发表于: 2019-11-28 23:07:50
1 1140
深度思考总结:(整合)
Mybatis有哪些常用标签?怎么使用标签来完成动态查询?
if choose(when、otherwise) trim(where、set) foreach等标签
!--动态查询sql 示例-->
<select id="getWorkerList_whereIf" parameterType="Worker" resultMap="WorkerMap">
select * from Worker
<where>
<if test="id!=null and id!=''">and id_=#{id}</if>
<if test="name!=null and name!=''">and name_ like "%"#{name}"%"</if>
<if test="sex!=null and sex!=''">and sex_=#{sex}</if>
<if test="job!=null and job!=''">and job_=#{job}</if>
<if test="hobby!=null and hobby!=''">and hobby_=#{hobby}</if>
</where>
什么叫反射?反射的坏处是什么?有哪些反射的应用场景?
java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
优点:运行期类型的判断,动态加载类,提高代码灵活度。
缺点:性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的java代码要慢很多。
反射的应用场景
反射是框架设计的灵魂。
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
举例:
①我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;
②Spring框架也用到很多反射机制,最经典的就是xml的配置模式。
Spring 通过 XML 配置模式装载 Bean 的过程:
1) 将程序内所有 XML 或 Properties 配置文件加载入内存中;
2)Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息;
3)使用反射机制,根据这个字符串获得某个类的Class实例;
4)动态配置实例的属性。
什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
Subversion,是一个开放源代码的版本控制系统,是cvs的重写版和改进版,是基于Apache的独立服务器,多数开源软件使用svn作为代码库。
说得简单一点SVN就是用于多个人共同开发同一个项目,共用资源的目的。
什么是版本管理工具
版本管理是软件配置管理的基础,它管理并保护开发者的软件资源。
它的主要功能有:
(1) 集中管理档案,安全授权机制:档案集中地存放在服务器上,经系统管理员授权给各个用户。用户通过check in和check out的方式访问服务器上的文件,未经授权的用户则无法访问服务器上的文件。
(2) 软件版本升级管理:每次登入时,在服务器上都会生成新的版本,任何版本都可以随时检出编辑。
(3) 加锁功能:在文件更新时保护文件,避免不同的用户更改同一文件时发生冲突。(不建议使用)
(4) 提供不同版本源程序的比较。
在版本控制中,我们只需要添加.sln、.vcxproj、vcxproj.filters 这三种文件。
svn是中心化的。git是分布式的
什么是AOP,适用于哪些场景,AOP的实现方案有哪些?
AOP:Aspect-OrientedProgramming,面向切面编程,
是OOP(Object-Oriented Programing,面向对象编程)的补充和完善,OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。
OOP定义从上到下的关系,aop定义了从左到右的关系,aop对原有代码侵入性小,也提高了代码复用率。
AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理。Aop 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。正如Avanade公司的高级方案构架师Adam Magee所说,AOP的核心思想就是“将应用程序中的商业逻辑同对其提供支持的通用服务进行分离。”
实现AOP的技术,主要分为两大类:
一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;
动态代理:
jdk :对实现接口的目标类生成代理类
cglib:对无实现接口的目标类生成代理类(相同父类)
二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
Map,List,Array,Set之间的关系是什么,分别适用于哪些场景,集合大家族还有哪些常见的类?
关系
Collection
--List:以特定顺序存储
--ArrayList(可变数组)、LinkList(链表)、Vector(线程安全可变数组)
--Set:不能包含重复的元素
--HashSet(哈希set,)、TreeSet(底层是树,有序)
--Map(键不重复,值可以重复)
--HashMap、HashTable(线程安全)、TreeMap
List:List接口是有序的,会精确的将元素插入到指定的位置,和下面的Set接口不同,List接口允许有相同元素
ArrayList:实现可变大小的数组,允许所有的元素,不是同步的,也就是没有同步方法
LinkList:允许null元素,通常在首部或者尾部操作,所以常被使用做堆栈(stack)、队列(queue)和双向队列(deque)
Vector:类似于ArrayList,但Vector是同步的,Stack继承自Vector
Set:是一种不包含重复元素的Collection接口
HashSet:不能有重复元素,底层是使用HashMap来实现的
Map:此接口实现的Key到Value的映射,一个Map中不能包含相同的Key,每个Key只能映射一个Value
HashTable:实现了一个Key-Value的哈希表,每一个非null元素都可作为Key或者Value,HashTable是同步的
HashMap:和HashTable的不同之处是,非同步的,且允许null元素的存在
Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
IoC(Inversion of Control)控制反转:程序将创建对象的权利交给第三方(spring容器)
直接实现就是DI(依赖注入)
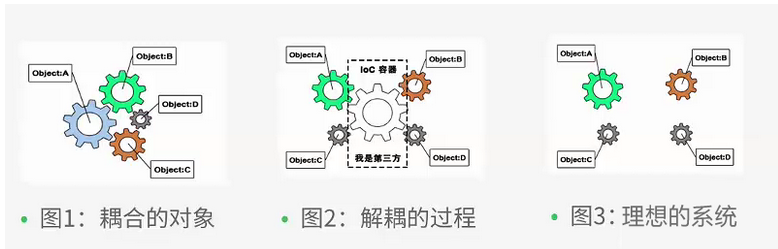
DI的三种方式:
Set注入
1、这是最简单的注入方式,假设有一个SpringAction,类中需要实例化一个SpringDao对象,那么就可以定义一个private的SpringDao成员变量,然后创建SpringDao的set方法(这是ioc的注入入口)。
2、随后编写spring的xml文件,<bean>中的name属性是class属性的一个别名,class属性指类的全名,因为在SpringAction中有一个公共属性Springdao,所以要在<bean>标签中创建一个<property>标签指定SpringDao。<property>标签中的name就是SpringAction类中的SpringDao属性名,ref指下面<bean name="springDao"...>,这样其实是spring将SpringDaoImpl对象实例化并且调用SpringAction的setSpringDao方法将SpringDao注入。
构造器注入
1、这种方式的注入是指带有参数的构造函数注入,看下面的例子,我创建了两个成员变量SpringDao和User,但是并未设置对象的set方法,所以就不能支持第一种注入方式,这里的注入方式是在SpringAction的构造函数中注入,也就是说在创建SpringAction对象时要将SpringDao和User两个参数值传进来。
2、在XML文件中同样不用<property>的形式,而是使用<constructor-arg>标签,ref属性同样指向其它<bean>标签的name属性。
静态工厂的方法注入
1、静态工厂顾名思义,就是通过调用静态工厂的方法来获取自己需要的对象,为了让spring管理所有对象,我们不能直接通过"工程类.静态方法()"来获取对象,而是依然通过spring注入的形式获取。
2、同样看关键类,这里我需要注入一个FactoryDao对象,这里看起来跟第一种注入一模一样,但是看随后的xml会发现有很大差别。
spring 实现ioc方式:
1.使用XML配置的方式实现IOC(xml结合注解)
采用XML方式配置Bean的时候,Bean的定义信息是和实现分离的,而采用注解的方式可以把两者合为一体,Bean的定义信息直接以注解的形式定义在实现类中,从而达到了零配置的目的。
2.使用Spring注解配置IOC(纯注解)
使用传统的xml配置完成IOC的,如果内容比较多则配置需花费很多时间,通过注解可以减轻工作量,但注解后修改要麻烦一些,偶合度会增加,应该根据需要选择合适的方法。
3.自动装配
使用了ApplicationContext初始化容器后获得需要的Bean,可以通过自动装配简化。
差别:
xml配置繁琐一些,但是只要修改相关配置文件,不用修改硬编码,利于修改,
注解的方式简单快捷,后续修改不方便
使用零配置和注解虽然方便,不需要编写麻烦的xml文件,但并非为了取代xml,应该根据实例需要选择,或二者结合使用,毕竟使用一个类作为容器的配置信息是硬编码的,不好在发布后修改
JDBCTemplate和JDBC
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,
可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
而多的这个template,就是模板,是Spring框架为我们提供的.
所以JDBCTemplate就是Spring对JDBC的封装,通俗点说就是Spring对jdbc的封装的模板
JDBC的原理就是通过Connection这个类获取数据库的连接,
然后通过PreparedStatement类处理SQL语句,再通过它的.setObject方法传入数据,
最后通过方法.executeUpdate()和.executeQuery()执行更新,这就是JDBC的基本原理。
JDBCTemplate简化了步骤,替我们完成了jdbc底层的细节操作,使我们只要重点关注SQL相关的部分.
指定数据库连接参数.
打开数据库连接.
预编译并执行SQL语句.
遍历查询结果(如果需要的话).
处理抛出的任何异常.
处理事务.
关闭数据库连接
怎么实现的?
SpringIOC容器将管理数据库连接的数据源当作普通Java Bean一样管理,
然后将数据源注入封装类JdbcTemplate中,:
JdbcTemplate的dataSource属性就是注入配置的数据源
Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
控制反转,解耦
什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
接口(interface)是一种用来定义程序的协议,它描述可属于任何类或结构的一组相关行为。
接口是一组规则的集合,它规定了实现本接口的类或接口必须拥有的一组规则。体现了自然界“如果你是……则必须能……”的理念。
接口是一种100%纯抽象的类,是无法被初始化的类。
(1)使用Interface是为了实现接口和实现类分离,对接口进行封装,这样一个接口可以对应多个实现类
(2)同一个方法也可能不止一个类调用,这个时候用接口实现分离的方法可以减少代码重复率,耦合度更低
(3)Impl是interface的实例,使用了Impl可以减少代码的重复率。
为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发生一次?
异常exception
异常是程序中的一些错误,但并不是所有的错误都是异常,并且错误有时候是可以避免的。
异常发生的原因有很多,通常包含以下几大类:
1.用户输入了非法数据。
2.要打开的文件不存在。
3.网络通信时连接中断,或者JVM内存溢出
使用 try 和 catch 关键字可以捕获异常。
try/catch 代码块放在异常可能发生的地方。try/catch代码块中的代码称为保护代码。
一个 try 代码块可以后面跟随多个 catch 代码块,叫多重捕获。
如果一个方法没有捕获一个检查性异常,那么该方法必须使用 throws 关键字来声明。throws 关键字放在方法签名的尾部。也可以使用 throw 关键字抛出一个异常,无论它是新实例化的还是刚捕获到的。(也可以使用throws抛出异常)
真实系统中会发生网络中断等异常(比如服务器波动,突然断网,断电等等),
可能很久也不发生,也可能一天好几次,看实际的场景
日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
(参考其他人回答)
1.较复杂的方法,(酌情而定,:进行了复杂的操作,调用多个其他service 或接口)
进入和结束打一
进入方法 >> 进入标记 入
log.info("定时任务>> 开始到期授信 creditContractIds={}", creditContractIds);
log.info("定时任务<< 成功到期授信 creditContractIds:{},notSuccessId={}", creditContractIds, noSuccessContractIds)
2.controller 层打下入参
3. 执行db 写操作打下结果
4.调用接口打下出参和入参!
5.throw 前打下 log.error
6. catch 内必打 error ,最后一个参数 注意打 e,可以把整个堆栈打出
log.error("定时到期授信失败! creditContractId={},
error={}", creditContractId, e.getMessage(), e);
为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试是指程序开发中,为了找到程序的bug,通常采用的一种调试手段,一步一步跟踪程序执行的流程,根据变量的值,找到错误的原因。
可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
在本地写代码时,如果程序出现问题了,在程序中打的各种log,可以帮助我们调试,找出问题,修改,测试,部署到服务器,再测试。但如果在真实项目中的呢,这样做虽然也可以,显然是不方便的。
真实项目中通过远程连接进行调试,服务端执行代码,而本地通过远程连接,到服务器获取数据和运行结果的方法。方式有很多如web、ide等
什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层
充血模型:层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic(业务逻辑层)只是简单封装部分业务逻辑以及控制事务、权限等
贫血模型在实体类中没有逻辑,更适合大型项目开发和合作开发,解耦也方便后期维护
为什么不可以用Select * from table?
select * from table 查询的是这个表中的所有列,但是一般情况下我们只需要查询某一个或多个字段,而不需要所有字段都查询,这样会影响效率,所以在明确知道自己所需字段的情况下不推荐使用SELECT FROM TABLE。
另外如果是要查询总条数,也不推荐使用SELECT count(*) FROM TABLE; 而推荐使用SELECT count(0) FROM TABLE。
clean,install,package,deploy分别代表什么含义?
clean 可将根目录下生成的target文件移除
install 项目安装到本地仓库了,并且是jar和pom同时安装。
package 项目打包到项目的target目录下。
deploy 是将jar包上传远程库的命令。
怎么样能让Maven跳过JUnit?
在pom的build标签下加入下面的代码。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version> 2.19.1</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
为什么要用Log4j来替代System.out.println?
log4j可以指定输出内容的级别,进行信息的筛选,而且可以输出到文本,方便发现问题和维护。更简单,快捷,可控
为什么DB的设计中要使用Long来替换掉Date类型?
Long类型方便传输与增改,date有点事直观,而在数据库中的时间往往不会直接提取给用户,数据库中的时间用来保存数据创建修改的时间戳。如create_at、update_at这种不会被用户直接读取的字段,就可以用long来提高效率。
自增ID有什么坏处?什么样的场景下不使用自增ID?
自增id首先需要是表的主键,在删除一行记录后,id也随之删除,但之后添加的一行记录中的id会在被删除的id后+1,而不是保持id连续性。
在需要该字段保持连续性的时候,不会使用自增id
什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
一个索引是存储的表中一个特定列的值数据结构(最常见的是B-Tree)。
索引是在表的列上创建。所以,要记住的关键点是索引包含一个表中列的值,并且这些值存储在一个数据结构中,索引是一种数据结构,一般是B-TREE 。
在数据量达到几万时,性能差别就比较直观。
使用索引原则:
1、装载数据后再建立索引。
2、频繁搜索的列可以作为索引。
3、在联接属性上建立索引(主外键)。
4、经常排序分组的列。
5、删除不经常使用的索引。
6、指定索引块的参数,如果将来会在表上执行大量的insert操作,
建立索引时设定较大的ptcfree。
7、指定索引所在的表空间,将表和索引放在不同的表空间上可以提高性能。
8、对大型索引,考试使用NOLOGGING子句创建大型索引。
唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn)中的数据列创建索引。
只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
mysql > ALTER TABLE {table_name} ADD INDEX index_name ( {column} )
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
在对该列进行增或改时,首先会检查是否重复,在执行增改操作,否则报出duplica错误,拒绝操作。
mysql > ALTER TABLE {table_name} ADD UNIQUE index_name ( {lolumn} )
对于经常修改或者作为where子句对象的字段,需要为该字段添加索引以增加效率。
如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
对一个字段做唯一索引之后,在执行sql语句时,会自动在后台根据索引查询是否有重复的值,不需要手动判断qq号是否存在。
CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
create_at是在行插入时以当时的时间为值插入。
update_at实在行一旦被修改的时候,以当时时间为值插入。
这两个字段作为数据的属性,不应该调用给外部的接口。
创建表时或者对已存在的表格的类型为varchar的字段的修改时,在varchar后括号内的数字即能存放的最大长度,这个长度是字符个数而不是字节数。
varchar目前的mysql版本最高支持65535字节,按照不同编码规则,对应20000左右或30000个左右的中文字符。
text的长度为存放最大长度为 65,535 个字符的字符串。
longtext存放最大长度为 4,294,967,295 个字符的字符串。
怎么进行分页数据的查询,如何判断是否有下一页?
分页查询就是将过多的结果在有限的界面上分成多页来显示,一般将分页查询分为两类:逻辑分页、物理分页。
逻辑分页:在用户第一次访问时,将数据库的所有记录全部查询出来添加到一个集合中,然后存放在session对象,再通过页码计算出当前页需要显示的数据,存储到一个小的list的集合中,再将其存储到request对象中,跳转到JSP页面,进行遍历显示。
当用户第二次访问时,只要不关闭浏览器,还可以从session中获取数据来显示。因为这种方法是在内存的session对象中进行计算分页显示的,而不是真正的将我们数据库进行分页的,所以叫做逻辑分页。
缺点:如果查询的数据量过大,session将耗费大量的内存;因为是在session中获取数据,如果第二次或者更多次的不关闭浏览器访问,会直接访问session,而不能保证数据是最新的。
物理分页,使用Mysql数据库中的limit机制来完成分页操作。因为是对数据库的数据进行分页条件查询,所以叫物理分页。每一次物理分页都会去连接数据库。
优点:数据能够保证最新,由于根据分页条件会查询出少量的数据,所以不会占用太多的内存。
MySQL数据库实现分页比较简单,提供了LIMIT函数。一般只需要直接写到sql语句后面就行了。
LIMIT子句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数。例如:
select * from table WHERE … LIMIT 10; #返回前10行
select * from table WHERE … LIMIT 0,10; #返回前10行
select * from table WHERE … LIMIT 10,20; #返回第10-20行数
maven是什么,和Ant有什么区别?
Maven是一个项目管理工具,它包含了一个项目对象模型 (POM:Project Object
Model),一组标准集合,一个项目生命周期(Project Lifecycle),一个依赖管理系统(Dependency Management
System),和用来运行定义在生命周期阶段(phase)中插件(plugin)目标(goal)的逻辑
pom文件用于配置需要引用的jar包以及一些诸如jdk版本配置的功能
clean、compile、package等对项目进行生命周期管理来适应后期对项目打包的需要
而ant是一个java的build工具,也是apache的项目,不过各方面都被maven代替并超越
任务一总结:
1.任务名称:Java=TASK1
2.成果链接:https://github.com/cooldown2019/learning
3.任务耗时:2019.11.14-2019.11.28,9.25正式报名,实际耗时14天
4.技能脑图
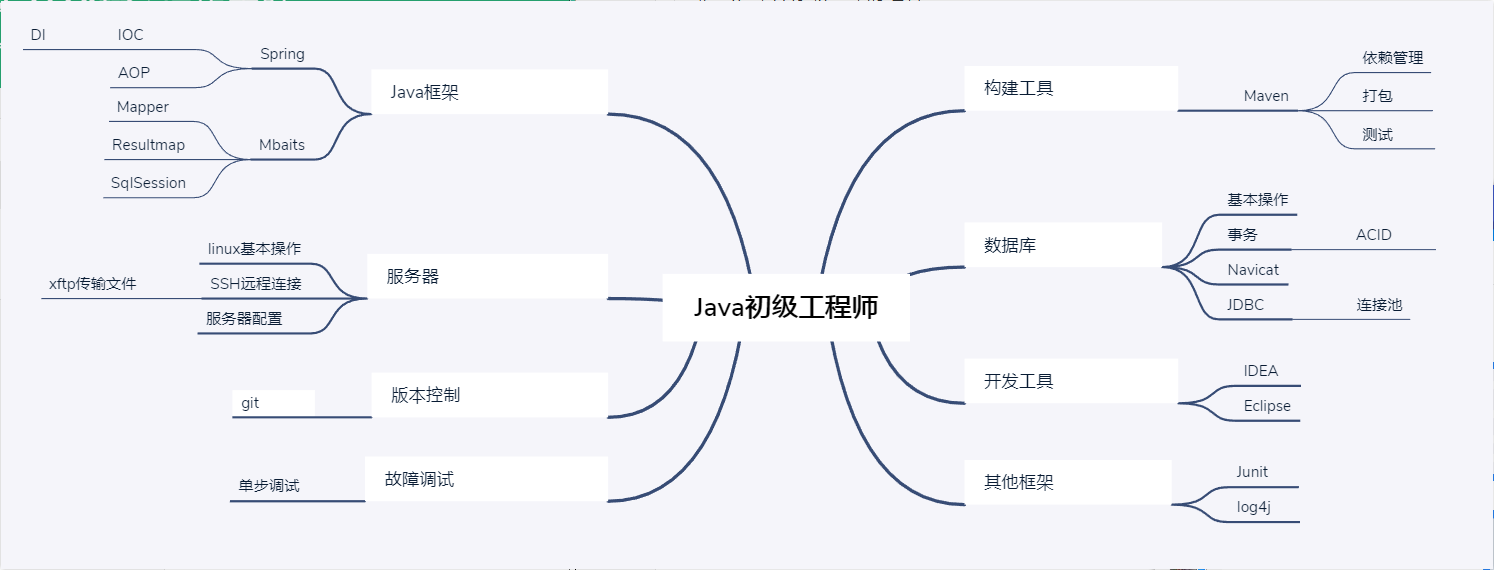
官方脑图
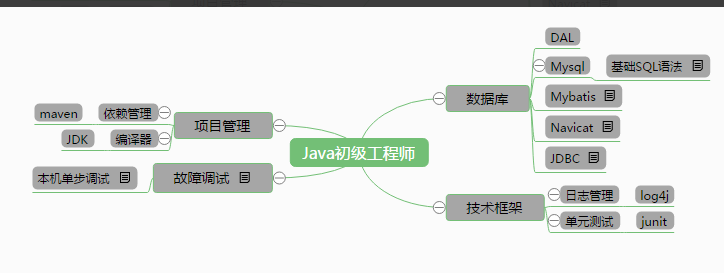
总结:
1.脑图中的知识点和工具,都使用过,但是对于知识点的理解不够,只是会使用,能够实现任务中的要求。
2.在任务完成后,重构代码时还是思路有时候不清晰,代码实践能力和理解还远远不够,还需要多加实践,从实践中慢慢理解。
3.异常遇到一些配置相关的问题,感觉配置有时候比写代码还麻烦、不过已经有了渐渐自己解决的能力
4.知识点:
MySQL和Navicat基本操作,SQL语句的增删改查,建索引等;
jdbc:加载驱动和数据源、获取连接、执行sql(Statement、PreparedStatemen)、处理显示结果、释放资源、异常处理
jdbcTemplate:Spring对数据库的操作在jdbc上面做了深层次的封装,使用spring的注入功能,可以把DataSource注册到JdbcTemplate。
jdbcTemplate提供五种方法:execute方法:可以用于执行任何SQL语句,一般用于执行DDL语句。
update方法:update方法用于执行新增、修改、删除等语句。
batchUpdate方法:batchUpdate方法用于执行批处理相关语句。
query方法:用于执行查询相关语句。
call方法:用于执行存储过程、函数相关语句。
mybatis:MyBatis 是支持普通 SQL 查询,存储过程和高级映射的优秀持久层框架,用xml配置文件或注解映射,简化代码量。
spring+mybatis: 整合了现有框架,核心是Ioc和Aop,使用Spring用注解或者xml的方式来实现对象的注入。
REST即Representational State Transfer的缩写,可译为"表现层状态转化”。
REST最大的几个特点为:资源、统一接口、URI和无状态。
资源:

统一接口:
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供完整资源数据)。
- PATCH(UPDATE):在服务器更新资源(客户端提供需要修改的资源数据)。
- DELETE(DELETE):从服务器删除资源。
- URI;
可以用一个URI(统一资源定位符)指向资源,即每个URI都对应一个特定的资源。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或识别符。
一般的,每个资源至少有一个URI与之对应,最典型的URI即URL。
- 无状态:
所谓无状态的,即所有的资源,都可以通过URI定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而改变。
@Controller
@RequestMapping("/date")
public class CurdDateTimeController {
@RequestMapping(value = "/getdate", method = RequestMethod.GET)
@ResponseBody
public Map<String, Object> getDate(HttpServletResponse response) throws IOException {
SimpleDateFormat tempDate = new SimpleDateFormat("yyyy-MM-dd");
String datetime = tempDate.format(new java.util.Date());
Map<String, Object> map = new HashMap<String, Object>();
map.put("data", datetime);
return map;
}
@RequestMapping(value = "/gettime", method = RequestMethod.GET)
@ResponseBody
public Map<String, Object> getTime(HttpServletResponse response) throws IOException {
SimpleDateFormat tempDate = new SimpleDateFormat("HH:mm:ss");
String datetime = tempDate.format(new java.util.Date());
Map<String, Object> map = new HashMap<String, Object>();
map.put("data", datetime);
return map;
}
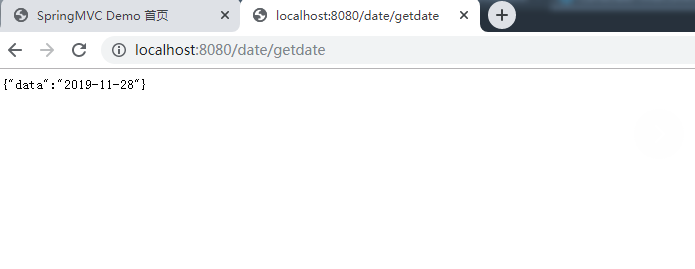
今天做了什么:
1.对任务一进行总结
2.理解restful 风格,使用springmvc编写rest接口
明天要做的事情:
继续学习springmvc和rest
按照接口定义格式,给出接口文档
学习使用jetty、resin、tomcat等




评论