发表于: 2020-02-20 18:57:20
1 1149
今天完成的事情:
* main1000次调用
* 测试DB十万数据和三千万数据
测试main中1000个调用
1)创建maven工程
main/java中创建 durid包和uitls包
2)写连接池工具类
utils包中的JDBCUtils类
package utils;import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;import java.io.IOException;import java.sql.Connection;import java.sql.ResultSet;import java.sql.SQLException;import java.sql.Statement;import java.util.Properties;public class JDBCUtils { /** * 静态代码: * 加载配置:Properties->pro * 创建druid连接池:DruidDataSourceFactory.createDataSource(pro) * 方法: * getConnection():返回druid连接池的连接并忽略SQL异常 * close():关闭Statement和Connection * close():关闭ResultSet,Statement和Connection * getDataSource():返回druid连接池对象 */ private static DataSource ds; static { try{ Properties pro = new Properties(); pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties")); ds = DruidDataSourceFactory.createDataSource(pro); } catch (IOException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } public static Connection getConnection() throws SQLException { return ds.getConnection(); } public static void close(Statement stmt, Connection conn) { close(null,stmt,conn); } public static void close(ResultSet rs, Statement stmt, Connection conn) { if(rs != null) { try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } if(stmt != null) { try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } } if(conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } public static DataSource getDataSource(){ return ds; }}
3)druid.properties
driverClassName=com.mysql.jdbc.Driverurl=jdbc:mysql://127.0.0.1:3306/jnshuusername=rootpassword=123456#初始化连接数量initialSize=5maxActive=1000maxWait=3000
4)在druid包中新建DruidDemo2.class (/src/main/java/druid/DruidDemo2.class)
写一个1000的循环,在循环体中创建连接。直接调用getConnection()
package druid;import java.sql.Connection;import java.sql.SQLException;import utils.JDBCUtils;public class DruidDemo2 { /** * * @param args * @throws SQLException * 循环体中创建连接 */ public static void main(String[] args) throws SQLException { for (int i = 1; i <= 1000; i++) { Connection conn = JDBCUtils.getConnection(); System.out.println(i+"::"+conn); } }}
5)运行结果:在404个连接时,报错太多连接了。
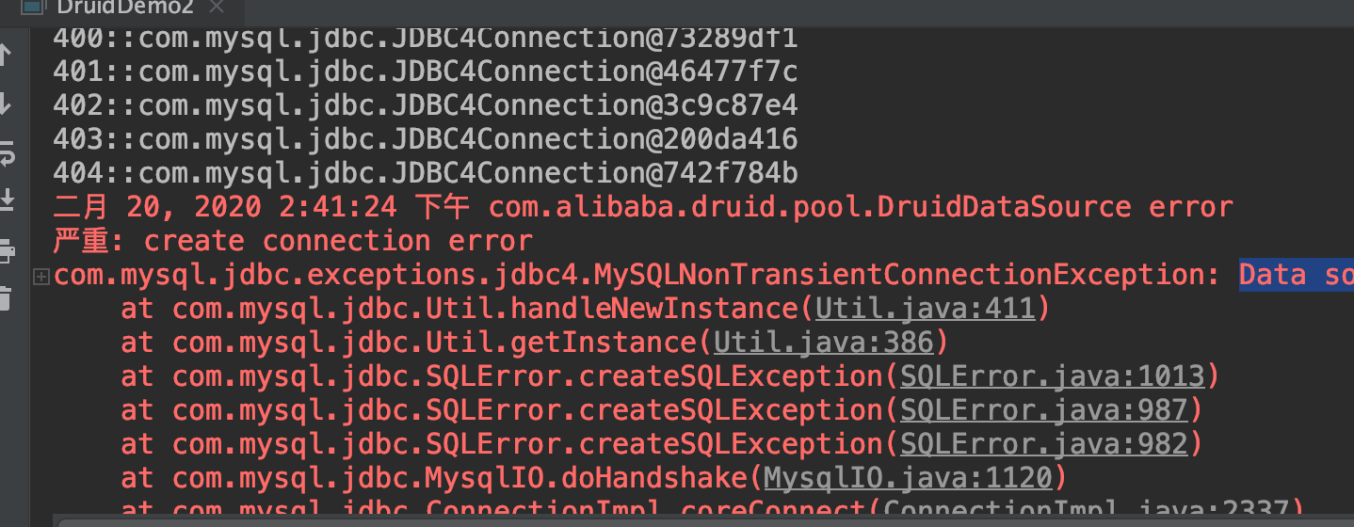
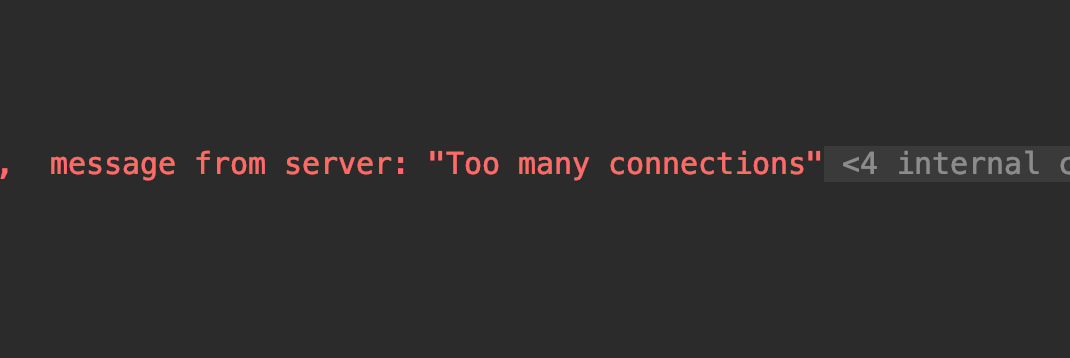
测试DB数据:
新建DruidDemo3.class 因为数据较多,所以使用addBatch() 将sql命令添加到命令列表中,然后使用executeBatch()把这一批命令提交给数据库执行。
这个是三千万的代码,100万将signleNum改为33吧,或去掉外层循环。
package druid;import utils.JDBCUtils;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.SQLException;public class DruidDemo3 { public static void main(String[] args) throws SQLException { Connection conn = null; PreparedStatement pstmt = null; long begin = System.currentTimeMillis(); try { conn = JDBCUtils.getConnection(); String sql = "insert into t_user values(?,?,?)"; pstmt = conn.prepareStatement(sql); conn.setAutoCommit(false); int signleNum = 100000; for (int j = 1; j<=300; j++) { for (int i = 1; i <= signleNum; i++) { int idNum = i+(j-1)*signleNum; pstmt.setInt(1, idNum); pstmt.setString(2, "hello"); pstmt.setString(3, "world"); pstmt.addBatch(); } pstmt.executeBatch(); pstmt.clearBatch(); conn.commit(); System.out.println(j+"个"+signleNum); } }catch (SQLException e){ e.printStackTrace(); }finally { JDBCUtils.close(pstmt,conn); } long end = System.currentTimeMillis(); System.out.println(end- begin); }}
100w数据结果:由于查询错了字段,结果都一样,后来发现错误。
3千万数据过程:
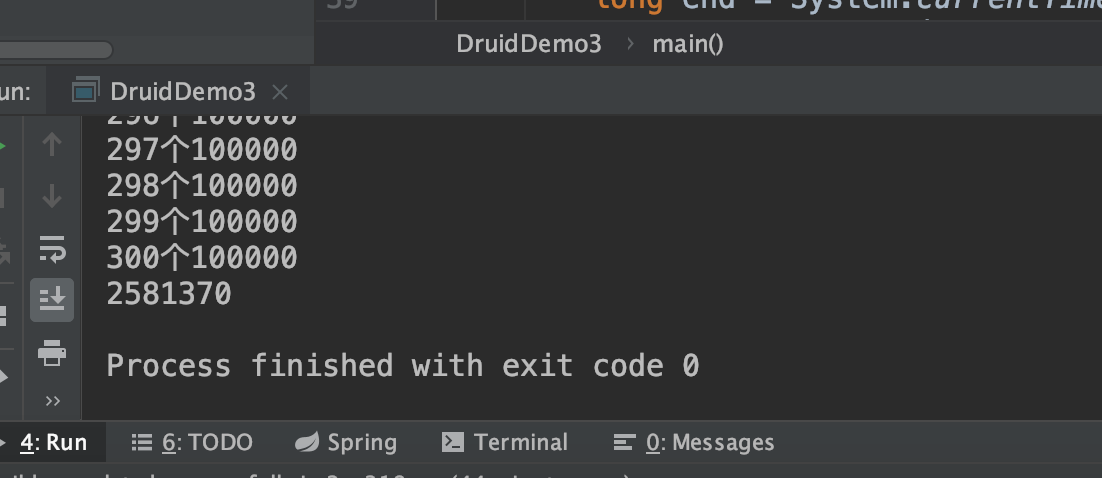
2581379豪秒即43min。插入了了三千万数据。两亿的数据就不跑了。。
修改靠后的数据:
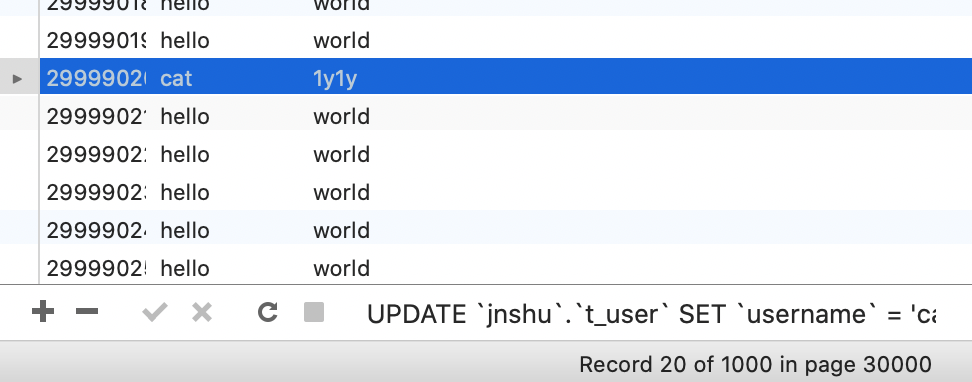
执行查询:
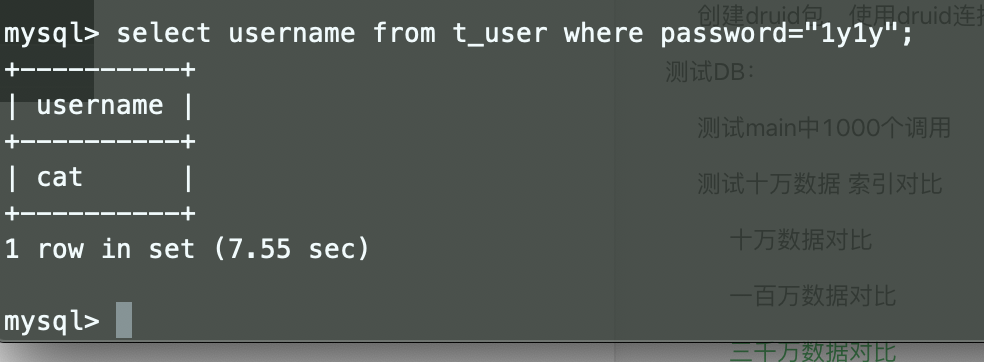
添加索引:
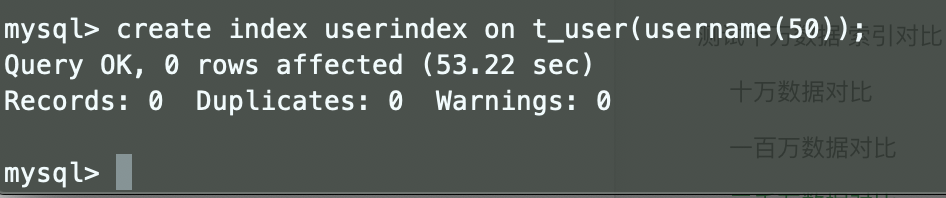
继续查询:
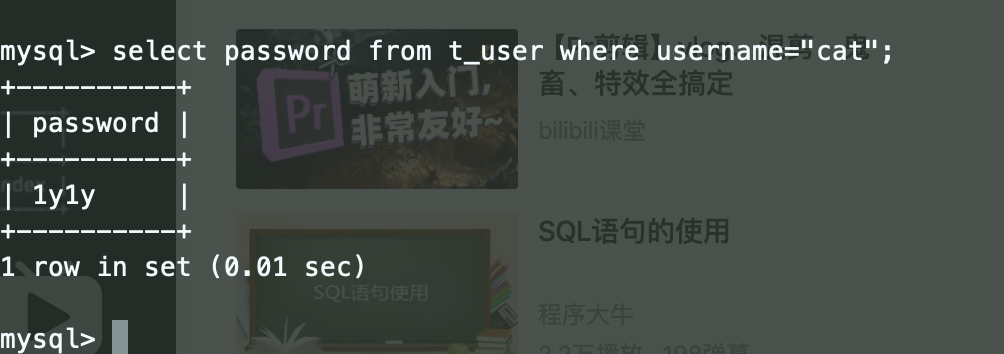
明天计划的事情:
* 写总结
遇到的问题:
* 创建索引查询错了字段,查询3000w数据发现结果还是一样,突然才发现索引的字段应该在where子句那个位置。
收获:
写日报时发现,生成三千万数据时,把之前代码又套了个循环。并内层循环提供了一个变量用于修改, 但是外层循环写死了300。但这样,生成100w数据时还是得该,因为100不是三的倍数。。要养成良好的赋值变量习惯。。。




评论