发表于: 2019-12-25 21:00:59
1 1115
一、今天完成的事
调了一整天的性能
1.优化sql
创建索引
在查询videoList的表的时候会用到video、video_collection、video_like、teacher、teacher_video五个表,所以在需要的地方添加索引查看是否能够减少查询时间
未加索引前
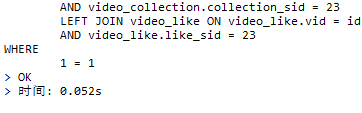
加了索引后
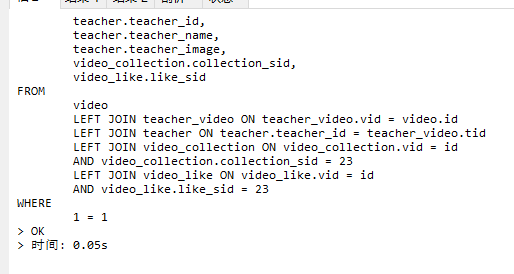
影响不是特别大,
2.修改表引擎
mysql5.1以上默认使用innodb引擎,修改为myisam引擎,因为myisam更适合需要平凡查询的表
innodb引擎查询结果
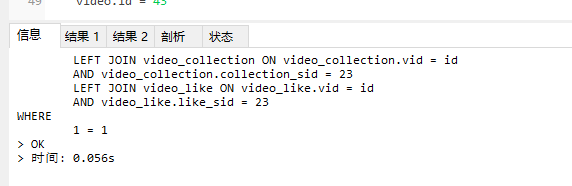
myisam引擎查询结果
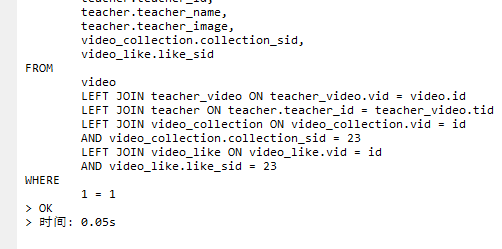
因为数据量比较小,所以大概都优化了一点点,对我们的项目来说影响都不是很大
主要还是sql 的原因,因为这里使用了大量的leftjoin关键字,而又不得不使用,leftjoin是非常占用时间的。
3.修改缓存策略
单个线程的查询时间是正常的
如果使用缓存大概就是40ms左右
如果缓存失效第一次请求大概在70ms左右
修改缓存策略,改springboot方式为手动写redis缓存也没有提升
4.问题所在
调试中发现问题的所在,因为使用了zuul进行转发,可能zuul有限制,如果不使用zuul直接访问端口,测得结果如下

如果使用zuul转发之后测试结果如下
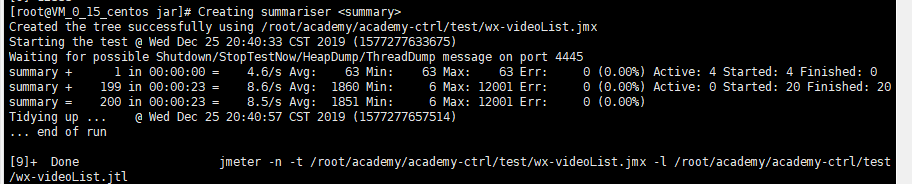
二、遇到的问题
三、收获
myisam和innodb的区别
MyISAM:
myisam只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。也可以通过lock table命令来锁表,这样操作主要是可以模仿事务,但是消耗非常大,一般只在实验演示中使用。
InnoDB :
Innodb支持事务和行级锁,是innodb的最大特色。
事务的ACID属性:atomicity,consistent,isolation,durable。
并发事务带来的几个问题:更新丢失,脏读,不可重复读,幻读。
事务隔离级别:未提交读(Read uncommitted),已提交读(Read committed),可重复读(Repeatable read),可序列化(Serializable)
聚簇索引和非聚簇索引
聚簇索引主要应用于Innodb非聚簇索引主要应用于Myisam
表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。
非聚集索引。表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
如何选择引擎
MyISAM
不需要事务支持(不支持)
并发相对较低(锁定机制问题)
数据修改相对较少(阻塞问题),以读为主
数据一致性要求不是非常高
尽量索引(缓存机制)
调整读写优先级,根据实际需求确保重要操作更优先
启用延迟插入改善大批量写入性能
尽量顺序操作让insert数据都写入到尾部,减少阻塞
分解大的操作,降低单个操作的阻塞时间
降低并发数,某些高并发场景通过应用来进行排队机制
对于相对静态的数据,充分利用Query Cache可以极大的提高访问效率
MyISAM的Count只有在全表扫描的时候特别高效,带有其他条件的count都需要进行实际的数据访问
InnoDB
需要事务支持(具有较好的事务特性)
行级锁定对高并发有很好的适应能力,但需要确保查询是通过索引完成
数据更新较为频繁的场景
数据一致性要求较高
硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,尽可能减少磁盘 IO
主键尽可能小,避免给Secondary index带来过大的空间负担
避免全表扫描,因为会使用表锁
尽可能缓存所有的索引和数据,提高响应速度
在大批量小插入的时候,尽量自己控制事务而不要使用autocommit自动提交
合理设置innodb_flush_log_at_trx_commit参数值,不要过度追求安全性
避免主键更新,因为这会带来大量的数据移动
四、明天的计划
先把zuul的问题解决了,再做其他的压测




评论