发表于: 2019-12-31 22:34:01
1 1215
归根结底,是对注入的机制了解不深入.
今天做了什么:
改一些与原型图上不同的细节.
看看缓存设计
I/O
收获:
缓存设计:
缓存粒度控制
缓存粒度问题是一个容易被忽视的问题,如果使用不当,可能会造成很多无用空间的浪费,网络带宽的浪费,代码通用性较差等情况,需要综合数据通用性、空间占用比、代码维护性三点进行取舍。
缓存比较常用的选型,缓存层选用Redis,存储层选用MySQL。
假如我现在需要对视频的信息做一个缓存,也就是需要对select * from video where id=?的每个id在redis里做一份缓存,这样cache层就可以帮助我抗住很多的访问量(注:这里不讨论一致性和架构等等问题,只讨论缓存的粒度问题)。
我们假设视频表有100个属性(这个真有,有些人可能难以想象),那么问题来了,需要缓存什么维度呢,也
就是有两种选择吧:
catch(id)=select * from video where id=#id
catch(id)=select importantColumn1, importantColumn2 .. importantColumnN from video where id=#id 12
其实这个问题就是缓存粒度问题,我们在缓存设计应该佮预估和考虑呢?下面我们将从通用性、空间、代码维护三个角度进行说明。
全部数据和部分数据比较

如果单从通用性上看、全部数据是最优秀的,但是有个问题就是是否有必要缓存全部数据,任 务以后会有这样的需求,但是从经验上看除了非常重要的信息,哪些不重要的字段基本不会再绣球里出现,也就是说着中通用性,通常都是想象出来的。太多人觉得通用性是最重要的。vid拿一些基本信息,回想专辑明星,于是加了全局的,通用性很重要,但是要想清楚。通用性
空间占用:很显然,缓存全部数据,会占用大量的内存,有人会说,不就费一点内存吗,能有多少钱?而且已经有人习惯了把缓存当做下水道来使用,什么都框框的往里面放,但是我这里要说内存并不是免费的,可以说是很珍贵的资源。instagram21->4G的例子就说明了这个道理,好的程序员可以帮助公司节约大量的资源。
代码维护:代码维护性,全部数据的优势更加明显,而部分数据一旦要加新字段就会修改代码,而且还需要对原来的数据进行刷新。
总结:缓存粒度问题是一个容易被忽视的问题,如果使用不当,可能会造成很多无用空间的浪费,可能会造成网络带宽的浪费,可能会造成代码通用性较差等情况,必须学会综合数据通用性、空间占用比、代码维护性 三点评估取舍因素权衡使用。
缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层。
通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。造成缓存穿透的基本原因有两个。第一,自身业务代码或者数据出现问题,第二,一些恶意攻击、爬虫等造成大量空命中。下面我们来看一下如何解决缓存穿透问题。
1.缓存空对象:如图下所示,当第2步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。
缓存空对象会有两个问题:第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
2.布隆过滤器拦截
如下图所示,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。例如:一个推荐系统有4亿个用户id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度保护了存储层。
缓存空对象和布隆过滤器方案对比

热点key重建优化
开发人员使用“缓存+过期时间”的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是有两个问题如果同时出现,可能就会对应用造成致命的危害:
当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
要解决这个问题也不是很复杂,但是不能为了解决这个问题给系统带来更多的麻烦,所以需要制定如下目标:
减少重建缓存的次数
数据尽可能一致
较少的潜在危险
①互斥锁:此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,整个过程如图所示。
②永远不过期
永远不过期”包含两层意思: 从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。 从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
从实战看,此方法有效杜绝了热点key产生的问题,但唯一不足的就是重构缓存期间,会出现数据不一致的情况,这取决于应用方是否容忍这种不一致。
两种热点key的解决方法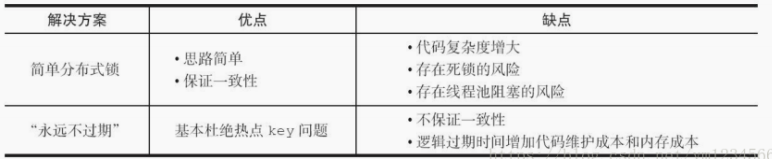
明天的计划:
demo.然后继续看基础和面试题.




评论