发表于: 2020-05-04 23:17:52
1 1263
6.Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
以下内容摘自:Spring依赖注入的四种方式
IOC (Inversion of Control)控制反转,是一种设计思想。在 java 开发中, IOC 意味着把设计好的对象交给容器管理,而不是传统的在对象内部直接控制。
传统的 java se 程序设计都是通过 new 来创建对象;IOC 则是有一个专门的容器来控制对象的创建;主要是控制外部资源的获取(对象,容器等)
传统的应用程序都是由我们在程序中直接获取依赖对象,这被称为正转;反转就是由容器来帮忙查找、创建以及注入依赖对象,而我们是被动的接受依赖对象,所以是正转;是依赖对象的获取被反转了。
传统开发:

IOC:

在 spring 中有四种依赖注入,分别是:
a 接口注入
b setter 方法注入
c 构造方法注入
d 注解注入
接口注入(没用过,看不懂):
public class ClassA {
private InterfaceB clzB;
public void doSomething() {
Ojbect obj = Class.forName(Config.BImplementation).newInstance();
clzB = (InterfaceB)obj;
clzB.doIt();
} ……
setter 注入(在做 service 与 dao 分开的时候用过,下例摘自当时项目的代码):
spring 配置文件:
<!-- 配置数据库相关参数properties的属性:${url} -->
<context:property-placeholder location="classpath:db.properties" />
<!--配置c3p0连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close">
<property name="driverClass" value="${jdbc.driver}"></property>
<property name="jdbcUrl" value="${jdbc.url}"></property>
<property name="user" value="${jdbc.username}"></property>
<property name="password" value="${jdbc.password}"></property>
</bean>
<!--配置sqlSqlSessionFactory-->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!--注入mybatis核心配置文件-->
<property name="configLocation" value="mybatis-config.xml"></property>
<!--注入数据源-->
<property name="dataSource" ref="dataSource"></property>
</bean>
<!--给 dao 注入上面配置好的 sqlSqlSessionFactory-->
<bean id="discipleDao" class="cn.mogeek.dao.DiscipleDaoImpl">
<property name="sqlSessionFactory" ref="sqlSessionFactory"></property>
</bean>
<!--给 service 注入上面配置好的 dao-->
<bean id="service" class="cn.mogeek.service.ServiceImpl">
<property name="discipleDao" ref="discipleDao"></property>
</bean>
serviceImpl.java
public class ServiceImpl implements Service {
private DiscipleDao discipleDao;
public void setDiscipleDao(DiscipleDao discipleDao){ this.discipleDao = discipleDao; }
public DiscipleDao getDiscipleDao(){ return discipleDao; }
···
}
构造器注入:
spring 配置文件(配置文件和 setter 一样,只是在代码中表示依赖的方式不同):
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.1.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.1.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.1.xsd">
<!-- 使用spring管理对象的创建,还有对象的依赖关系 -->
<bean id="userDao4Mysql" class="com.tgb.spring.dao.UserDao4MysqlImpl"/> <bean id="userDao4Oracle" class="com.tgb.spring.dao.UserDao4OracleImpl"/>
<bean id="userManager" class="com.tgb.spring.manager.UserManagerImpl"> <!-- (1)userManager使用了userDao,Ioc是自动创建相应的UserDao实现,都是由容器管理-->
<!-- (2)在UserManager中提供构造函数,让spring将UserDao实现注入(DI)过来 -->
<!-- (3)让spring管理我们对象的创建和依赖关系,必须将依赖关系配置到spring的核心配置文件中 -->
<constructor-arg ref="userDao4Oracle"/>
</bean> </beans>
构造器表示依赖关系的写法:
import com.tgb.spring.dao.UserDao; public class UserManagerImpl implements UserManager{
private UserDao userDao;
//使用构造方式赋值 public UserManagerImpl(UserDao userDao) {
this.userDao = userDao;
}
@Override
public void addUser(String userName, String password) { userDao.addUser(userName, password);
} }
注解方式(这种方式我用过但比较陌生):
spring 中注入依赖可以分为手工装配与自动装配,实际开发中建议使用手工装配,因为自动装配会产生无法预见的结果。
手工装配又分为两种方式:
(a)在 spring 配置文件中,通过 bean 节点配置,然后在代码中用 setter 或者构造器方法注入。
(b)在 java 代码中使用注解的方式进行装配,在代码中加入 @Resource 或者 @Autowired
Autowired 是自动注入,自动在 spring 上下文中找到合适的 bean 来注入
Resource 用来指定名称注入
Qualifier 和 Autowires 配合使用,指定 bean 名称,如下:
@Autowired@Qualifier("userDAO")private UserDAO userDAO;
spring 配置文件:
<?xml version="1.0" encoding="UTF-8"?><beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd "> <beans>
……
<context:annotation-config></context:annotation-config>
…… </beans> <bean id="userDao" class="com.springtest.dao.impl.UserDAOImpl"></bean> <bean id="userBiz" class="com.springtest.biz.impl.UserBizImpl"></bean></beans>
在需要注入依赖的类中,声明一个依赖对象,并且添加注释:
public class UserBizImpl implements UserBiz {
@Resource(name="userDao")
private UserDAO userDao = null; public void addUser() {
this.userDao.addUser();
} }
区别:
接口注入:具备侵入性,要求组件必须与特定的接口想关联,因此不被看好,实际使用有限。
setter注入:用 setter 方法设定依赖关系比较直观,如果依赖关系较为复杂,那么构造子注入模式的构造函数也会相当庞大。
构造器注入:所有的依赖关系在构造函数中集中体现,组件一旦创建则处于稳定状态。
注解注入:不用在配置文件中配置大量的依赖对象,易于维护。
实际使用时更推荐使用注解注入。
7..JDBCTemplate和JDBC
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API, 可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
JDBCTemplate 是 Spring 对 JDBC 的封装,通俗点说就是 Spring 对 jdbc 的封装的模板, Spring 对数据库的操作在 jdbc 上面做了深层次的封装,使用 spring 的注入功能,可以把DataSource 注入到 JdbcTemplate 之中。
8.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
使用 new 来创建实例有以下弊端:
使用起来非常繁琐,而且需要了解整个依赖链条并全部实例化。
当之前的依赖发生改变的时候之后所有的实例都需要修改。这导致了耦合非常紧密,不利于业务的开发。
这是一种硬编码,违反了面向接口编程的原则。
频繁创建对象,浪费了资源。
使用 IOC 之后,只管向容器索取 bean 即可:
bean 之间解耦,在运行期间会动态的进行依赖设置。
需要更改 dao 的时候只需要修改 daoImpl,不会破坏其他的代码。
不需要手动整理其依赖关系。
9.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
为什么使用 interface:
1.定义了一个统一的接口,方便开发人员并行合作。
2.代码简洁,便于查看
3.需要修改的时候只需要修改其实现,对外暴露的接口不用变
10.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
在实际的运行环境中,总有开发者无法预料甚至无关管控的情况发生,为了不让这些意外情况产生不可预测的后果,我们需要主动处理异常。
另外,有时候一个模块出现的错误在本模块中无法进行处理,需要抛出给调用它的模块来处理,这个时候也就需要调用模块处理异常。
11.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
打印日志应该使用框架,而不是 System.out.print``` ,否则日志不会保存下来,不利于排错。
应该选择正确的日志级别,Log最常用的级别就是DEBUG,INFO,WARN,ERROR。
需要打印的关键信息:
时间、类名及函数名
重要函数的开始结束
重要函数或web接口的每个返回分支
堆栈信息
12.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试可以随意的暂停,查看上下文变量的值来分析具体错误产生的原因。
(IDE 怎么找到源码的不太清楚,只找到了一些原理)
java 的 debug 依赖于 JPDA(Java Platform Debugger Architecture)java 平台调试体系结构。
java 程序运行在 JVM 之上,调试的时候实际上就是向 JVM 来请求当前程序运行的状态,JPDA 就是虚拟机提供的一套 java 调试工具与接口。
JPDA 分为三个部分,分别是Java虚拟机工具接口(JVMTI),Java调试线协议(JDWP)以及Java调试接口(JDI)。
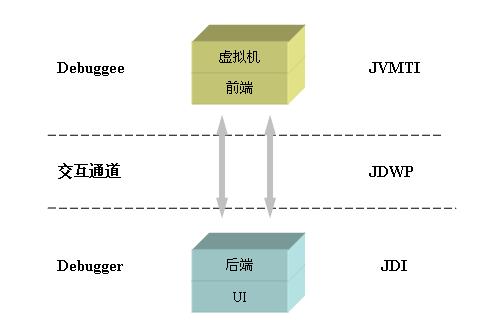
13.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
可以做到,但是不应该这么做。
以下内容摘自:排查Java线上服务故障的方法和实例分析
排查方案:
(1) 紧急处理 :立刻追查最近线上系统是否有更改,立刻回滚更新
(2) 添加监控
(3) 使用JDK性能监控工具 :
(1)首先要查看日志,看看有没有Exception。另外日志中常常有对接口调用,缓存使用的监控告警信息。
(2)看看目前gc的状况如何,使用JDK自带的工具就可以。jstat -gc -h 10 vmid 5000,每5秒打出一次。我遇到过两次线上故障,都是简单的通过jstat就找到了问题。一次是Permanent区分配过小,JVM内存溢出。另一次是发生了过多的Full GC,使得系统停止响应。内存造成的问题通过简单的重启服务就可以使得服务恢复,但重启之后往往很快又出现问题。这个期间你要监控gc,看看期间发生了什么事情。如果是old区增长的过快,就可能是内存泄露。这个时候,你需要看看到底是什么对象占用了你的内存。
(3)jmap -histo vmid > jmap.log,该命令会打出所有对象,包括占用的byte数和实例个数。
(4) 分析源代码。从治标不治本,到治标又治本。




评论