发表于: 2019-11-23 23:02:28
1 966
今天完成的事情:
spring整合redis
在service实现层加入缓存逻辑
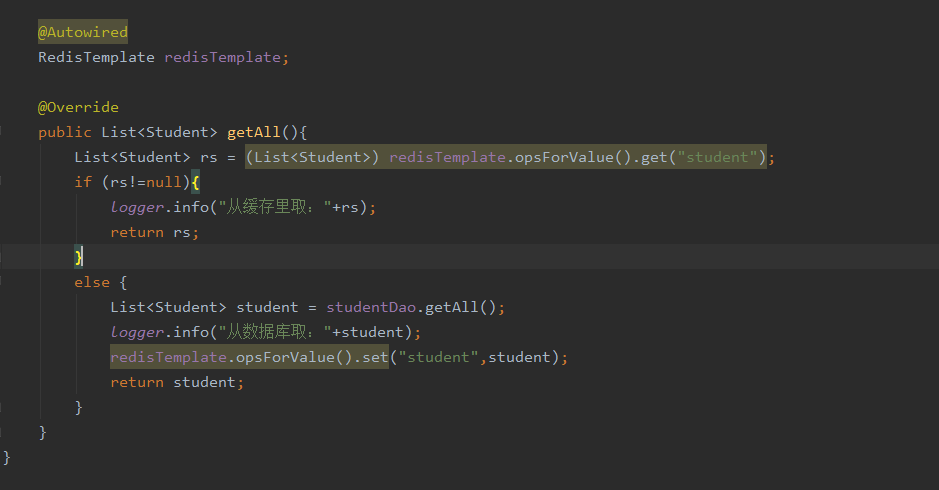
本地测试了好几次
发现2000线程的效果最为显著
以下第2,4条数据为加了缓存的数据

在服务器上测试20线程循环50

数据上没太多差别
但是在打开页面的时候明显要比之前使用memcached时要快很多,用户体验极好。。
明天计划的事情:nginx的负载均衡,前面的任务就有简单了解过。了解一下防穿透。开启任务七
遇到的问题:跟着网上的教程给redis设置了密码,在服务器上启动时突然蒙了。。。询问几位师兄发现他们都没有用到。。果断把配置文件里的密码给删掉,只需启动服务就会自动连接。
收获:
redis和memcached的区别
从数据结构上来说,redis在kv模式上,支持5中数据结构,String、list、hash、set、zset,并支持很多相关的计算,比如排序、阻塞等,而memcache只支持kv简单存储。所以当你的缓存中不只需要存储kv模型的数据时,redis丰富的数据操作空间,绝对是非常好的选择,另外说一句,利用redis可以高效的实现类似于单集群下的阻塞队列、锁及线程通信等功能。
从可靠性的角度来说,redis支持持久化,有快照和AOF两种方式,而memcache是纯的内存存储,不支持持久化的。
从内存管理方面来说,redis也有自己的内存机制,redis采用申请内存的方式,会把带过期时间的数据存放到一起,redis理论上能够存储比物理内存更多的数据,当数据超量时,会引发swap,把冷数据刷到磁盘上。而memcache把所有的数据存储在物理内存里。memcache使用预分配池管理,会提前把内存分为多个slab,slab又分成多个不等大小的chunk,chunk从最小的开始,根据增长因子增长内存大小。redis更适合做数据存储,memcache更适合做缓存,memcache在存储速度方面也会比redis这种申请内存的方式来的快。
从数据一致性来说,memcache提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 redis是串行操作,所以不用考虑数据一致性的问题。
从IO角度来说,选用的I/O多路复用模型,虽然单线程不用考虑锁等问题,但是还要执行kv数据之外的一些排序、聚合功能,复杂度比较高。memcache也选用非阻塞的I/O多路复用模型,速度更快一些。
从线程角度来说,memcahce使用多线程,主线程listen,多个worker子线程执行读写,可能会出现锁冲突。redis是单线程的,这样虽然不用考虑锁对插入修改数据造成的时间的影响,但是无法利用多核提高整体的吞吐量,只能选择多开redis来解决。
从集群方面来说,redis天然支持高可用集群,支持主从,而memcache需要自己实现类似一致性hash的负载均衡算法才能解决集群的问题,扩展性比较低。
另外,redis集成了事务、复制、lua脚本等多种功能,功能更全。redis功能这么全,是不是什么情况下都使用redis就行了呢?
非也,redis确实比memcache功能更全,集成更方便,但是memcache相比redis在内存、线程、IO角度来说都有一定的优势,可以利用cpu提高机器性能,在不考虑扩展性和持久性的访问频繁的情况下,只存储kv格式的数据,建议使用memcache,memcache更像是个缓存,而redis更偏向与一个存储数据的系统。但是,觉得不要拿redis当数据库用。
了解Redis的缓存雪崩,缓存击穿
缓存雪崩,是指在某一个时间段,缓存集中过期失效。
产生雪崩的原因之一,比如马上就要到双十一零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。




评论