发表于: 2019-12-18 22:29:31
1 1282
今天做了什么
把项目部署到服务器上,配置服务器数据库,建表加数据
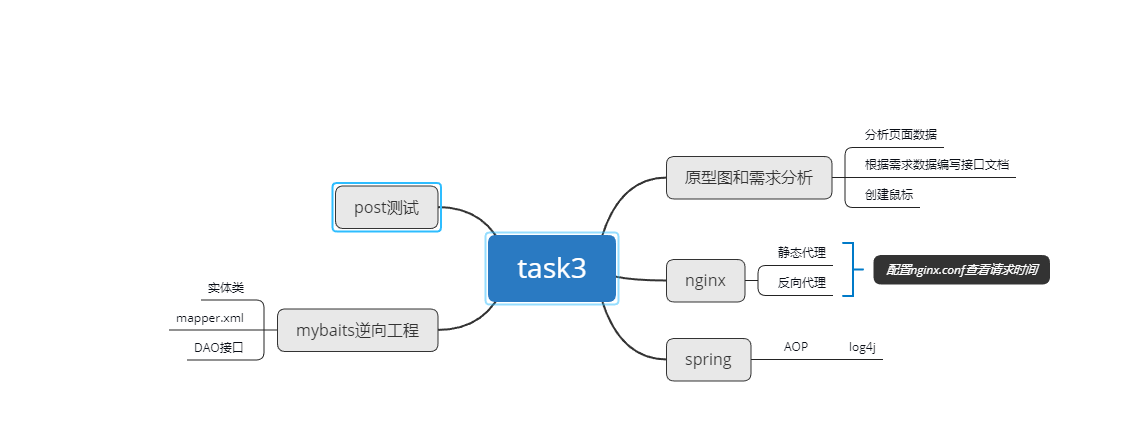
使用nginx代理
在nginx.conf中配置

后可在日志里查看请求时间
任务三深度思考
1.什么是代码生成,mybatis generator代码生成是怎么实现的,还有什么办法可以生成代码?
2.Mysql的一般而言应该配置多大的内存, 多大的硬盘 ,多大的连接数?
其余看具体情况
3.在端到端的请求当中,建立Http连接需要多久,Model通过JSP转成Json需要多久,Nginx调用Resin需要多久,Service访问DB需要多久,一个Sql语句执行的时间是多久。
controller执行接口方法(一个sql语句),大概在100ms左右
4.什么是Sql注入,应该怎么解决?对于未做SQL注入防范的程序,你可以直接通过调用接口删掉表吗?
5.JSP页面判断代码
5.在内存里拼装数据会节省时间吗?如果不能,为什么要选择单表查询,而不是直接拼装成Sql语句。
拼装sql语句查询容易造成sql语句疏忽,给有目的这造成sql注入来攻击,篡改数据库。
6.为什么一般而言,不允许使用连表查询,不允许使用复杂的Group By等语句,为什么不允许使用存储过程?
连表查询会在数据库中创建第三张表,放入两个表的数据,这样会加大数据库存储压力;当子查询的结果非常大的时候,数据库服务器的临时表空间会用完,因此多余的查询数据会丢失;可移植性差,维护麻烦
7.为什么响应时间一般不允许超过200MS,怎么查看一个请求从发起到结束,耗费在什么地方了?
通常来说,人的眼睛对200MS以上的延迟是有反应的,所以一般而言,一整个页面都应该在200MS之内完成;
可以通过查看日志了解请求在各个阶段的耗时;可以通过aop来记录这个时间
8.为什么要自测,仅仅使用Postman来测试足够吗?什么是本地测试,什么是在开发环境测试?在开发过程中,应该每天部署代码到开发环境吗,为什么?
自测检验程序是否有误;一般来说用postman测试是可以的;写好之后还需要放到不同的环境进行测试,web项目最终是要在服务器上跑的;开发过程还没接触,不了解
9.保存图片有几种方式?什么样的情景下应该使用哪一种?
(1) 图片比较小的话,直接以二进制方式写入数据库(base64的形式)
(2) 直接保存图片路径到数据库
(3) 图片存入对象存储,把图片对应的字符串存入数据库
其中(1)直接存图片到数据库中单独的表,实际使用很少
(2),(3)基本一致,区别在图片的位置,在自己的服务器,还是在第三方服务商,
路径可以采用 字符串拼接的方式, 前缀用来区别不同的位置,比如是京东云或者网易云的对象存储,或者是自己服务器的某个文件夹,方便后期迁移,后缀可以是图片的格式等,或者有压缩等其他处理图片的要求
10.为什么要先写单元测试?单元测试应该包括哪些?在正式打包的过程中,什么样的单元测试应该被屏蔽?在Maven里用什么方法可以跳过单元测试,单元测试应该被跳过吗。
单元测试可以检测写的接口是否有误;出入参,接口调用;mvn打包通过调用命令 mvn package -DskipTests来跳过测试打包,如果不跳过单元测试,打包会失败.
11.为什么提供假数据的时候要求,直接Controller接收请求,在JSP中写死数据返回以用做假数据?为什么提供假数据的时候要求数据完整,有分页尽可能给分页,数据尽可能真实?
假数据目的是模拟真实的数据传输情况,所以数据应该尽可能的真实,而不是乱写一通
12.为什么要写假数据,前后端联调的时候,应该什么时候商定接口文档,接口文档应该谁来维护,如果不提供假数据,会发生什么问题?
前端动态页面的开发需要依赖于后端提供的数据,项目开发初期商定;前后端一起维护;不提供假数据,前端无法进一步开发,影响开发进度
13.接口应该怎么定义?一个页面应该只对应一个接口吗?还是一个实体对应一个接口,让前端去组装数据?两者的使用场景是什么?
个人理解是按功能分,而不是一个页面一个接口,按功能来定义接口,前端要调用哪个功能,调用对应的接口就好了
14.多层分类应该怎么设计表结构,分别有什么问题?像文章分类这种需求,如果分类不确定,级别不确定,有可能动态调整,数据量和访问量又比较大,该怎么去设计?
首先要符合范式,再去调整表与表之间的关系
15.什么是实体表,什么是关系表,一对多和多对多应该怎么设计表?
实体表就是对应实际的对象的表,比如:学生表,老师表;
1.一对一、一对多和多对多都是指数据表与表中的数据关系,不是表与表之间的关系
2.一对一:一个班主任只属于一个班级,一个班级也只能有一个班主任
3.一对多:一个顾客对应多个订单,而一个订单只能对应一个客户
4.多对多:一个学生有多个老师,一个老师有多个学生
关系表是表示表与表之间的数据关系,我的理解是:关系表设计一般只存在多对多。
16.什么是外键,用处是什么,为什么不建议使用外键做关联?
保持数据的一致性、完整性。
主要目的是控制存储在外键表中的数据。
外键是能够保证数据的完整性,但会给系统带来很多缺陷。正是因为这些缺陷,才导致不推荐使用外键
17.什么是数据库范式,是否应该严格遵守范式,什么情况下应该不遵守范式?
第一范式(1NF):字段值具有原子性,不能再分(所有关系型数据库系统都满足第一范式);
例如:姓名字段,其中姓和名是一个整体,如果区分姓和名那么必须设立两个独立字段;
第二范式(2NF):一个表必须有主键,即每行数据都能被唯一的区分;
备注:必须先满足第一范式;
第三范式(3NF):一个表中不能包涵其他相关表中非关键字段的信息,即数据表不能有沉余字段;
备注:必须先满足第二范式;
数据库的三范式:
①字段不可分。
②有主键,非主键字段依赖主键。
③非主键字段不能互相依赖。
备注:往往我们在设计表中不能遵守第三范式,因为合理的沉余字段将会给我们减少join的查询;
例如:相册表中会添加图片的点击数字段,在相册图片表中也会添加图片的点击数字段;
当设计关系型数据库时,需要遵从不同的规范要求,设计出合理的关系型数据库,
这些不同的规范要求被称为不同的范式(Normal Form),
越高的范式数据库冗余越小。应用数据库范式可以带来许多好处,
但是最主要的目的是为了消除重复数据,减少数据冗余,让数据库内的数据更好的组织,
让磁盘空间得到更有效的利用。
范式的缺点:范式使查询变的相当复杂,在查询时需要更多的连接,
一些复合索引的列由于范式化的需要被分割到不同的表中,导致索引策略不佳。
任务三脑图:
遇到的的问题:无
明天要做什么:进入任务四




评论