发表于: 2019-11-19 23:06:25
1 1043
基础部分暂时就复习到这里了 后面发现再查缺补漏了
1.集合的体系结构:
|--如果元素的HashCode值相同,才会判断equals是否为true。|--如果元素的hashcode值不同,不会调用equals。|--注意,对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashcode和equals方法。
编写一个泛型方法,实现指定位置数组元素的交换编写一个泛型方法,接收一个任意数组,并颠倒数组中的所有元素注意:只有对象类型才能作为泛型方法的实际参数在泛型中可以同时有多个类型public <K,V> V getValue(K key) return { return map.get(key)}
//自定义泛型练习
public class ArraysUtil {
//编写一个泛形方法,实现指定位置数组元素的交换
public static <T> void exchange(T[] t,int index1,int index2){
T temp = t[index1];
t[index1] = t[index2];
t[index2] = temp;
}
//编写一个泛形方法,接收一个任意数组,并颠倒数组中的所有元素
public static <T> void reverse(T[] t){
int startIndex = 0;
int endIndex = t.length -1;
while(startIndex<endIndex){
T temp = t[startIndex];
t[startIndex] = t[endIndex];
t[endIndex] = temp;
startIndex++;
endIndex--;
}
}
}
注意:运行期间不存在泛型
理解MVC
MVC和三层架构的区别:
M 即Model(模型层),主要负责处理业务逻辑以及数据库的交互
V 即View(视图层),主要负责显示数据和提交数据
C 即Controller(控制层),主要是永作辅助捕获请求并控制请求转发
三层
UI界面层
BLL业务逻辑层(spring)
DAL数据访问层(mybatis)
三层是基于业务逻辑来分的,而mvc是基于页面来分的
MVC模式是一种复合设计模式,一种解决方案
三层是种软件架构,通过接口实现编程
三层模式是体系结构模式,MVC是设计模式
三层模式又可归于部署模式,MVC可归于表示模式
优点 别问 问就是解耦合
spring注解:
使用注解时配置文件的写法
<?xml version="1.0" encoding="UTF-8"?> <span style="font-size:18px;"><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-3.0.xsd">
<aop:aspectj-autoproxy/> <context:annotation-config/> <context:component-scan base-package="com.test" /> </beans>
@Autowired
Spring2.5引入了 @Autowired 注解,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。另外,通过 @Autowired 可以消除get,set方法。 @Autowired是根据类型进行自动转配的。
这里要注意 @Resource也可以实现自动装配,但是 @Resource默认是按照名称进行自动装配。
@Autowired 根据bean 类型从spring 上线文中进行查找,注册类型必须唯一,否则报异常。与 @Resource 的区别在于,@Resource 允许通过bean 名称或bean 类型两种方式进行查找 @Autowired(required=false) 表示,如果spring 上下文中没有找到该类型的bean 时, 才会使用new SoftPMServiceImpl();
@Autowired 标注作用于 Map 类型时,如果 Map 的 key 为 String 类型,则 Spring 会将容器中所有类型符合 Map 的 value 对应的类型的 Bean 增加进来,用 Bean 的 id 或 name 作为 Map 的 key。
@Autowired 还有一个作用就是,如果将其标注在 BeanFactory 类型、ApplicationContext 类型、ResourceLoader 类型、ApplicationEventPublisher 类型、MessageSource 类型上,那么 Spring 会自动注入这些实现类的实例,不需要额外的操作。
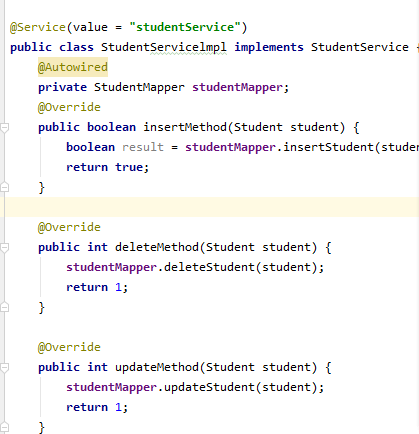
学习了两个简单的注解
@Controller
在SpringMVC 中,控制器Controller负责处理由DispatcherServlet分发的请求,它把用户请求的数据经过业务处理层处理之后封装成一个Model,然后再把该Model返回给对应的View进行展示。
Controller不会直接依赖于HttpServletRequest 和HttpServletResponse等HttpServlet对象,它们可以通过Controller的方法参数灵活的获取到。
整理后的结构
和加入注解
明天的计划 搭建GIT上传GIT 学习GIT 写任务总结 准备小课堂




评论