发表于: 2019-11-26 23:06:28
1 1072
听说多线程插入会快一点所以使用多线程插入数据
多线程代码插入数据代码
public class ThreadInsertTest {
private int nThread;
private CountDownLatch startGate;
private CountDownLatch endGate;
public static void main(String[] args) {
int nThread = 10;
CountDownLatch startGate = new CountDownLatch(1);
CountDownLatch endGate = new CountDownLatch(nThread);
new ThreadInsertTest(nThread,startGate,endGate).start();
}
public void start() {
for (int i=0;i<nThread;i++) {
Thread thread = new Thread(new insert());
thread.start();
}
long startTime = System.currentTimeMillis();
startGate.countDown();
try {
endGate.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("插入数据总用时: " + (endTime- startTime) + "ms");
}
public ThreadInsertTest(int nThread, CountDownLatch startGate, CountDownLatch endGate) {
this.nThread = nThread;
this.startGate = startGate;
this.endGate = endGate;
}
class insert implements Runnable {
public void run() {
try {
startGate.await();
Connection conn = null;
PreparedStatement ps = null;
String sql = "INSERT INTO mytest (name,password,sex) VALUE ('name','password',1)";
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?characterEncoding=utf8&useSSL=true&useServerPrepStmts=false&rewriteBatchedStatements=true",
"root", "admin");
conn.setAutoCommit(false);
ps = conn.prepareStatement(sql);
long start = System.currentTimeMillis();
for (int i = 0; i < 3000000; i++) {
ps.addBatch(sql);
if (i % 100000 == 0) {
ps.executeBatch(); //10万条数据提交一次,以防内存溢出
conn.commit();
}
}
ps.executeBatch(); //最后再提交一次,若插入数据不是整数也没有关系
conn.commit();
long end = System.currentTimeMillis();
System.out.println("单个线程插入数据所需时间:" + (end - start) + "ms");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
if (ps != null) {
ps.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (conn != null) {
conn.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
endGate.countDown();
}
}
}
}
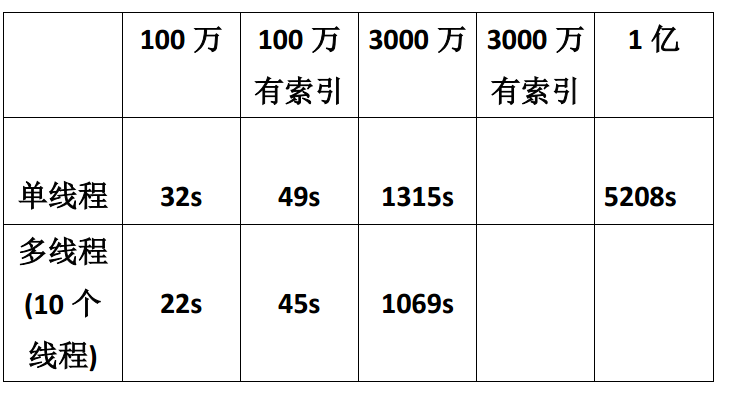
结果对比
深度思考
为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发生一次?
异常exception
异常是程序中的一些错误,但并不是所有的错误都是异常,并且错误有时候是可以避免的。
异常发生的原因有很多,通常包含以下几大类:
1.用户输入了非法数据。
2.要打开的文件不存在。
3.网络通信时连接中断,或者JVM内存溢出
使用 try 和 catch 关键字可以捕获异常。
try/catch 代码块放在异常可能发生的地方。try/catch代码块中的代码称为保护代码。
一个 try 代码块可以后面跟随多个 catch 代码块,叫多重捕获。
如果一个方法没有捕获一个检查性异常,那么该方法必须使用 throws 关键字来声明。throws 关键字放在方法签名的尾部。也可以使用 throw 关键字抛出一个异常,无论它是新实例化的还是刚捕获到的。(也可以使用throws抛出异常)
真实系统中会发生网络中断等异常(比如服务器波动,突然断网,断电等等),
可能很久也不发生,也可能一天好几次,看实际的场景
日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
(参考其他人回答)
1.较复杂的方法,(酌情而定,:进行了复杂的操作,调用多个其他service 或接口)
进入和结束打一
进入方法 >> 进入标记 入
log.info("定时任务>> 开始到期授信 creditContractIds={}", creditContractIds);
log.info("定时任务<< 成功到期授信 creditContractIds:{},notSuccessId={}", creditContractIds, noSuccessContractIds)
2.controller 层打下入参
3. 执行db 写操作打下结果
4.调用接口打下出参和入参!
5.throw 前打下 log.error
6. catch 内必打 error ,最后一个参数 注意打 e,可以把整个堆栈打出来
log.error("定时到期授信失败! creditContractId={},
error={}", creditContractId, e.getMessage(), e);
为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试是指程序开发中,为了找到程序的bug,通常采用的一种调试手段,一步一步跟踪程序执行的流程,根据变量的值,找到错误的原因。
可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
在本地写代码时,如果程序出现问题了,在程序中打的各种log,可以帮助我们调试,找出问题,修改,测试,部署到服务器,再测试。但如果在真实项目中的呢,这样做虽然也可以,显然是不方便的。
真实项目中通过远程连接进行调试,服务端执行代码,而本地通过远程连接,到服务器获取数据和运行结果的方法。方式有很多如web、ide等
什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层
充血模型:层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic(业务逻辑层)只是简单封装部分业务逻辑以及控制事务、权限等
贫血模型在实体类中没有逻辑,更适合大型项目开发和合作开发,解耦也方便后期维护
为什么不可以用Select * from table?
select * from table 查询的是这个表中的所有列,但是一般情况下我们只需要查询某一个或多个字段,而不需要所有字段都查询,这样会影响效率,所以在明确知道自己所需字段的情况下不推荐使用SELECT FROM TABLE。
另外如果是要查询总条数,也不推荐使用SELECT count(*) FROM TABLE; 而推荐使用SELECT count(0) FROM TABLE。
clean,install,package,deploy分别代表什么含义?
clean 可将根目录下生成的target文件移除
install 项目安装到本地仓库了,并且是jar和pom同时安装。
package 项目打包到项目的target目录下。
deploy 是将jar包上传远程库的命令。
怎么样能让Maven跳过JUnit?
在pom的build标签下加入下面的代码。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version> 2.19.1</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
为什么要用Log4j来替代System.out.println?
log4j可以指定输出内容的级别,进行信息的筛选,而且可以输出到文本,方便发现问题和维护。更简单,快捷,可控
为什么DB的设计中要使用Long来替换掉Date类型?
Long类型方便传输与增改,date有点事直观,而在数据库中的时间往往不会直接提取给用户,数据库中的时间用来保存数据创建修改的时间戳。如create_at、update_at这种不会被用户直接读取的字段,就可以用long来提高效率。
自增ID有什么坏处?什么样的场景下不使用自增ID?
自增id首先需要是表的主键,在删除一行记录后,id也随之删除,但之后添加的一行记录中的id会在被删除的id后+1,而不是保持id连续性。
在需要该字段保持连续性的时候,不会使用自增id
什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
一个索引是存储的表中一个特定列的值数据结构(最常见的是B-Tree)。
索引是在表的列上创建。所以,要记住的关键点是索引包含一个表中列的值,并且这些值存储在一个数据结构中,索引是一种数据结构,一般是B-TREE 。
在数据量达到几万时,性能差别就比较直观。
使用索引原则:
1、装载数据后再建立索引。
2、频繁搜索的列可以作为索引。
3、在联接属性上建立索引(主外键)。
4、经常排序分组的列。
5、删除不经常使用的索引。
6、指定索引块的参数,如果将来会在表上执行大量的insert操作,
建立索引时设定较大的ptcfree。
7、指定索引所在的表空间,将表和索引放在不同的表空间上可以提高性能。
8、对大型索引,考试使用NOLOGGING子句创建大型索引。
唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn)中的数据列创建索引。
只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
mysql > ALTER TABLE {table_name} ADD INDEX index_name ( {column} )
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
在对该列进行增或改时,首先会检查是否重复,在执行增改操作,否则报出duplica错误,拒绝操作。
mysql > ALTER TABLE {table_name} ADD UNIQUE index_name ( {lolumn} )
对于经常修改或者作为where子句对象的字段,需要为该字段添加索引以增加效率。
如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
对一个字段做唯一索引之后,在执行sql语句时,会自动在后台根据索引查询是否有重复的值,不需要手动判断qq号是否存在。
CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
create_at是在行插入时以当时的时间为值插入。
update_at实在行一旦被修改的时候,以当时时间为值插入。
这两个字段作为数据的属性,不应该调用给外部的接口。
修真类型应该是直接存储Varchar,还是应该存储int?
都可以,但修真类型用varchar不如用int查询效率高,但是用int需要对每个特定的值做一个对应修真类型的映射或定义。如该字段值为1代表“css”,2代表“Java”等。
varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
创建表时或者对已存在的表格的类型为varchar的字段的修改时,在varchar后括号内的数字即能存放的最大长度,这个长度是字符个数而不是字节数。
varchar目前的mysql版本最高支持65535字节,按照不同编码规则,对应20000左右或30000个左右的中文字符。
text的长度为存放最大长度为 65,535 个字符的字符串。
longtext存放最大长度为 4,294,967,295 个字符的字符串。
怎么进行分页数据的查询,如何判断是否有下一页?
MySQL数据库实现分页比较简单,提供了LIMIT函数。一般只需要直接写到sql语句后面就行了。
LIMIT子句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数。例如:
select * from table WHERE … LIMIT 10; #返回前10行
select * from table WHERE … LIMIT 0,10; #返回前10行
select * from table WHERE … LIMIT 10,20; #返回第10-20行数据
maven是什么,和Ant有什么区别?
Maven是一个项目管理工具,它包含了一个项目对象模型 (POM:Project Object Model),一组标准集合,一个项目生命周期(Project Lifecycle),一个依赖管理系统(Dependency Management System),和用来运行定义在生命周期阶段(phase)中插件(plugin)目标(goal)的逻辑
pom文件用于配置需要引用的jar包以及一些诸如jdk版本配置的功能
clean、compile、package等对项目进行生命周期管理来适应后期对项目打包的需求
而ant是一个java的build工具,也是apache的项目,不过各方面都被maven代替并超越
今天做了什么
1.完成一亿数据的插入,并比对得出结论
有索引的插入数据变慢,是因为要在插入数据的时候维护索引
单位插入时间随着数据量的增大而逐渐增大
2.修改剩下的demo代码,为删除,修改,添加方法增加返回值(Boolean,Boolean,int)
并把代码通过git pull到github仓库
3.完成任务一的深度思考,结合搜索得出答案
明天要做什么
- 1.如果demo代码有要修改的地方,对此进行修改
- 2.任务一总结
- 3.预习任务二的内容




评论