发表于: 2019-12-09 10:45:26
7 1400
今天完成的事情:完成步骤1-16,环境都配好了,省略。
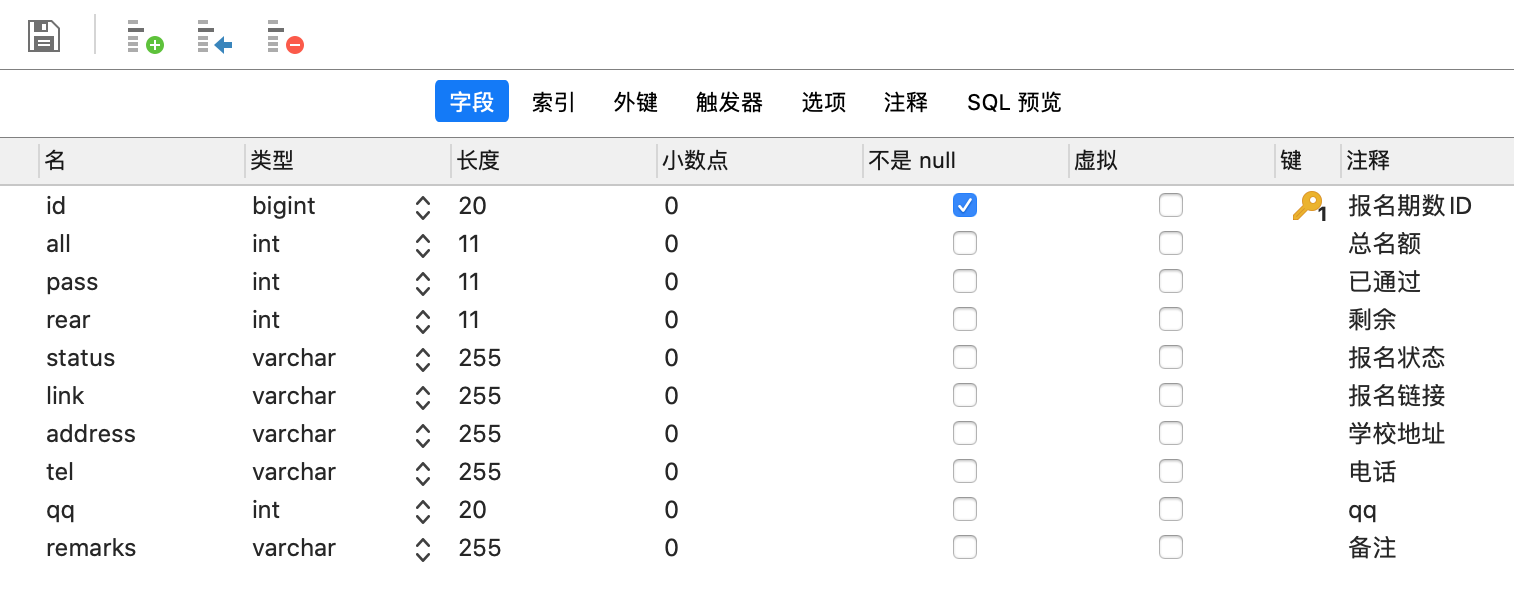
1.根据需求建立两个表:学校表school,学生表student,字段长度是根据以往在学校的经验选择的,没有进一步再进行了解,应该是够用的。
school表:
student表:
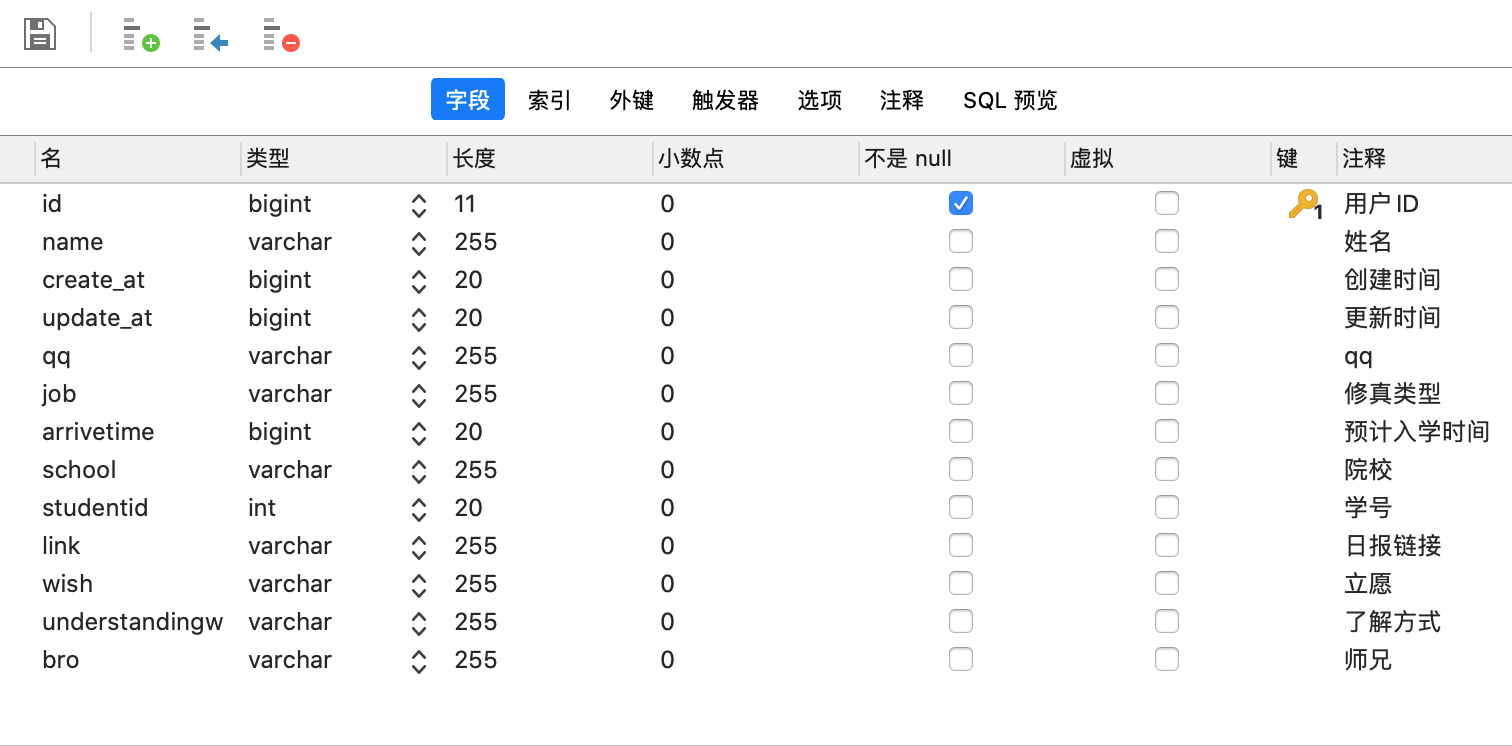
create_at,update_at(所有的时间都用Long),用long型存储时间戳,之后应该可以用代码将时间戳转换为正常显示的时间
时间戳(timestamp),一个能表示一份数据在某个特定时间之前已经存在的、 完整的、 可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间。
时间戳是自 1970 年 1 月 1 日(08:00:00 GMT)至当前时间的总秒数。
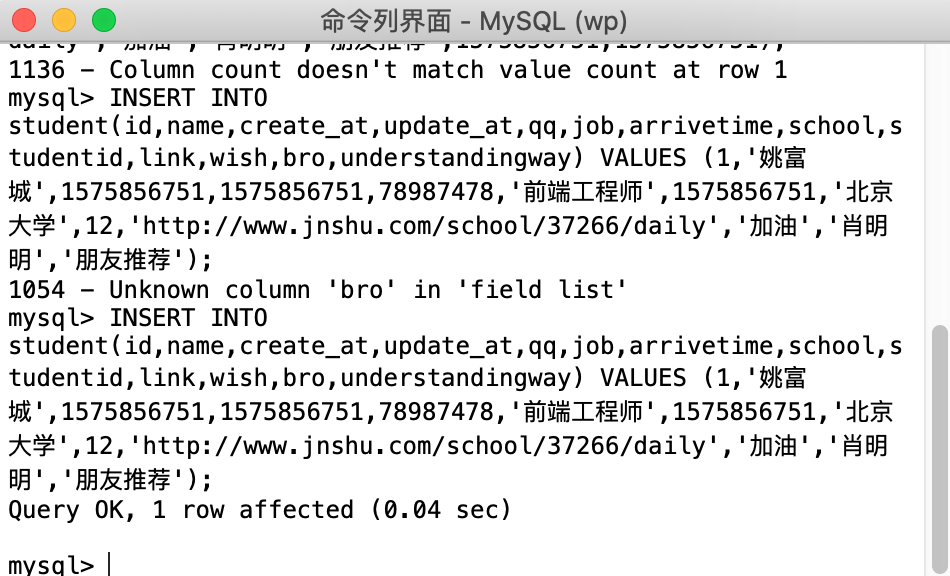
2.通过mysql成功插入数据
代码:
INSERT INTO student(id,name,create_at,update_at,qq,job,arrivetime,school,studentid,link,wish,bro,understandingway) VALUES (1,'姚富城',1575856751,1575856751,78987478,'前端工程师',1575856751,'北京大学',12,'http://www.jnshu.com/school/37266/daily','加油','肖明明','朋友推荐');

3.根据姓名查询表中数据

4.分别用Navciat和Sql语句去将本条数据记录的报名宣言改成老大最帅


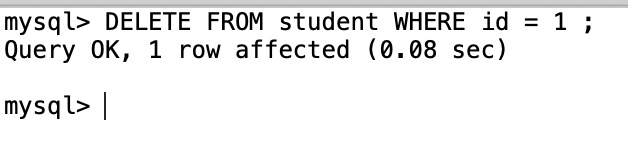
5.将表导出成Sql文件,并使用navciat和Sql分别尝试删除此条数据,并用之前备份的Sql恢复。
6.给姓名建索引,思考一下还应该给哪些数据建索引

对于应该给哪些数据建索引,我认为应该给使用频率高的数据建立,比如学号,生日,手机号,qq号这些方便查找的数据建索引来提高效率。
当你创建或设置主键的时候,mysql会自动添加一个与主键对应的唯一索引,不需要再做额外的添加。
navicat中直接可以建索引,如下图:

7.插入10条数据,查看有索引和无索引的情况下,Sql语句执行的效率
肯定是有索引执行效率高咯,不过当数据量很少时效果不明显,数据量越大,有索引的好处就越能体现出来
我将student表复制了一个,通过navicat中的新建查询功能测试的数据。其中student是有索引,copy无索引,结果却是无索引的快了一些。

8.JDK和JRE的区别
JVM屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
简单来说就是JDK包含JRE,JRE包含JVM的关系
9.下载配置maven
9.创建maven项目
10.在src/main/java下随便创建一个java文件,clean,install.查看本地的.m2下是否成功看到有Jar包
Mac系统把.m2文件隐藏了,但是可以通过命令行查看到.m2文件,里面是否有Jar包还是看不到,用了网上的方法也没找到。
明天计划的事情:
将任务一进行到步骤17,18(尽量吧)
遇到的问题:
1.mysql错误:Column count doesn't match value count at row 1(已解决)
意思是存储的数据与数据库表的字段类型定义不相匹配.
2..m2 文件里面是否有Jar包还是看不到,用了网上的方法也没找到。
收获:
1.Integer 类和 int 的区别
③、Integer 表示的是对象,用一个引用指向这个对象,而int是基本数据类型,直接存储数值。
2.MAC—mysql终端登录与退出
首先获得超级权限:sudo su
输入绝对路径 /usr/local/mysql/bin/mysql -u root -p
退出:quit
3.mysql中批量插入数据
(数据2)……
如TINYINT、SMALLINT、MEDIUMINT、INT、FLOAT、DOUBLE、DECIMAL等
5.建数据库,查数据库,删数据库
- 表的名称
- 字段名称
- 定义每个字段(类型、长度等)
通过命令行删除刚刚创建的表: drop table tutorials;
( value1, value2,...valueN );
12 .MySQL官方对索引的定义:
索引(Index)是帮助MySQL高效获取数据的数据结构。我们可以简单理解为:快速查找排好序的一种数据结构。Mysql索引主要有两种结构:B+Tree索引和Hash索引。我们平常所说的索引,如果没有特别指明,一般都是指B树结构组织的索引(B+Tree索引)。
13.导致SQL执行慢的原因
4)服务器调优及各个参数设置(调整my.cnf)
14.数据库查询是数据库的主要功能之一,最基本的查询算法是顺序查找(linear search)时间复杂度为O(n),显然在数据量很大时效率很低。优化的查找算法如二分查找(binary search)、二叉树查找(binary tree search)等,虽然查找效率提高了。但是各自对检索的数据都有要求:二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织)。所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构。这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构就是索引。




评论