今天完成的事情:整理深度思考的内容
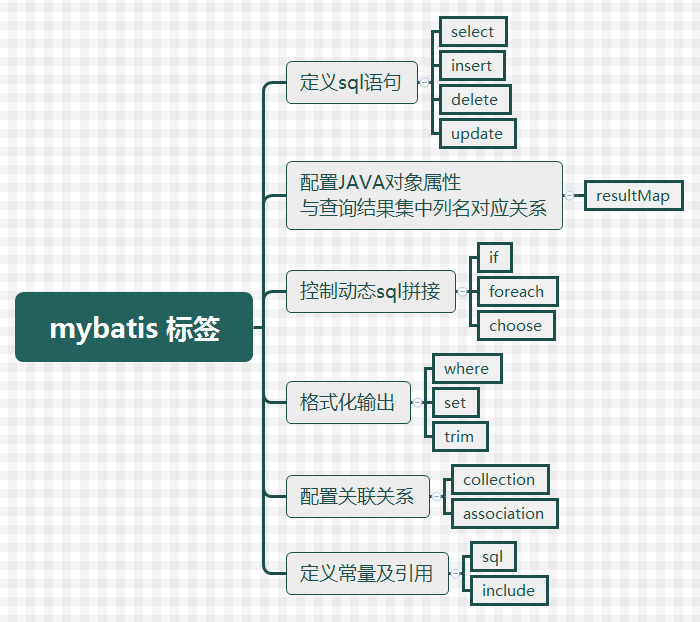
1.Mybatis有哪些常用标签?怎么使用标签来完成动态查询?
if标签一般用于非空验证,若xx为空,if标签里的代码,将不会执行,反之,则会执行。
choose(when,otherwise)标签相当于switch(case,default) ,若xx为空,when标签里的代码,将不会执行,默认执行otherwise标签里面的代码。
where标签代替了sql中where关键字,where标签可以自动去除是“AND”或“OR”开头的sql中的“AND”或“OR”关键字。
set标签代替了sql中set关键字,set标签可以自动去除sql中的多余的“,”
foreach标签可迭代任何对象(如列表、集合等)和任何的字典或者数组对象传递给foreach作为集合参数,当使用可迭代对象或者数组时,index是当前迭代的次数,item的值是本次迭代获取的元素。当使用字典(或者Map.Entry对象的集合)时,index是键,item是值。collection标签可以填('list','array','map')。
foreach元素的属性主要有 item,index,collection,open,separator,close。
item表示集合中每一个元素进行迭代时的别名;
index指 定一个名字,用于表示在迭代过程中,每次迭代到的位置;
open表示该语句以什么开始,
separator表示在每次进行迭代之间以什么符号作为分隔符;
close表示以什么结束。
2.什么叫反射?反射的坏处是什么?有哪些反射的应用场景?
反射:在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制
坏处:
反射包括了一些动态类型,所以JVM无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被 执行的代码或对性能要求很高的程序中使用反射。
使用反射技术要求程序必须在一个没有安全限制的环境中运行。
由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用--代码有功能上的错误,降低可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
应用场景
①我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;
②Spring框架也用到很多反射机制,最经典的就是xml的配置模式。
Spring 通过 XML 配置模式装载 Bean 的过程:
1) 将程序内所有 XML 或 Properties 配置文件加载入内存中;
2)Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息;
3)使用反射机制,根据这个字符串获得某个类的Class实例;
4)动态配置实例的属性。
3.什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
SVN是subversion的缩写,是一个开放源代码的版本控制系统,通过采用分支管理系统的高效管理,简而言之就是用于多个人共同开发同一个项目,实现共享资源,实现最终集中式的管理。
最核心的区别Git是分布式的,而Svn不是分布的。能理解这点,上手会很容易,声明一点Git并不是目前唯一的分布式版本控制系统,还有比如Mercurial等,所以说它们差不许多。话说回来Git跟Svn一样有自己的集中式版本库和Server端,但Git更倾向于分布式开发,因为每一个开发人员的电脑上都有一个Local Repository,所以即使没有网络也一样可以Commit,查看历史版本记录,创建项 目分支等操作,等网络再次连接上Push到Server端
4.什么是AOP,适用于哪些场景,AOP的实现方案有哪些?
面向切面编程,通过预编译方式和运行期间动态代理实现程序功能的统一维护的一种技术。AOP是OOP的延续,是软件开发中的一个热点,也是Spring框架中的一个重要内容,是函数式编程的一种衍生范型。利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
具体功能如下:
Authentication 权限
Lazy loading 延时加载
Debugging 调试
logging, tracing, profiling and monitoring 记录跟踪 优化 校准
Performance optimization性能优化
Persistence 持久化
Synchronization 同步
5.Map,List,Array,Set之间的关系是什么,分别适用于哪些场景,集合大家族还有哪些常见的类?
最基础的是Array,所有的集合都是通过Array实现的。在代码中进行随机访问和存储,Array的效率是最高的,但是Array是固定的,不能动态改变,且一个Array只能存放同一种数据类型。针对以上缺点,就出现了集合List(ArrayList(主要的实现类)、LinkedList(对于频繁的插入,删除操作)、Vector(古老的实现类,线程安全的),Set(HashSet(主要实现类)、LinkedHashSet、TreeSet),Map(HashMap、LinkedHashMap、TreeMap、Hashtable(子类:Properties))。List代表有序,重复的集合Set代表无序,不可重复的集合,,Map代表具有映射关系的集合。
适用场景
a.如果你经常会使用索引来对容器中的元素进行访问,那么 List 是你的正确的选择。 如果你已经知道索引了的话,那么 List 的实现类比如 ArrayList 可以提供更快速的访问,如果经常添加删除元素的,那么肯定要选择LinkedList。
b.如果你想容器中的元素能够按照它们插入的次序进行有序存储,那么还是 List,因为 List 是一个有序容器,它按照插入顺序进行存储。
c.如果你想保证插入元素的唯一性,也就是你不想有重复值的出现,那么可以选择一个 Set 的实现类,比如 HashSet、LinkedHashSet 或者 TreeSet。 所有Set的实现类都遵循了统一约束比如唯一性,而且还提供了额外的特性比如 TreeSet 还是一个 SortedSet,所有存储于 TreeSet 中的元素可以使用 Java 里的 Comparator 或者 Comparable 进行排序。LinkedHashSet 也按照元素的插入顺序对它们进行存储。
d.如果你以键和值的形式进行数据存储那么 Map 是你正确的选择。你可以根据你的后续需要从 Hashtable、HashMap、TreeMap 中进行选择。
6.Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
IOC的配置形式:基于XML文件,基于Annonation 。
传统的Spring做法是使用.xml文件来对bean进行注入或者是配置aop、事物,这么做有两个缺点:
1、如果所有的内容都配置在.xml文件中,那么.xml文件将会十分庞大;如果按需求分开.xml文件,那么.xml文件又会非常多。总之这将导致配置文件的可读性与可维护性变得很低。
2、在开发中在.java文件和.xml文件之间不断切换,是一件麻烦的事,同时这种思维上的不连贯也会降低开发的效率。
为了解决这两个问题,Spring引入了注解,通过"@XXX"的方式,让注解与Java Bean紧密结合,既大大减少了配置文件的体积,又增加了Java Bean的可读性与内聚性。
7..JDBCTemplate和JDBC
什么是JDBC?
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
什么是JDBCTemplate?
JDBCTemplate 多的这个template,中文意思为模板,是Spring框架为我们提供的.所以JDBCTemplate就是Spring对JDBC的封装,通俗点说就是Spring对jdbc的封装的模板
JdbcTemplate对JDBC的差别在哪?
jdbc需要每次进行数据库连接, 然后处理SQL语句,传值,关闭数据库.甚至有时还可能会出现数据库忘记关闭导致连接被占用.在以后的工作中,客户的需求肯定不是一成不变的,这就导致经常会改动数据库内容.通过JDBCtemplate我们只需更改需要更改的那一部分内容就可以了,不需要进行全局修改.Spring将替我们完成所有的JDBC底层细节处理工作.
8.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
SpringIOC是Spring框架的一个核心概念。
java程序中的类互相依赖,大量耦合。而SpringIOC(Inversion of Control)就是去创建管理这些依赖,从而尽可能的降低耦合,这些被它创建管理的类被称为bean。它是一个思想,从字面上看它是控制反转,但是直接说反转可能难以理解,我们可以从另一个角度去理解它,比如先理解正再理解反会更容易一些。什么是正,我们平常去new对象就是正面使用,我们使用Spring依赖注入(DI)去获取对象也是正面使用,new的时候是自己去创建依赖然后使用,但是这样我们的代码内部就有了它的实例,这就有了耦合。而spring容器是读取了配置元数据之后,通过java反射创建类并注入其依赖类。
为什么不使用new来创建实例?(参见演示)
1.增加耦合,会访问到内部属性
2.更新的地方比较多,难于维护
9.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
1、简单、规范性:如果一个项目比较庞大,那么就需要一个工程师来定义一些主要的接口,这些接口不仅告诉开发人员你需要实现那些业务,而且也将命名规范限制住了(防止一些开发人员随便命名导致别的程序员无法看明白)。
2、维护、拓展性:如果以后你想修改这个类甚至完全删除了,放弃这个类,但是其他地方引用了这个类name这样修改起来会非常麻烦,如果一开始就定义了一个接口,把主要的功能放在接口里面 你只需要用这个类去实现其他类就好了,以后需要换的只不过是其他引用类,这样就达到了维护和拓展的方便性。
3、安全、严密性:接口是实现软件松耦合的重要手段,它描叙了系统对外的所有服务,而不涉及任何具体的实现细节。这样就比较安全、严密一些(一般软件服务商考虑的比较多)。
10.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
一个用java搭建的Web服务器,在执行数据库查询的时候发现目标数据库有异常,然后抛Exception了。然后你觉得是应该把Exception抓住并分析处理还是让程序直接终止掉呢?直接终止的处理方法对于一个需要持续运行的Web服务器来说是无法接受的。而且在很多地方Exception可以用来传递消息,并不是错误让自己解决了就行了的,需要让外界知道并把处理权交给外界的调用者。
1)以业务逻辑功能为单位,在最上层加Try-Catch机制。为什么要这样做呢?这主要是增加程序的健壮性,防止因抛出异常过多,导致程序崩溃。
2)底层代码,在可能出错的地方加Try-Catch机制,用Catch侦测具体的异常,然后就具体的异常,采取相应的解决方案。
3)底层代码,在需异常追踪时加Try-Catch机制,在Catch块中抛出自定义异常,调试时可迅速定位到错误代码段。
11.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
Log最常用的级别就是DEBUG,INFO,WARN,ERROR
每一条log中都要将时间、类名及函数名,可以的话将行号也打印出来
12.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
在程序开发中,为了找到程序的bug,通常采用的一种调试手段,一步一步跟踪程序执行的流程,根据变量的值,找到错误的原因。很多的开发工具都支持单步调试。
13.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
远程调试:服务端程序运行在一台远程服务器上,我们可以在本地服务端的代码(前提是本地的代码必须和远程服务器运行的代码一致)中设置断点,每当有请求到远程服务器时时能够在本地知道远程服务端的此时的内部状态。
14.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
1.什么是贫血模型?
贫血模型是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务逻辑层。
2.什么是充血模型?
充血模型将大多数业务逻辑和持久化放在领域对象中,业务逻辑只是完成对业务逻辑的封装、事务和权限等的处理。比较符合面向对象。
3.为什么我们会强制要求使用贫血模型?
系统的层次结构清楚,各层之间单向依赖。
耦合度低,方便后期的更新与维护。
设计简单,底层模型稳定。
15.为什么不可以用Select * from table?
select * from table 的缺点
1、mysql拿到一条命令,会去解析命令、优化查询,然后去存储引擎执行查找.SELECT * 语句取出表中的所有字段,会解析更多的 对象,字段,权限,属性相关,不论该字段的数据对调用的应用程序是否有用,这会对服务器资源造成浪费,导致优化和效率问题,对服务器的性能产生一定的影响。
2、如果表的结构在以后发生了改变,那么SELECT * 语句可能会取到不正确的数据甚至是出错。
3、执行SELECT * 语句时,select * 语句要对表中所有列进行权限检查,这部分也是开销
4、使用SELECT * 语句将不会使用到覆盖索引,不利于查询的性能优化.(索引覆盖:索引覆盖是一种速度极快,效率极高,业界推荐的一种查询方式.就是select的数据列只用从索引中就能够获得,不必从数据表中读取,也就是查询列要被所使用的索引覆盖)
5、在文档角度来看,SELECT * 语句没有说明将要取出哪些字段进行操作,不具备针对性,不推荐。
6、用 select * 语句插入一个表,以后表结构修改了,如增加或删除了一列,对代码影响很大,如果只是恰好只获取自己需要的那几列,表结构的修改对你的代码影响就会比较小,便于后期项目维护。
16.clean,install,package,deploy分别代表什么含义?
clean: 清除target目录;
install: 将工程打包到本地仓库,这时本地项目可以依赖,别人是依赖不了的;
package:将项目中的各种文件,比如源代码、编译生成的字节码、配置文件、文档,按照规范的格式生成归档,最常见的当然就是JAR包和WAR包;
deploy: 将打包的jar文件上传到私服(如果有私服),此时连接私服的人才可以下载依赖。
17.怎么样能让Maven跳过JUnit?
当 Surefire 插件到达 test 目标的时候,如果 maven.test.skip 设置为 true ,它就会跳过单元测试。 另一种配置 Maven 跳过单元测试的方法是给你项目的 pom.xml 添加这个配置。 你需要为你的 build 添加 plugin 元素。
<project>
[...]
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
[...]
</project>
18.为什么要用Log4j来替代System.out.println?
System.out.println在开发中可以使用,部署项目后用日志文件。最好不要用System.out.println。
19.为什么DB的设计中要使用Long来替换掉Date类型?
1.有利于计算时间差
2.方便java与数据库之间的传输
20.自增ID有什么坏处?什么样的场景下不使用自增ID?
自增ID有什么坏处?
不存在连续性,也就是说若表中存有3行数据,ID字段为1,2,3 那么当删除字段2时就变为1,3,不具有连续性
合并表会出现ID重复的情况,上面说个使用自增ID能够在单个表中保证ID字段唯一,但两个表何为1个表,时不具有这种性质的。
什么场景下不使用自增ID?
正是因为自增ID的缺点也就是无法在多个表中,或者多个数据库中保持ID主键唯一不重复,所以若是使用分布式数据库以及数据合并的情况下时不能使用自增ID的。
若是能够有其他的字段能作为主键保证唯一性,无需使用自增ID
21.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
22.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
因此,应该只为那些最经常出现在查询条件或排序条件中的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。在对该列进行增或改时,首先会检查是否重复,在执行增改操作,否则报出duplica错误,拒绝操作。
23.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
对一个字段做唯一索引之后,在执行sql语句时,会自动在后台根据索引查询是否有重复的值,不需要手动判断qq号是否存在。
24.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
CreateAt在创建时赋值,UpdateAt在修改时赋值。
25.修真类型应该是直接存储Varchar,还是应该存储int?
都可以。
26.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
根据需求与实际情况来考虑,不能千篇一律。 比如:用户名,谁的名字会有255/3=85个字符?所以也没必要那么长,但又不能定义成CHAR(),所以给个够用的长度varchar(20)或更少varchar(10)即可,考虑少数民族可以长点。 varchar的长度,最好是在够用(需要适当预测未来需求)且方便管理的前提下尽可能短。
27.怎么进行分页数据的查询,如何判断是否有下一页?
没学呢
28.maven是什么,和Ant有什么区别?
Maven是专门用于构建和管理Java相关项目的工具
Maven 和 Ant 针对构建问题的两个不同方面。Ant 为 Java 技术开发项目提供跨平台构建任务。Maven 本身描述项目的高级方面,它从 Ant 借用了绝大多数构建任务。
后天计划的事情:提交任务1,开始任务2。
遇到的问题:无
收获:
1.深度思考的内容
2.Git删除本地仓库
删除仓库,就是需要删除仓库文件夹下隐藏的 .git 文件夹!!!
进入项目所在目录,打开git bash,开始删除本地仓库:
显示所有本地分支(初始化时只有一个master分支)
$ git branch
初始化本地版本库(重新初始化一次,可以忽略)
$ git init
找到目录下隐藏的 .git
$ ls -a
删除 .git
$ rm -rf .git
可以看到master分支已经删除
3. 上传项目到git,具体参考如下
https://jingyan.baidu.com/article/636f38bb9747d1d6b84610f3.html





评论