发表于: 2020-05-15 22:42:02
1 1173
今天完成的事情:任务一的深度思考
一、Mybatis有哪些常用标签?怎么使用标签来完成动态查询?
1、Mybaiis常用标签
(1)定义SQL语句:select、insert、delete、update
①、select
id :唯一的标识符
parameterType:传给此语句的参数的全路径名或别名 例:com.Student
resultType :语句返回值类型或别名。如果是集合,那么这里填写的是集合的泛型(resultType 与 resultMap不能并用)
②、resultMap
基本作用:
建立SQL查询结果字段与实体属性的映射关系信息
查询的结果集转换为java对象,方便进一步操作
将结果集中的列与java对象中的属性对应起来并将值填充进去
注意:与java对象对应的列不是数据库中表的列名,而是查询后结果集的列名
主标签:
id:该resultMap的标志
type:返回值的类名,此例中返回Studnet类
子标签:
id:用于设置主键字段与领域模型属性的映射关系,此处主键为ID,对应id
result:用于设置普通字段与领域模型属性的映射关系
③、insert、delete、update
id :唯一的标识符
parameterType:传给此语句的参数的全路径名或别名 例:com.Student
(2)用于控制动态拼接的标签:if、foreach、choose
①、If标签常用于 where、update、insert语句中,通过条件来判断是否执行某个sql语句
②、forch标签用于构建in条件,可在sql中对集合记性迭代,也常用到批量删除\添加等操作中
③、choose标签用于判断when找那个的条件是否成立,如果有一个成立,则choose结束。当choose中所有when的条件都不满足时, 则执行otherwise中的sql语句
(3)、用于格式化输出:where、set、trim
(4)、配置关联关系:collection、association
(5)、用于定义常量:sql、include
2、使用那些标签来完成动态查询
使用where、if,或choose等标签实现动态查询,使用set、if标签实现动态更新
二、什么叫反射?反射的坏处是什么?有哪些反射的应用场景?
1、什么叫反射:对于任意一个类,都能够知道这个类的所有属性和方法; 对于任意一个对象,都能够调用它的任意一个方法和属性;
这种动态获取信息以及动态调用对象的方法的功能称为java语言的反射机制
2、反射的坏处:反射的坏处之一便是内部暴露:当我们使用反射时,其实是在动态的获取信息,那么对于被获取信息的一方来说,其实 是 不安全的,内部的所有东西在反射面前都无处遁形,非常的不安全,相当于我们在别人面前没有秘密可言
3、应用场景 :JDBC的数据库连接、Spring框架的应用
三、什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
1、SVN(Subversion):SVN是开放源代码的版本控制器,它可以让多个人共同开发同一个项目,共用资源
2、小乌龟:TortoiseSVN-1.13.1.28686-x64-svn-1.13.0 安装包,安装之后右键点击桌面 多出来 TortoiseSVN 图标是个小乌龟
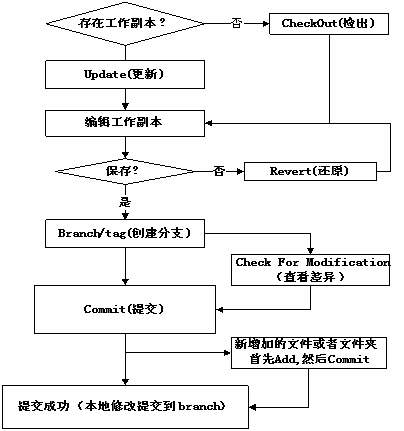
3、SVN的工作原理
4、不需要上传到SVN的文件
(1) .idea 文件夹,此文件夹是用来保存开发工具的设置信息。
(2) .gradle文件夹,此文件夹是用来保存gradle的依赖信息。
(3). build 文件夹,build文件夹是用来保存编译后的文件目录。
(4) .iml 文件,是用来保存开发工具信息。
(5) . local.properties 文件,是用来保存项目依赖信息。
5、git 和SVN的区别
(1) GIT是分布式的,而SVN是集中式的
①、分布式版本控制系统:分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的 时 候,就不需要联网了,因为版本库就在你自己的电脑上。比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A, 这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
②、集中式版本控制系统:版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新 的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。集中式版本控制系统最大的毛病就是必须联网才能工作。
(2)GIT把内容按元数据方式存储,而SVN是按文件:因为git目录是处于个人机器上的一个克隆版的版本库,它拥有中心版本库上所有 的东西,例如标签,分支,版本记录等。
(3)GIT分支和SVN的分支不同:svn会发生分支遗漏的情况,而git可以同一个工作目录下快速的在几个分支间切换,很容易发现未被合 并的分支,简单而快捷的合并这些文件。
(4)GIT没有一个全局的版本号,而SVN有
(5)GIT的内容完整性要优于SVN:GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络 问题时降低对版本库的破坏。
四、什么是AOP,适用于哪些场景,AOP的实现方案有哪些?
1、AOP(Aspect Oriented Programming面向切面编程)
OOP是开发者定义纵向关系,但是并不允许开发者定义横向关系,所以有部分代码是横向的分布在所有对象层次中,例如日志功能等而与它对应的对象的核心功能毫无关系对于其他类型的代码,这种散布在各处的无关的代码被称为横切(cross cutting),在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。为了减少系统的重复代码
就出现了AOP,将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
2、AOP的应用场景:
(1)日志处理
(2)用户登录
(3)权限(Authentication )
(4)性能优化(Performance optimization)
(5)事务(Transactions )
(6)记录跟踪 优化 校准(logging, tracing, profiling and monitoring)
(7)调试(Debugging)
(8)懒加载(Lazy loading)
(9)错误处理(Error handling)
(10)资源池(Resource pooling)
(11)同步(Synchronization)
3、实现方案
(1)JDK动态代理
①、引入依赖,有spring,单元测,日志管理
②、UserDao接口
③、UserDao实现类
④、动态代理
⑤、结果
(2)Cglib动态代理(还没用过)
在实际开发中,可能需要对没有实现接口的类增强,用JDK动态代理的方式就没法实现。采用Cglib动态代理可以对没有实现接口的类 产生代理,实际上是生成了目标类的子类来增强。
①、需要导入Cglib所需的jar包。
②、创建XXXDao类,没有实现任何接口
③、动态代理
④、结果
五、Map,List,Array,Set之间的关系是什么,分别适用于哪些场景,集合大家族还有哪些常见的类?
Array(数组) 有固定大小,不能伸缩
集合类(Map,List,Set)几乎所有的集合都是基于数组来实现,集合是对数组的封装,数组永远比任何一个集合要快,任何集合都比数组功能多,array是基础
Map(映射) 以键值对的形式对元素进行存储。Map 不允许重复键但允许重复值。只允许出现一个空键但允许任意数量的空值。元素都是无序的
List(列表)自动扩展的数组 允许有重复元素 允许任意数量的空值。有序。
Set(集合)没有重复的数组 不允许重复 最多允许一个空值的出现 元素都是无序的
List、Set、Map都是接口,不能实例化
List,Set都是继承自Collection接口,Map则不是
六、Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
1、IOC有两种配置形式:基于XML文件 和 基于Annonation(注解)
2、差别:XML配置降低了耦合,通过配置文件修改程序,使程序更容易扩展。但是配置文件多的话读取和解析需要时间比较长。
Annonation配置机制明显,简单。但是程序的耦合很高,如果要修改程序,那么就需要编译整个工程。
3、在实际开发中,处理的业务量很大,那么就要用XML配置方法,因为XML更加清晰的表明了各个对象之间的关系,各个业务类之间的 调用。
七、JDBCTemplate和JDBC
JDBCTemplate 是对JDBC 的一个封装。JDBC通过Connection这个类获取数据库的连接,然后通过PreparedStatement类处理SQL语句,再通过它的.setObject方法传入数据,最后通过方法.executeUpdate()和.executeQuery()执行更新,最后释放资源。在这个过程中,加载驱动,获取连接对象,释放资源,这些步骤都是必须的,缺一不可,在实际操作中,这些代码都是重复的,使开发效率变低,而JDBCTemplate就是对这几个步骤进行封装,写一遍就足够了,因为是不变的嘛,大大提高了开发效率。
八、Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
1、IOC是一个思想,意思是控制反转,是一种是面向对象编程中的一种设计原则,借助第三方减低计算机代码之间的耦合度,使代码变得更容易扩展
2、用New来创建实例的话增加耦合,会访问到内部属性而且更新的地方比较多,难于维护
九、为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
1、Interface(接口)是一种规范,是抽象的,可以有不同的实现方式。就跟写作文一样,作文给出一个中心思想, 而我们不管是写 议论文, 还是散文只要表达出中心思想就可以
2、好处是跟换实现类的时候们不用更换接口功能,
十、为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
1、有异常影响到了正常运行,当然要处理。
2、Try/Catch使用的场景
(1)程序块中语句可能的异常不能引起其他逻辑中断;
例如:缓存逻辑不能影响正常的逻辑运行,故缓存逻辑应该放在try/catch块中。
(2)必须对异常进行处理,否则会降低用户使用体验。
例如:异常到了Controller层,若不处理则会返回404或500错误页面,因此,必须使用try/catch处理各种异常。
项目如果使用了连接池的话会出现,一般都是在项目启动访问的时候出现
十一、日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
1、日志首先要定义日志级别( DEBUG INFO WARN ERROR 从低到高)
DEBUG级别的日志应该是能帮助开发人员分析定位bug所在的位置。
INFO级别的日志应该是能帮助测试人员判断这是否是一个真正的bug,而不是自己操作失误造成的。一般用在程序入口与计算结果 这 两个地方
WARN 要根据开发的实际情况来确定,是警告的意思,应该在某个不常走到的分支,比如临近数值范围之类的
ERROR 是系统出现错误,需要处理 最严重的的,程序跑不动了。比如数据类型不对
3、关键参数:时间(处理时间,访问时间),用户IP,用户名,用户浏览信息,HTTP状态码,用户渠道,结果
十二、为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试可以看到代码每一步执行的过程,其中包含了我们看不到后台调用.
十三、可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
可以,但是不方便。方案:我认为要先确定是哪个阶段出了问题。是开发?还是别的啥。然后看日志。日志看不出来就DEBUG。
十四、什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
1、贫血模型:贫血模型是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务 逻辑层。
2、充血模型:充血模型将大多数业务逻辑和持久化放在领域对象中,业务逻辑只是完成对业务逻辑的封装、事务和权限等的处理。比较
符合面向对象。
3、为啥强制使用贫血模型
(1)系统的层次结构清楚,各层之间单向依赖。
(2)耦合度低,方便后期的更新与维护。
(3)设计简单,底层模型稳定。
十五、为什么不可以用Select * from table?
1、Select* 会取出表中所有字段,不管字段对调用程序有没有用,这会对扶我去资源造成浪费。导致优化和效率问题,对服务器的性能 产生一定的影响,
2、如果表的结构在以后发生了改变,那么SELECT * 语句可能会取到不正确的数据甚至是出错。
3、执行SELECT * 语句时,select * 语句要对表中所有列进行权限检查,这部分也是开销
4、使用SELECT * 语句将不会使用到覆盖索引,不利于查询的性能优化.(索引覆盖:索引覆盖是一种速度极快,效率极高,业界推荐的一种 查询方式.就是select的数据列只用从索引中就能够获得,不必从数据表中读取,也就是查询列要被所使用的索引覆盖)
5、在文档角度来看,SELECT * 语句没有说明将要取出哪些字段进行操作,不具备针对性,不推荐。
6、用 select * 语句插入一个表,以后表结构修改了,如增加或删除了一列,对代码影响很大,如果只是恰好只获取自己需要的那几列,表结构的修改对你的代码影响就会比较小,便于后期项目维护。
十六、clean,install,package,deploy分别代表什么含义?
mvn clean: 清理项目建的临时文件,一般是模块下的target目录
mvn package:打包到本项目,一般是在项目target目录下
mvn install:打包会安装到本地的maven仓库中
mvn deploy:将打包的文件发布到远程(如服务器)参考,提供其他人员进行下载依赖
十七、怎么样能让Maven跳过JUnit?
</plugin>
十八、为什么要用Log4j来替代System.out.println?
1、Log4j就是帮助开发人员进行日志输出管理的API类库。它最重要的特点就可以配置文件灵活的设置日志信息的优先级、日志信息的输 出目的地以及日志信息的输出格式。
2、Log4j除了可以记录程序运行日志信息外还有一重要的功能就是用来显示调试信息。
3、程序员经常会遇到脱离java ide环境调试程序的情况,这时大多数人会选择使用System.out.println语句输出某个变量值的方法进行调 试。这样会带来一个非常麻烦的问题:一旦哪天程序员决定不要显示这些System.out.println的东西了就只能一行行的把这些垃圾语句 注释掉。若哪天又需调试变量值,则只能再一行行去掉这些注释恢复System.out.println语句。
使用log4j可以很好的处理类似情况。
十九、为什么DB的设计中要使用Long来替换掉Date类型?
二十、自增ID有什么坏处?什么样的场景下不使用自增ID?
1、坏处:
(1)不具有连续性,表中最大值被删除,将不会被重用。就是说会跳号(如果设定的auto_increment_increment是1,那么下一次插 入的id值将会从被删除的最大值算起,也就是被删除的最大值+1)
(2)历史数据表的主键id会与数据表的id重复,两张自增id做主键的表合并时,id会有冲突,但如果各自的id还关联了其他表,这就很不 好操作
(3)很难处理分布式存储的数据表,尤其是需要合并表的情况下,在系统集成或割接时,如果新旧系统主键不同是数字型就会导致修改 主键数据类型,这也会导致其它有外键关联的表的修改,后果同样很严重
2、解决方法
(1)可以用insert 语句直接指定id插入语句
(2)设置自增值 ALTER TABLE table_name AUTO_INCREMENT = 1;(数字1可以是由你自定义设置的自增值,table_name就是你要 使用的数据表)
(3)用truncate table table_name ;语句直接清空表数据并重置自增值(table_name就是你要使用的数据表)
3、啥情况不适用自增ID
如果使用分布式数据库以及数据合并的情况下时不能使用自增ID,能够有其他的字段能作为主键保证唯一性,无需使用自增ID
二十一、什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
1、DB的索引:
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
索引的一个主要目的就是加快检索表中数据的方法,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构。
2、百万级别的数据库就可以看出来性能的差别。
3、需要对字段建索引的情况
(1)在经常需要搜索的列上,可以加快搜索的速度;
(2)在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
(3)在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,
(4)因为索引已经排序,其指定的范围是连续的;
(5)在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
(6)在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
二十二、唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
1、区别
唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复
普通索引的目的是加快对数据的访问速度
2、为了保证数据记录的唯一性建唯一索引,比如根据ID查找数据
二十三、如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要
二十四、CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
CreatAt 应该在数据创建时赋值
UpdateAt 是在更新数据时赋值
查询的话可以调用,如果要对内容进行更改就不可以,只能看不能动。
二十五、修真类型应该是直接存储Varchar,还是应该存储int?
int只能输入整形数据,如 -2,-3 ,0,2,3
Varchar可以输入汉字,字母,当然前提是得 用“ ” 括起来 比如:“1” ,“JAVA”, “前端”
Varchar 因为 用数字 无法直观的表达修真类型。
二十六、varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
根据实际业务数据确定一个合适的长度
原则:描述或者备注这些不加索引的字段可以留更大的长度
不要超过最大长度
还有说定义字段长度为4或8的倍数的,这样据说可以做到内存对齐。但是字符长度少于 4 咋办?比如 是或者否,只能填一个
mysql5.0以上的版本中varchar数据类型的长度支持到了65535字节。
三者都可存储可变长度数据
Varchar在mysql5.0以上的版本中支持到了65535字节。可以有默认值
LongText的最大长度是可以存储4294967295 (2^32 – 1) 个字符。适合存储大内容
能用Varchar就不要用别的
二十七、怎么进行分页数据的查询,如何判断是否有下一页?
物理分页:
sql语句:select * from 表名 limit 起始记录数-1,显示的记录数;
注意:如果从第1条记录开始查询,limit 后面跟的数字是要查询记录的起始数减1
例子 查询student表里第1个记录至后10条记录
select * from student limit 0,10;
总记录数/显示记录数,会得到一个大于等于某数的结果,所以总页数就是向上取整得到的数字,只要大于这个数字,就没有有下一页了、
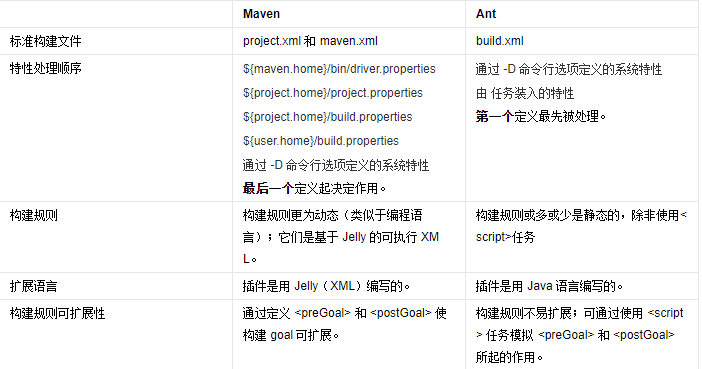
二十八、maven是什么,和Ant有什么区别?
Maven是可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理软件。
今日一题(不上昨天的一题)
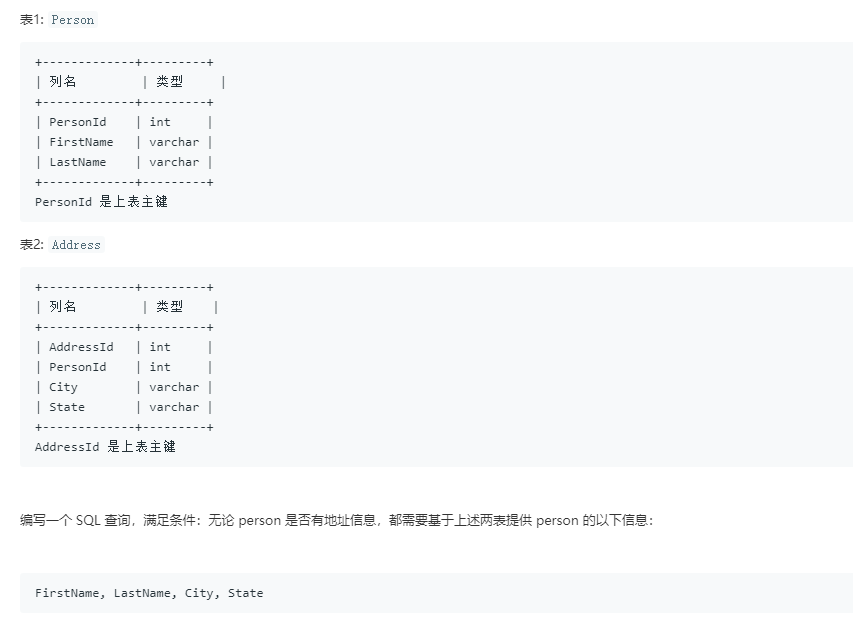
这道题用到了两表合并的知识,之前没学过,今天学一下
INNER JOIN ( JOIN) 将两个表中列名 内容 一样的合并在一起 如果表1中的内容在表2 中没有,则不会显示
格式:
SELECT 列名
FROM 表1
INNER JOIN 表2
ON 表1.列名 = 表2.列名
LEFT JOIN (LEFT OUTER JOIN) 如果表1中的内容在表2中没有,也会显示值,不过为null 以表1 为主导,优先显示表1
格式:
SELECT 列名
FROM 表1
LEFT JOIN 表2
ON 表1.列名 = 表2.列名
RIGHT JOIN(RIGHT OUTER JOIN) 如果表2中的内容在表1中没有,也会显示值,不过为null 以表2为主导,优先显示表2
格式:
SELECT 列名
FROM 表1
RIGHT JOIN 表2
ON 表1.列名 = 表2.列名
FULL JOIN 显示所有
格式:
SELECT 列名
FROM 表1
FULL OUTER JOIN 表2
ON 表1.列名 = 表2.列名
代码如下
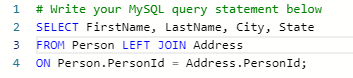
结果正确

尝试RIGHT JOIN
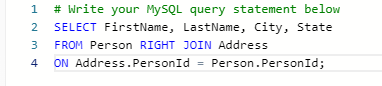
结果错误

第二题

没思路...然后师兄提醒将一张表看成两张表,这个时候用到了AS emmmm没见过,去学下
列的SQL别名语法
SELECT 列名 AS 别名
FROM 表名
表的SQL别名语法
SELECT 列名
FROM 表名 AS别名
先执行 SELECT *FROM Employee AS a,
Employee AS b,
结果是显示出了这样的一张表
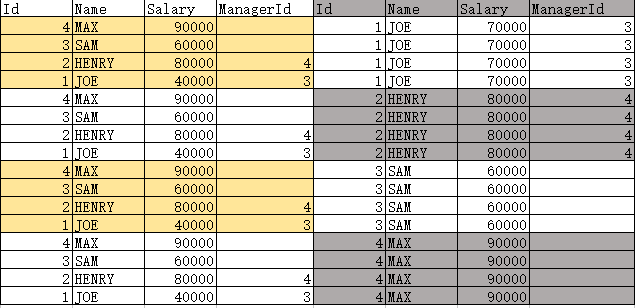
看出来是4组
代码如下
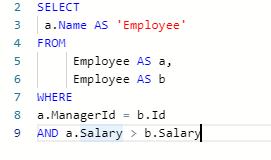
明天再想
明天计划的事情:任务一的代码还有哪些需要写的,然后准备任务二




评论