发表于: 2020-03-24 06:08:41
3 1261
今天完成的事情
今天是一个重要的日子,我完成了任务一,用了几个月,我悟性比较低,一直看师兄的报告,一步一步来,一个月实在做不完,超时了,又加了一个月,这才又加入了一个班,所以这是最后一篇日报了。
我把最终的报告的代码分成四个项目并且上传到github上
1.第一个项目使用了是java的基础学习,jdbctemplate的基本使用,代码写得稍微乱了一些,因为纷纷扰扰的都写了
2.第二个项目是任务17,是非常重要的一部分,分别使用jdbctemplate和mybatis连接数据库。在这里我分别是现在了增删改查,查中是现在单条查询,多条查询,单条件模糊查询,多条件模糊查询,以及根据人名查询,根据ID查询。
3.第三个项目主要针对的是阿里云上的人物,添加10,1000,1000000,30000000,2000000000条数据我会将jar包一起放进去。
4,第四个项目是查漏补缺,将之前的spring mybatis 结合以及修改了日期的获取和显示,方式,在项目二,我是用timestamp,这样很方便,能实现各种查询,但是任务要求的是Long,所以我在项目四中实现了用Long存入数据库,但是显示的是date类型的日期,这里要感谢师兄的帮助。并且学习了注解和XML两种代码编写。一点一点满足任务一的验收标准。
关于任务一的深度思考:
1.Mybatis有哪些常用标签?怎么使用标签来完成动态查询?
共有if ,where, set choose ,foreach 五个标签,他们的功能如下
foreach:标签,遍历传入的List、collection或map参数,依次使用集合中的元素执行sql语句。
2.什么叫反射?反射的坏处是什么?有哪些反射的应用场景?
反射即动态获取对象信息和调用对象功能。
会降低反射功能
应用于逆向代码
3.什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
Git和svn都市代码管理该工具,git是分布式管理,SVN相对集中,他们的却别可以入下图
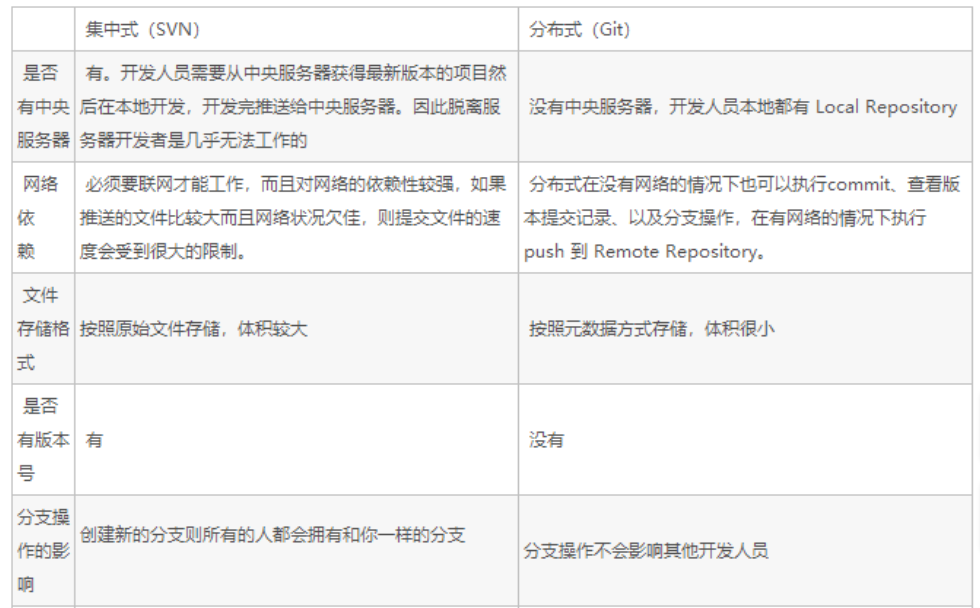
4.什么是AOP?
答:面向切面编程
5.Map,List,Array,Set之间的关系是什么?
答:Map,List和Set是接口,Array是数组
6.Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
答:目前会的就是xml设置bean的方式和注解方式,注解更加方便,不需要手动设置bean,但是由于报错比较多代码中用的还是bean方式。
7.JDBCTemplate和JDBC
答:JDBCTemplate将一些数据库操作函数封装起来,使其相较于JDBC更具有操作性。
8.Spring中的IOC是什么意思?
答:控制反转
9.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
答:接口是一种规范,实现类按照接口规范去实现其方法。将具体操作封装起来,不暴露给调用者,增加了安全性。每次只要调用就可以了,减少了代码量,提高运算速度。
10.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发生一次?
答:在任务一中,我主要感觉处理异常是为了让异常跳过去继续运行,如果不处理异常,就停止报错,降低开发效率
11.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
答:目前对日志打印相对生疏,有待后续学习
12.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
答:可以一步一步找到问题所在,落叶归根,寻根知底,
13.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
答:应该可以吧,只要有权限就可以,没有做过真实的项目,有待后续学习
14.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
15.为什么不可以用Select * from table?
答:数据量太大了,就比如2000000000条数据,显示上都是问题,可以但是不推荐
16.clean,install,package,deploy分别代表什么含义?
答:1.清理目录下生成的target文件
2.target下打的包放到本地仓库
3.打包到项目的target下
4.打包的文件发布到远程仓库
17.怎么样能让Maven跳过JUnit?
答:使用maven.test.skip
18.为什么要用Log4j来替代System.out.println?
答:可以灵活设置输出的日志格式,以过滤和获取需要的信息。
19.为什么DB的设计中要使用Long来替换掉Date类型?
答:应该是数据稳定性更高,但是不用考虑时差,但是随之而来的就是显示起来
有时候不方便。
20.自增ID有什么坏处?什么样的场景下不使用自增ID?
答:因为自动增长,在对其进行操作可能会产生冲突,我就遇到了好几次。甚至是新旧系统并行存在
21.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
答:索引就像是一本书的目录,我在尝试过程中1000000条数据不用索引,0.29秒,用了索引0.01秒,数据量越大,索引的效果越明显,但是随之而来的是插入这1000000跳数据需要的时间也更长了
22.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
答:唯一索引是唯一的,普通索引列的值可以频繁插入
23.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
答:不需要,存在数据库会报错
24.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
答:分别在创建表和修改表时被赋值,不能提供给外部接口,为了安全
25.修真类型应该是直接存储Varchar,还是应该存储int?
答:字数不多且为汉字,用varchar更好一点
任务总结:
任务总结:(任务进度是否符合预期,是否延期,如果延期,原因是什么,如何避免下次继续延期)
任务延期约90,因为悟性不好,学东西总是学不会,看书看了很久还是看不懂,自闭接受了心理治疗了一段时间,在医院心理治疗以后,终于重新起来面对并完成任务一,为了避免下次继续延期,我要增加自己的抗压能力,继续努力,成为一名合格的码农,活得更好的未来
明日计划的事
1,准备和师兄沟通,希望任务一能够通过,心里也能好受些,准备着手任务二
2.听说任务二需要springmvc,所以准备看springmvc
遇到的问题
1.修改代码时发现xml文件部分地方不规范,已经改正
2.一开始不明白注解的意思,后来渐渐明白了
3.解决了打包,并把包放在服务器上运行的问题
收获
1.任务一让我熟悉了java,mysql,spring,mybatis,jdbctemplate,xml文件编写,已经项目开发的基本结构有了大致的了解,后续的学习还应该在后面的任务中越学越多




评论