发表于: 2020-04-30 22:45:35
1 1371
今天完成的事情:今天深度思考完成了一些
明天计划的事情:明天还是要深度思考以及看下java基础
遇到的问题:今天一直没有搞懂那个Long类型怎么在设计表中设计,看了课堂小视频后,发现说的是在开发中DB设计中对创建修改时间的类型为Long,
还有就是小课堂的师兄声音太小了
收获:如下知识,阅读参考了许多师兄的日报来安排自己的进度。
1.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引、
索引:
索引就像书的目录, 通过书的目录就准确的定位到了书籍具体的内容,但是详细理解索引原理必须清楚一种数据结构「平衡树」(非二叉),也就是b tree或者 b+ tree,有的数据库也使用哈希桶作用索引的数据结构 , 然而, 主流的RDBMS都是把平衡树当做数据表默认的索引数据结构。这里画个重点,数据结构的平衡树等相关内容需要去了解学习下。
多大数据量才有差别,什么情况下建立索引
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
索引分类:
1、普通索引(INDEX)最基本的索引,它没有任何限制,用于加速查询。
创建方法:
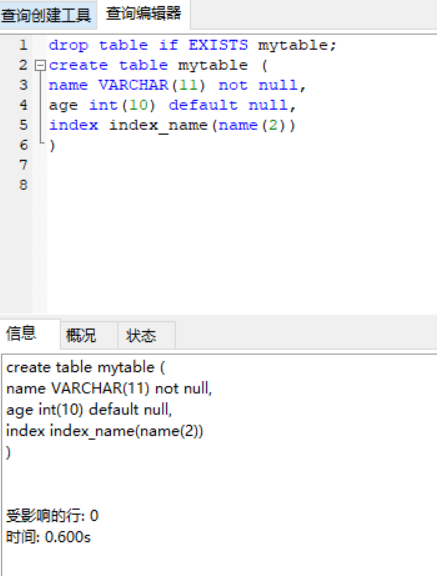
a. 建表的时候一起创建
CREATE TABLE mytable ( name VARCHAR(32) , INDEX index_mytable_name (name) );
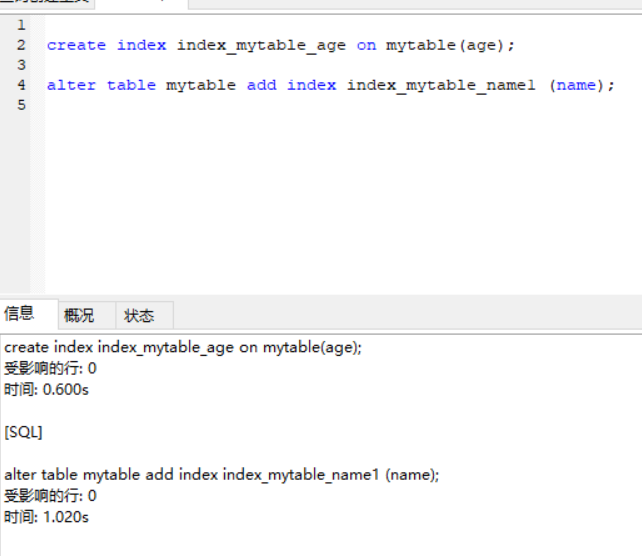
b. 建表后,直接创建索引
CREATE INDEX index_mytable_name ON mytable(name);
c. 修改表结构
ALTER TABLE mytable ADD INDEX index_mytable_name (name);
注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
2、唯一索引(UNIQUE )
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建方法:
a. 建表的时候一起创建
CREATE TABLE mytable ( `name` VARCHAR(32) , UNIQUE index_unique_mytable_name (`name`) );
b. 建表后,直接创建索引
CREATE UNIQUE INDEX index_mytable_name ON mytable(name);
c. 修改表结构
ALTER TABLE mytable ADD UNIQUE INDEX index_mytable_name (name);
注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
3、主键索引(PRIMARY KEY)
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。
创建方法:
a. 建表的时候一起创建
CREATE TABLE mytable ( `id` int(11) NOT NULL AUTO_INCREMENT , `name` VARCHAR(32) , PRIMARY KEY (`id`) );
b. 修改表结构
ALTER TABLE test.t1 ADD CONSTRAINT t1_pk PRIMARY KEY (id);
注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
4、组合索引(INDEX index_mytable_id_name (`id`,`name`) ))
指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
创建方法:
a. 建表的时候一起创建
CREATE TABLE mytable ( `id` int(11) , `name` VARCHAR(32) , INDEX index_mytable_id_name (`id`,`name`) );
b. 建表后,直接创建索引
CREATE INDEX index_mytable_id_name ON mytable(id,name);
c. 修改表结构
ALTER TABLE mytable ADD INDEX index_mytable_id_name (id,name);
5、全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。
fulltext索引配合match against操作使用,而不是一般的where语句加like。
它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。
创建方法:
a. 建表的时候一起创建
CREATE TABLE `article` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(250) NOT NULL , `contents` text NULL , `create_at` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), FULLTEXT (contents) );
b. 建表后,直接创建索引
CREATE FULLTEXT INDEX index_article_contents ON article(contents);
c. 修改表结构
ALTER TABLE article ADD FULLTEXT INDEX index_article_contents (contents);
创建的方法大同小异。
学习的内容来源https://www.cnblogs.com/aspwebchh/p/6652855.html /以及小课堂
2.为什么DB的设计中要使用Long来替换掉Date类型?
MySQL中的表示时间的类型
date:日期,占用三个字节,1000-01-01——9999-12-31
datetime:日期+时间,1000-01-01 00:00:00” 到“9999-12-31 23:59:59,占用8个字节,datetime类型适合用来记录数据的原始的创建时间,因为无论你怎么更改记录中其他字段的值,datetime字段的值都不会改变,除非你手动更改它。
timestamp:日期+时间,占用4个字节,“19700101080001——20380119111407,timestamp类型适合用来记录数据的最后修改时间,因为只要你更改了记录中其他字段的值,timestamp字段的值都会被自动更新。
MySQL中的bigint类型
bignit,表示从-2^63到2^63-1(即从-9,223,372,036,854,775,808到 9,223,372,036,854,775,807)之间的整数,它占用了八个字节的存储空间。
3.常见问题
1.java中对时间处理的类比较混乱,处理时间的类有:java.util.Date,java.sql.Date ,java.sql.Time ,java.sql.Timestamp,java.util.Calendar ,java.util.TimeZone
2.时区,在获取当前时间的时候,各个地区在同一个时间点会有不同的时间表示
3.精度,将java.util.Date转为java.sql.Date时候,日期的时分秒会被去掉,数据的精度发生变化了。而JDBC中定义接口时候,用的是java.sql.Date,而我们常常用到的Date都是java.util.Date,这往往导致一些转换过程中发生误差。java.sql.Timestamp类,它保持了日期数据原有的精度。可以实现和java.util.Date的无损转换。但是Timestamp这个类在一些预定义SQL中常常会出问题
java.sql.Date,在JDBC接口中使用了,如果对其进行修改,JDBC接口规范也要改,那么将引发各个数据库厂商对数据库驱动也要改,这是不可接受的。
4.解决方案
将date类型转换为long类型
1.有利于计算时间差
2.方便java与数据库之间的传输
5.编码实战
可以通过long login_at = System.currentTimeMillis()获得当前时间的long类型
也可以通过Date date1=new Date()来获得当前时间,再用long time=date1.getTime()将其转化为long类型。
然后在数据库中的相应字段设置类型为bigint即可,在数据库中取得数据后,可以在转为相应的时间格式。
链接:https://www.jianshu.com/p/9b67a447467b
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




评论