发表于: 2019-12-20 22:12:05
1 1149
今天做了什么:
微信文章前台修改了一些细节
文章列表显示点赞和收藏状态,看上去简单其实实现起来还挺麻烦的
方案是sql查询文章时外左连接article_like和article_collection表:
select article.* , article_like.sid , article_collection.sid from article
left join article_like on article_like.aid=article.id and article_like.sid=(select id from student where openId=#{openId})
left join article_collection on article_collection.aid=article.id and article_collection.sid=(select id from student where openId=#{openId})
收获:
面试时发现集合框架和线程方面挺薄弱的,针对性补充一下:
Java集合类由两个类派生:Collection和Map,它们是Java集合框架的根接口.
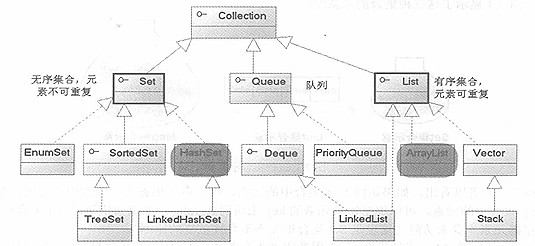
- List和Set继承自Collection接口,Map是独立接口
- List:可重复,有序
- Set:不允许重复(用对象的equals()方法来区分元素是否重复)。
- Map是键值对映射容器,key不重复,value可重复.
List:
- ArrayList 和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢.
- Vector中的方法由于添加了synchronized修饰,底层数据结构是数组,线程安全,效率低,已经是Java中的遗留容器。
- LinkedList使用双向链表实现存储.( 将内存中零散的内存单元通过附加的引用关联起来,形成一个可以按序号索引的线性结构,这种链式存储方式与数组的连续存储方式相比,内存的利用率更高)索引慢插入块.
Set:
- TreeSet主要功能用于排序.底层数据结构是红黑树
- LinkedHashSet主要功能用于保证FIFO即有序的集合.底层数据结构是链表和哈希表
- HashSet只是通用的存储数据的集合.底层数据结构是哈希表
- 三者都实现Set interface,都不包含重复元素
- 都不是线程安全.(若要使用线程安全用Collections.synchronizedSet()方法)
- 从性能上:HashSet插入最快,LinkedHashSet其次,TreeSet最慢,因为内部实现排序
- 从排序上:HashSet不保证有序,LinkedHashSet保证FIFO即按插入顺序排序,TreeSet内部实现排序,也可以自定义排序规则
- 从null上:HashSet和LinkedHasSet允许null,TreeSet插入null会报NullPointerException
- 自然排序:要比较的类实现Comparable接口,重写CompareTo方法
- 比较器排序:创建一个比较器类,继承Comparator接口,重写Compare方法,构造方法中注入比较器:TreeSet(Comparator<? superE> comparator)
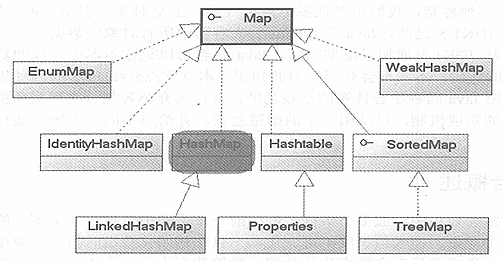
Map:
- HashMap:线程不安全,效率较高,允许null值.(如果对同步性或与遗留代码的兼容性没有任何要求,建议使用HashMap)
- TreeMap:有序.另外两者无序
- HashTable:同步,线程安全(所有public方法声明中都有synchronized关键字) 不允许null值
Collections工具类的sort方法有两种重载的形式,第一种要求传入的待排序容器中存放的对象比较实现Comparable接口;第二种不强制性的要求容器中的元素必须可比较,但是要求传入第二个参数,参数是Comparator接口的子类型(需要重写compare方法实现元素的比较),相当于一个临时定义的排序规则,其实就是通过接口注入比较元素大小的算法,也是对回调模式的应用(Java中对函数式编程的支持)
线程
- 1.核心线程数corePoolSize:一直存活;当线程数小于核心线程数,创建新线程
- 2.阻塞队列queueCapacity:当核心线程数达到最大,新任务将放入任务队列
- 3.最大线程数maxPoolSize:当任务队列已满,创建新线程,直至达到最大线程数
- 4.线程空闲时间keepAliveTime:空闲时间达到一定值时线程退出,若允许核心线程超时,核心线程也会退出
- 5.允许核心线程超时allowCoreThreadTimeout
- 6.任务拒绝处理器rejectedExecutionHandler
关闭线程的方法:
- 1.stop().不推荐
- 2.通过volatile类型的boolean变量来控制循环
- 3.interrrupt()方法
总结:一个保持锁,一个放弃锁.
问题:
1.使用缓存时如何保持缓存数据与数据库同步?
明天计划:
联调后台管理部分.




评论