发表于: 2019-12-03 23:24:45
1 920
今天完成的事:
1、简单查看性能瓶颈调优。
性能就是尽可能有限的资源里干更多的事情,所以需要有效的利用现有的资源,让CPU尽可能处于忙碌的状态。
如果说程序受限于当前CPU计算能力,CPU能够接近100%的利用率,并且代码业务逻辑无法简化,那么就说明系统性能只能通过增加处理器来提高性能。
但是如果随着系统增加压力,CPU使用率无法趋近100%,如下图,或者说系统性能随着负载增加而下降,那就说明系统存在瓶颈。
这里说的系统性能下降应该就是tps值下降、响应时间增大。
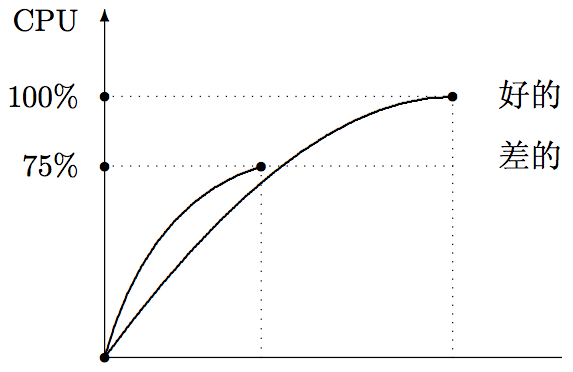
但是这里并不是说CPU就一直要达到100%的状态才行,而是说随着压力增加,可以达到100%的使用率。
通常情况下,cpu使用率在0-75%之间变化是比较正常的,如果经常在90%以上就不正常,那就需要查看占用cpu的进程,查找对应的原因了。
而系统负载(System Load),是对系统CPU繁忙程度的度量,即有多少进程等待被CPU调度(进程等待队列的长度)。
平均负载(Load Average),是一段时间内的系统平均负载,一般取1分钟、5分钟、15分钟。
把CPU比作一条(单核)马路,进程任务就是马路上的汽车,load就是马路的繁忙程度,或者说拥挤程度。相关范围如下。


但是这些数字并不是绝对的,建议把系统平均负载进行监控,根据更多的历史数据,判断负载变化趋势,当发现有明显升高时,再做分析调查。
在实际进行压测的时候,也就只能通过TPS和响应时间来查看性能瓶颈。
当发现TPS值随着线程增加,逐渐平稳,或者下降,就说明接近最大线程数了。
在最大线程数进行测试,查看CPU使用率、负载情况,如果说CPU使用率一直很低,没有达到过100%,可能是频繁的上下文切换,导致真正用在运算上的CPU时间片比较少。但是这方面的讲解没找到多少,大多都是说CPU的高占用率如何解决。
当CPU使用率一直维持在较高水平时,就需要查找对应消耗的进程,从而进行优化。
在进行CPU使用率查看的时候,同时也需要查看内存、文件IO、网络IO等资源的消耗情况,当消耗过多时,通常会造成系统响应速度变慢。
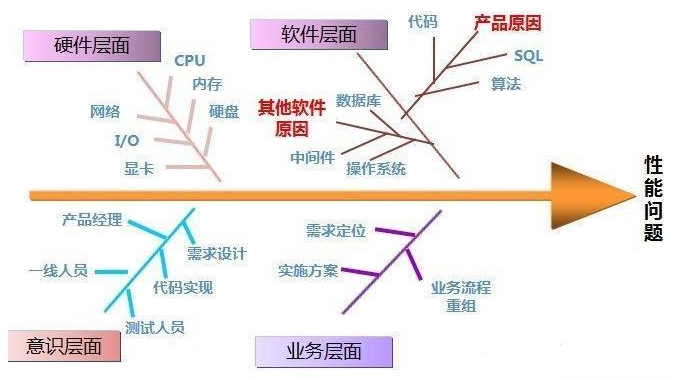
java应用对内存消耗主要是JVM堆内存上,正式环境中,很多JAVA应用会将-Xms、-Xmx设为相同值,避免运行时不断申请内存。JVM内存消耗过多会导致GC执行频繁,CPU消耗增加,应用线程执行速度严重下降。
java应用造成文件IO消耗严重主要是多个线程需要进行大量内容写入的动作(如频繁的日志写入),或磁盘设备本身的处理速度慢、文件系统慢、操作文件本身很大造成的。
以上这些的资源消耗,最终都是查找对应的消耗过高的进程,从而进行优化。
一般来说,压测都是放在服务器的局域网进行,说为了减少带宽的影响,但是其实如果用户并发达不到十万、百万的级别是没有必要在乎带宽的限制的,数据量小时,带宽影响可以忽略。
总结:
1、通常情况下,cpu使用率在0-75%之间变化是比较正常的,如果经常在90%以上就不正常。但是随着压力增加,可以达到100%的使用率。如果只能达到较小的使用率,也是不正常的,可能是频繁的上下文切换占用了太多CPU。
2、系统负载,就是对系统CPU繁忙程度的度量。一般分为如下。

3、性能瓶颈
实际压测时,通过TPS和响应时间来查看性能瓶颈。
当TPS值随着线程增加,逐渐平稳,或者下降,就说明接近最大线程数。
在最大线程数进行测试,查看CPU使用率、负载情况。同时也需要查看内存、文件IO、网络IO等资源的消耗情况,当消耗过多时,通常会造成系统响应速度变慢。即存在性能瓶颈。
查找对应过高消耗的进程,从而进行优化。
如:
1、JVM启动参数优化
原生内存优化,修改启动参数。
垃圾回收机制优化,合理设置堆大小、代空间的划分等。
2、编程代码优化
规范代码,对于一些静态变量、局部变量的使用,对象的创建等等,有很多讲究。
3、数据库优化
使用连接池减少连接次数,优化连接池配置。
使用缓存来避免重复的查询。
使用索引提高查询速度。
调整sql的编写,检查是否逻辑混乱,使用批量处理代替循环处理。
2、memcache和redis的区别。
两者性能都很高,可以把redis理解成是memcache的拓展,是更加重量级的实现。
(1)性能上:
redis只使用单核,而memcache可以使用多核,所以平均每个核上redis在存储小数据上比memcache要出色,但是在100k以上的数据,memcache要优于redis。
(2)内存使用效率、数据量大小:
使用简单的键值对存储,memcache内存利用率更高,但如果redis采用hash结构做键值对存储,由于其组合式的压缩,其内存利用率会高于memcache。
memcache单个key-value大小有限,一个value最大支持1MB,数据不能超过内存大小。redis最大支持512MB,且可以将数据保存到磁盘。
(3)操作便利上:
memcache数据结构单一,仅用来缓存数据,而redis支持更多的数据类型,主要有五种,String、Hash、List、Set和Sorted Set。也可以在服务器端直接对数据进行操作,减少网络IO次数和数据体积。
(4)可靠性、安全性:
memcache只是个内存缓存,对可靠性无要求,不支持数据持久化,断点或重启后数据会消失,但其稳定性是有保证的。并且可以存储图片、视频等。
redis更倾向于内存数据库,对可靠性要求较高,支持数据持久化(定期保存到磁盘)和数据恢复(数据丢失可通过aof恢复),允许单点故障,但是同时会付出性能代价。且支持数据备份,即master-slave主从模式的数据备份。
(5)应用场景:
memcache:动态系统中减轻数据库负载,提高性能;做缓存,适合多读少写,大数据量的情况(如人人网大量查询用户信息、好友信息、文章信息等)。
redis:适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统(如新浪微博的计数和微博发布部分系统,对数据安全性、读写要求很高)。
3、缓存雪崩、缓存击穿、缓存穿透。
缓存雪崩:
原有缓存失效,新缓存还未存储期间(例如,设置缓存时是相同的过期时间,在同一时刻会出现大量的缓存过期现象),所有原本应该访问缓存的请求都去查询数据库,从而对数据库造成极大压力,导致数据库宕(dang)机,形成连锁反应,早晨真个·造成整个系统崩溃。
解决方法:
(1)随机设置缓存的过期时间,避免同一时间大量数据过期。
(2)将热点数据设置为永不过期。
缓存击穿:
与缓存雪崩的意思一样,也是大量的请求查询缓存中没有的数据,会同时去数据库进行查询,导致数据库压力过大。
不同的是,缓存雪崩是指各种数据的请求,而击穿是指大量请求只查询同一个数据。
解决方法:
(1)添加互斥锁,即缓存中没有对应的数据,则获取锁后,再从数据库查询,并将数据存入缓存,没有释放锁之前,其他并发线程会等待设置的时间后,再去缓存取数据。
(2)设置热点数据永不过期。
缓存穿透:
是指请求缓存中和数据库都没有的数据,相当于进行了两次无用的查询,并返回查询结果null。
解决方法:
(1)最常见的是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据就会被这个bitmap拦截,避免对数据库的查询压力。
(2)也可以简单粗暴的对查询返回的null进行缓存,但是要将过期时间设置的很短,这样第二次就能到缓存中获取值了,不会查询数据库。
明天计划的事:
1、将短信验证纳入spring管理。
2、学习邮件发送验证码。
3、将邮件验证纳入spring管理。
遇到的问题:
系统性能瓶颈理解不到位。
收获:
1、查看如何定位系统性能瓶颈,以及优化方向。
2、了解了memcache与redis的区别。
3、了解缓存雪崩、击穿、穿透的概念以及解决方法。
任务总结:
任务名称:JAVA=TASK6
任务耗时:11.20-11.30,请假1天,实际共耗时10天,延期。
技能脑图:
个人:
官方:

任务总结:(任务进度是否符合预期,是否延期,如果延期,原因是什么,如何避免下次继续延期)
任务延期。纠结于压测结果,反复压测,对于响应时间慢的原因查找不明确,软件使用不熟悉,配置问题纠结太久,反而任务中重点的缓存没有花费太多时间,本末倒置。
如何避免下次延期:多问,多想。
脑图对比分析:
内容基本相同。
任务中遇到哪些疑难问题,最终如何解决的,有哪些值得分享的收获。
(对于任务总结应该更多的描述出任务所走的弯路以及遇到的困难,不应鼓励将知识点无脑的堆砌在总结之中)
1、任务六应该重点是学习缓存的相关知识,对于压测知道方法就好,测试结果不用太过于追求,基本上也优化不了多少,细节问题多注意,把整个流程理解就好。
2、缓存中memcache简单了解,redis需要多上心,可惜这里也没花费太多时间学习。
redis可以直接使用jedis,添加依赖,编写工具类,获取pool,取出对象,使用直接get、set即可。另外数据需要经过序列化才能存入缓存,取出使用反序列。可以在pojo中序列化实体类对象,也可以直接转为json进行序列化。而且redis的一个优点就是可以有多个数据类型配合使用。
3、压测使用badboy生成测试脚本,而后用jmeter进行压测,jmeter可以应对很多请求,还需要多多学习。




评论