生成站点翁当之后的工作,为部署做准备
site-deploy:将生成的站点文档部署到特定的服务器
17.怎么样能让Maven跳过JUnit?
跳过测试代码的编译
mvn package -Dmaven.test.skip=ture
编译,但是跳过单元测试
mvn package -DskipTest
18.为什么要用Log4j来替代System.out.println?
(a)println 只能输出到控制台,不能保存
(b)println 需要手动指定输出的信息,完成后需要手动注释
(c)log4j 可以分级输出日志,并且可以输出调试信息
19.为什么DB的设计中要使用Long来替换掉Date类型?
(a)mysql 中的 date 分很多种,使用long 统一处理比较方便
(b)使用 long 保存的开销比字符串小
20.自增ID有什么坏处?什么样的场景下不使用自增ID?
(a)当需要合并新旧数据库的时候需要处理 id 冲突
(b)如果新旧数据库的自增 id 类型不同,那么需要修改 id,测试如果有同索引的关联表的话也需要一同修改
21.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
索引是存储的表中一个特定列的值数据结构(最常见的是B-Tree)。通过缩小一张表中需要查询的记录/行的数目来加快搜索的速度。
当某个字段经常需要被查询的时候应该用索引。
22.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
唯一索引:索引列的值不能重复,允许有空值
23.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
如果重复的话插入会报错,也可以不判断给用户一个提示。
24.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
分别在新增数据与更新数据的时候赋值。不应该开放给外部
25.修真类型应该是直接存储Varchar,还是应该存储int?
修真类型并不多,使用 int 性能更好,同时需要维护的映射表也不会经常变动。
26.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
MySQL varchar 的长度对于英文与中文都一样,并不是指字节长度。实际使用是应该够用而尽量短。
区别:
Text 超出768字的部分会与原始行分开存储,最大 65535字节
Varchar 最长 21785个字
Longtext 最大4,294,967,295字节
27.怎么进行分页数据的查询,如何判断是否有下一页?
分页:将数据表中的数据分段展示给用户。
MySQL 分页数据查询语法:
select id,name from table limit 参数1,参数2;
返回值是一个 List,当 size < 参数2 - 参数1 的时候就没有下一页了。
28.maven是什么,和Ant有什么区别?
Maven 是 java 项目的自动化构建工具,并且需要遵守它的约定,代码,包,生成文件的位置都已经确定好,只需要遵守这些规则写出代码就可以 帮助我们编译,测试,打包,发布。
Ant 则没有这么详细的规定,所有的操作都需要手动去创建,配置文件也需要自己去创建




评论