今天完成的事情:
今天把任务一些细节解决了, 感谢师兄帮忙
本以为引用类型与基本类型的区别很简单,深入了解后发现,确实有内涵。
引用类型与基本类型的区别
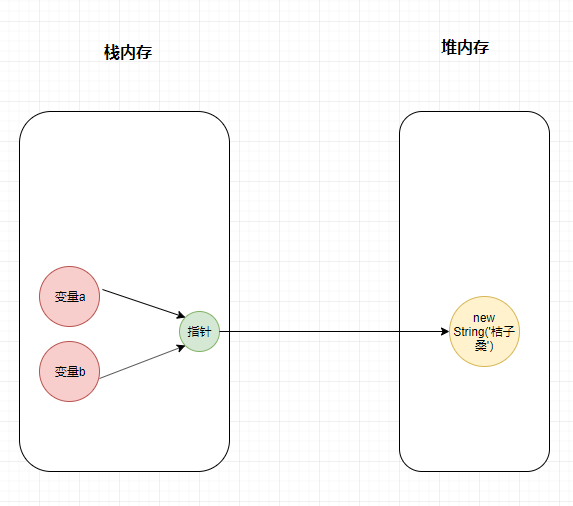
引用类型是存放在堆内存中的对象,变量是保存的在栈内存中的一个指针(保存的是堆内存中的引用地址),这个指针指向堆内存。
引用类型数据在栈内存中保存的实际上是对象在堆内存中的引用地址。通过这个引用地址可以快速查找到保存中堆内存中的对象
栈内存主要用于存储各种基本类型的变量,包括Boolean、Number、String、Undefined、Null,**以及对象变量的指针,这时候栈内存给人的感觉就像一个线性排列的空间,每个小单元大小基本相等。而堆内存主要负责像对象Object这种变量类型的存储,在JS中除了基本数据类型以外的都是对象,数据是对象,函数是对象,正则表达式是对象,
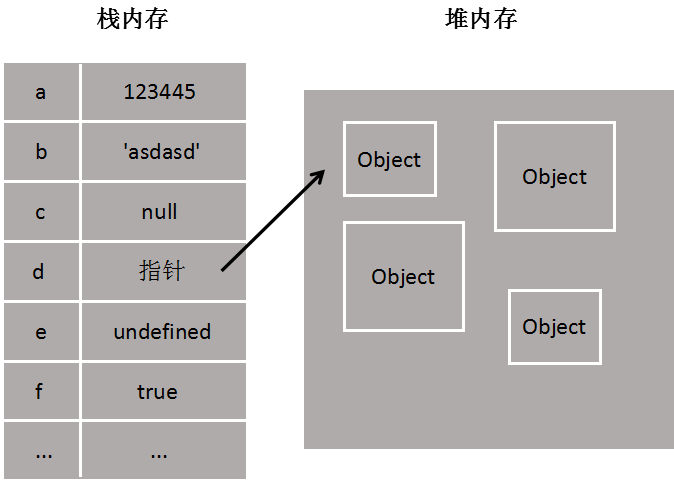
栈内存中的变量一般都是已知大小或者有范围上限的,算作一种简单存储。
而堆内存主要负责像对象Object这种变量类型的存储,堆内存存储的对象类型数据对于大小这方面,一般都是未知的,(所以这大概也是为什么null作为一个object类型的变量却存储在栈内存中的原因)。
————————————————————————————————————
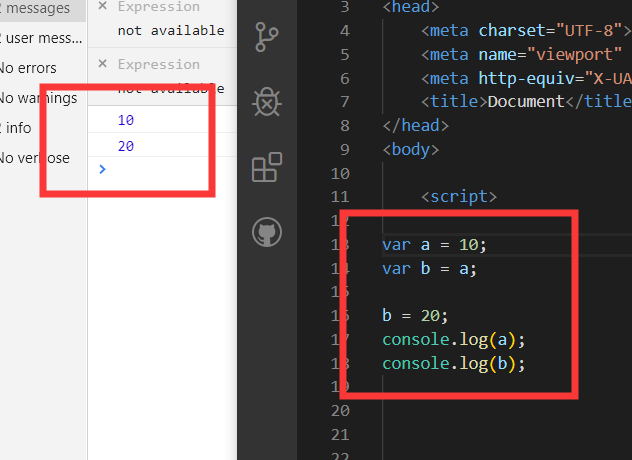
栈内存
初始栈内存只有a,栈内存添加b,b复制a。此时b是10,栈内存b保存了另一个值,但是并不影响a的值。
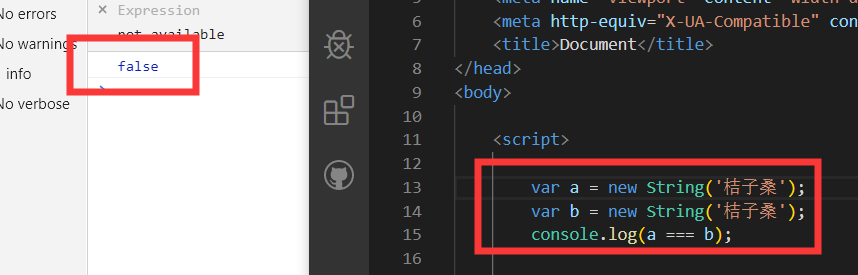
new关键字生成的对象都是存在于堆内存中的
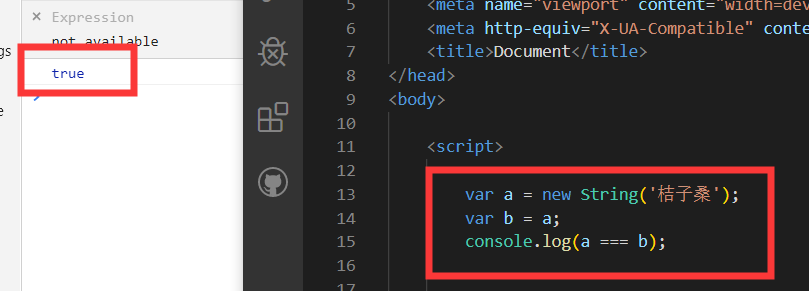
var a = new String('桔子桑');变量 a 存在于栈内存中,他的值是一个指针,这个指针指向堆内存中的一个对象!
普通变量的值类型是基本数据类型,指向栈内存中的一块地址;
引用类型变量的值是指针,指向堆内存中的一块地址。
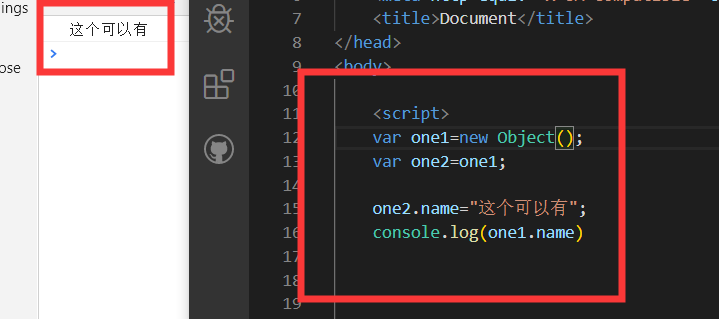
one1在栈内存中,值指向堆内存,one2等于one1,它们的指针指向一个堆内存对象,所以one1也可以访问one2
下面这个例子,a在栈内存,b等于a,b复制了一份a的数组,在同一个栈内,所以修改b,a也会根据地址回到a堆中修改
c直接在栈中修改,不能指向a堆内存中。
var a = [1,2,3,4,5];
var b = a;//传址 ,对象中传给变量的数据是引用类型的,会存储在堆中;
var c = a[0];//传值,把对象中的属性/数组中的数组项赋值给变量,这时变量C是基本数据类型,存储在栈内存中;改变栈中的数据不会影响堆中的数据
alert(b);//1,2,3,4,5
alert(c);//1
//改变数值
b[4] = 6;
c = 7;
alert(a[4]);//6
alert(a[0]);//1
————————————————————————
1、声明变量时内存分配不同
*原始类型:在栈中,因为占据空间是固定的,可以将他们存在较小的内存中-栈中,这样便于迅速查询变量的值
*引用类型:存在堆中,栈中存储的变量,只是用来查找堆中的引用地址。
这是因为:引用值的大小会改变,所以不能把它放在栈中,否则会降低变量查寻的速度。相反,放在变量的栈空间中的值是该对象存储在堆中的地址。地址的大小是固定的,所以把它存储在栈中对变量性能无任何负面影响
2、不同的内存分配带来不同的访问机制
在JS中是不允许直接访问保存在堆内存中的对象的,所以在访问一个对象时,首先得到的是这个对象在堆内存中的地址,然后再按照这个地址去获得这个对象中的值,这就是传说中的按引用访问。
而原始类型的值则是可以直接访问到的。
3、复制变量时的不同
1)原始值:在将一个保存着原始值的变量复制给另一个变量时,会将原始值的副本赋值给新变量,此后这两个变量是完全独立的,他们只是拥有相同的value而已。
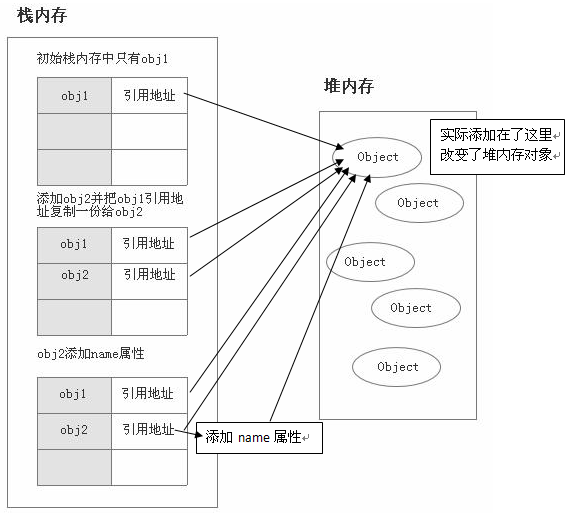
2)引用值:在将一个保存着对象内存地址的变量复制给另一个变量时,会把这个内存地址赋值给新变量,
也就是说这两个变量都指向了堆内存中的同一个对象,他们中任何一个作出的改变都会反映在另一个身上。
(这里要理解的一点就是,复制对象时并不会在堆内存中新生成一个一模一样的对象,只是多了一个保存指向这个对象指针的变量罢了)。多了一个指针
4、参数传递的不同(把实参复制给形参的过程)
原始值:只是把变量里的值传递给参数,之后参数和这个变量互不影响。
引用值:对象变量它里面的值是这个对象在堆内存中的内存地址,这一点要时刻铭记在心!
因此它传递的值也就是这个内存地址,这也就是为什么函数内部对这个参数的修改会体现在外部的原因了,因为它们都指向同一个对象。
————————————————————————————————————
JS中执行环境与作用域的关系
window 是最大最外围的执行环境,每个函数都有自己的执行环境。JS代码是从上到下执行的
全局执行环境是最外围的一个执行环境,在Web浏览器中,全局执行环境被认为是window对象, 因此所有全局变量和函数都是作为window对象的属性和方法来创建的。 某个执行环境中的所有代码执行完毕后,该环境就会被销毁,保存在其中的所有变量和函数定义也随之销毁。
变量对象
如果所在环境是函数,那么就会把这个函数的活动对象作为变量对象(在函数中,变量对象==活动对象)。 一般而言,函数执行过程,可以分成两步:1.进入执行环境;2.执行代码。
环境栈的定义
当执行流进入一个函数时,函数的环境就会被推入一个环境栈中。执行之后,再从环境栈中弹出。
作用链的定义
作用域链与一个执行上下文相关,是内部上下文所有变量对象(包括父变量对象)的列表,用于变量查询。 作用域链的用途,是保证对执行环境有权访问的所有变量和函数的有序访问。
特点
代码在执行环境中执行时,执行环境会为变量对象创建作用域链。
作用域链是由变量对象组成的数据对象链。
作用域链的前端,始终是当前函数执行环境的变量对象。
作用域链的最后端,始终是全局执行环境的变量对象。
执行环境和作用域是两个完全不同的概念
函数的每次调用都有与之紧密相关的作用域和执行环境;从根本上来说,作用域是基于函数的,而执行环境是基于对象的(例如:全局执行环境即window对象);
作用域涉及到被调用函数中的变量访问,且不同的调用场景是不一样的;执行环境始终是this关键字的值,它是拥有当前所执行代码的对象的引用;每个执行环境都有一个与之关联的变量对象,环境中定义的所有变量和函数都保存在这个对象中;虽然我们编写的代码无法访问这个对象,但解析器在处理数据时会在后台使用它。
每一个函数都有一个执行环境,每个执行环境都有一个变量对象,当这些函数都没有执行时,就没有作用域链,当执行流进入某个函数时,作用域链就产生了,就将执行环境串联起来了,这些变量对象也就串联起来了,这样就能保证变量对象中的变量和函数能够被有序的访问。
——————————————————————————————————————————
明天计划的事情:
请假一天
遇到的问题:
已解决
收获:
之前不懂的已经明白了




评论