今天完成的事情:
通过远程连接Mysql,使用自定义域名并通过配置本地Host来配置DB连接文件
Hosts文件主要作用是定义IP地址和主机名的映射关系,是一个映射IP地址和主机名的规定。
当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,一旦找到,浏览器会立即打开对应网页,如果没有找到,则浏览器会将网址提交DNS服务器进行IP地址解析。当登录一些404not found网站时可以更改host达到这样的目的!当然任务一只用本地使用就可以,不用在浏览器上使用。
用管理员模式打开更改
用Navicat进行连接,成功
ps :如果没有权限修改hosts 或者无法保存 看这篇文章
深度思考
1.Mybatis有哪些常用标签?怎么使用标签来完成动态查询?
目前常用的:
定义sql语句: select(属性有id parameterType传参类型 resultType结果类型)
insert delete update (属性只有id 和 paeameterType)
我们在任务中的增删查改中就用这个
java对象属性: resultMap
有三种情况会用到ResultMap:1、如果查询结果字段与po的字段名称不对应;2、查询结果的字段类型与po的字段类型不一致;3、查询结果对应多个po
控制动态sql拼接:if、foreach、choose
格式化输出:where、set、trim
动态查询则需要使用动态标签,组成动态sql语句
if if 标签通常用于 WHERE 语句、UPDATE 语句、INSERT 语句中,通过判断参数值来决定是否使用某个查询条件、判断是否更新某一个字段、判断是否插入某个字段的值。
判断某个条件是否成立 ,如果成立 则返回
举例:如果uesrname不为空 返回此条件
where 如果它包含的标签有返回值 则插入一个where
如果标签的返回值为and 或 or 开头, 则剔除
常用方法 if+where 来剔除多个if 标签中易出现的 where and 语法错误
choose 这个很好理解 类似Java的switch语句 从头开始 哪个符合条件用哪个 否则就判断下一个
set 若它包含的标签若有返回值 就插入一个set
主要用于更新操作 因为更新语句里需要用set赋新值
trim trim标记是一个格式化的标记,可以完成set或者是where标记的功能
里面包含prefix:前缀 prefixoverride:去掉第一个and或者是or 可以替代if+where语句
里面包含suffix:后缀 suffixoverride:去掉最后一个逗号 可以替代if+set语句
foreach foreach 标签主要用于构建 in 条件,可在 sql 中对集合进行迭代。也常用到批量删除、添加等操作中。
虽然有概念摆在这里,但还是要多练习才能理解。
2.什么叫反射?反射的坏处是什么?有哪些反射的应用场景?
反射定义: JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属 性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。 反射的坏处: 1.不安全,当我们使用反射时,其实是在动态的获取信息,暴露类和方法的内部, 那么对于被获取信息的一方来说,是不安全的。
2.反射需要以牺牲性能为代价
曾经用过的反射 JDBC加载驱动
ClassforName("com.mysql.jdbc.Driver")
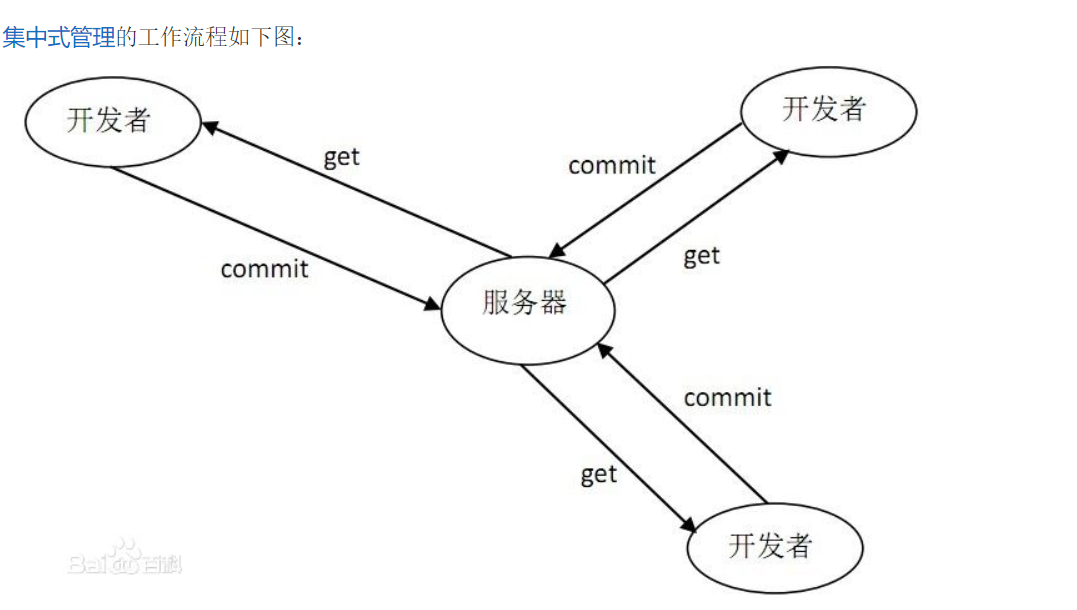
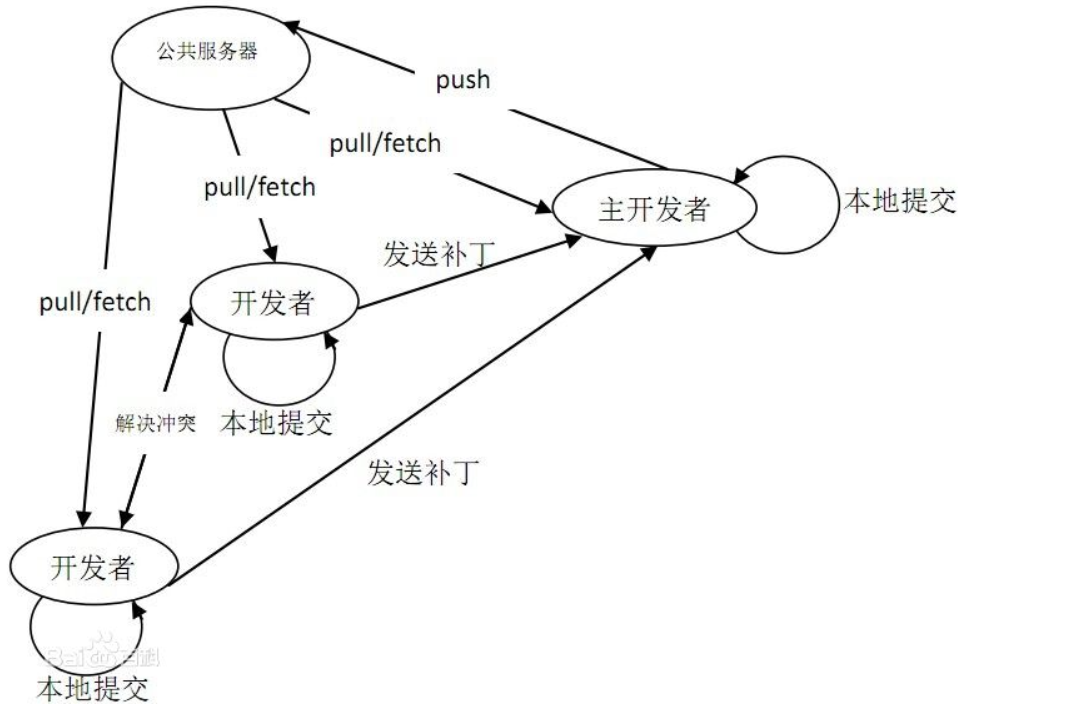
3.什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
SVN: 开放源代码的版本控制系统
小乌龟: 用于简化操作SVN的软件
文件版本号 每编制完成以此 就会修改一次版本号。
主要是对某个文件某个时刻的标识, 方便另一个开发者查看此文件编修更新的状况
GIT:(分布式版本控制系统)
SVN对中文支持好,操作简单,使用没有难度,美工人员,产品人员,测试人员,实施人员都可轻松上手。使用界面统一,功能完善,操作方便。
对程序源代码进行差异化的版本管理,代码库占极少的空间。易于代码的分支化管理。不支持中文,图形界面支持差,使用难度大。不易推广。
适用场景
个人开发适合git 团队开发适合svn
参考:
4.什么是AOP,适用于哪些场景,AOP的实现方案有哪些?
AOP是spring下的一个功能
aop做了什么:
就是把 安全,事物,日志等,先定义好
然后通过注解的方法
放在目标类(targer)的 方法前(连接点) 方法后(连接点)等地方
减少重复的代码量
适用场景:
适用于出现大量提示及相同代码的场景,比如每个方法前需要输出一个信息 方法后输出一个信息
用aop即可减少代码量
实现方案:
首先,引入aop jar包
其次,xml文件里配置 aop
1.先创建一个类,比如:MyAspect.java
2.在类上使用 @Aspect 注解 使之成为切面类
3.在类上使用 @Component 注解 把切面类加入到IOC容器中,或者在spring配置文件中创建bean也可以,也可以在它上面加@Service注解,目的就是让它实例化
@Aspect注解方式来实现前置通知、返回通知、后置通知、异常通知、环绕通知。
5.Map,List,Array,Set之间的关系是什么,分别适用于哪些场景,集合大家族还有哪些常见的类?
array是 数组
map list set是 集合
数组的长度是固定的,集合长度可变
List:
1.可以允许重复的对象。
2.可以插入多个null元素。
3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
4.常用的实现类有 ArrayList、 LinkedList
ArrayList 最为流行,它提供了使用索引的随意访问 适合查询
而 LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适。
Set:
1.不允许重复对象
2. 无序容器,你无法保证每个元素的存储顺序
3. 只允许一个 null 元素
4.Set 接口最流行的实现类是 HashSet、最流行的是基于 HashMap 实现的 HashSet。 这个我们还没用过
Map:
1.Map不是collection的子接口或者实现类。Map是一个接口。
2.Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
3. TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
4. Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
5.Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
这个目前也没怎么用
6.Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
3种
1.XML 在xml配置文件里增加bean 然后通过classpathapplicationcontext获取xml文件, 再用applicationcontext读取容器里bean
2.spring注解 @component 注解类 (等同于在xml文件里注册一个bean 不用在配置xml) 等效的有(@reposity @service @controller)
前提:需要在xml文件对被注解类的所属包进行扫描
3.自动装配(也属于注解) 使用自动装配可以不用applicationContext 用第二种注解在ioc容器注册bean
即可用@autowired注入bean 结合@autowired使用的是 @qualifier("xxx") 用于选择多个bean时使用
应该选择xml 因为sql语句 没有写在代码上。 如果要更改代码的话,更方便和容易修改。
7.JDBCTemplate和JDBC
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API
template中文意思为模板, 是Spring框架为我们提供的
JDBCTemplate就是Spring对JDBC的封装,通俗点说就是Spring对jdbc的封装的模板
jdbc每次使用完都要开启数据库,再关闭数据库 代码重复量很大
而jdbctemplate不需要 ioc容器自动帮我们开启关闭连接 并建立类与类之间的关系
8.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
ioc是一种变成思想,由主动编程变为被动编程
核心概念分两个
控制反转
控制 : 即谁来控制对象的创造,以前对象创建是程序创建,现在变为spring创建
反转: 指程序本身不去创建对象,从而变为被动接受对象
总结:以前对象由程序本身来创建,使用spring后,程序变为被动接受spring创建好的对象。
依赖注入
依赖: 指bean对象创建依赖于容器
注入:指bean对象依由容器来设置和装配
总结:在ioc容器中,依赖注入可以动态 向某个对象提供它所需的其他对象,形成相互间的依赖
如果使用传统的new对象 我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试
而使用ioc,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是 松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
参考: https://blog.csdn.net/qq_42709262/article/details/81951402
9.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
一个实体类会将接口和实现方法混在一起,后期不易修改
interface和impl的好处是: 一个接口可以有多个impl ,体现着多态性
10.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
因为程序运行过程中总是会出现各种各样的异常,而出现异常,代码就会终止。
try/catch在捕获和抛出异常时使用 可以使程序try即使出现异常,也能运行下去catch 并显示具体的错误 exception
会出现db连接不上的错误,尤其是远程连接lunix服务器的DB 网络出问题就会中断
还有一种情况是数据库连接后,8小时不访问,会自动断开,不管是本地还是服务器,不过可以自己修改。
11.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
使用log4j打印日志, 在出参入参的位置打印 ,或者在判断成功与否的地方打印
需要打印出正在操作的对象 属性的变化 就用 (info)
容易出BUG的地方,就打印异常内容(debug)等。
12.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
为了缩小错误查看的范围。 一步一步查看变量的值变化,找到错误的原因。
13.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
14.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
1.贫血模型: 在model中 仅包含状态(属性),不包含行为(方法) 采用这种设计时 需要分离出DB层 专门用于数据库操作
2.充血模型: model中既包括状态 也包括行为 是最符合面向对象的设计方式。
为什么要使用充血模型:
系统的层次结构清楚,各层之间单向依赖,耦合度低,方便后期的更新与维护。
15.为什么不可以用Select * from table?
Select * from table 是查询表的所有列 速度慢 影响效率
正常情况下我们只需要根据列名 来查找表的行信息
16.clean,install,package,deploy分别代表什么含义?
maven是一个项目管理和整合的工具,为开发者提供了标准的目录和默认的完整构建生命周期的框架。Maven工程结构和内容被定义在pom.xml中,maven提供对项目提供的周期(Lifecycle)clean,validate,compile,test,package,install,site,deploy。
Mvn clean:我们在使用maven的构建项目会产生一个target文件,但我们修改了代码后就需要使用clean清楚target,重新生成target。
Mvn test执行 mvn test命令,完成单元测试操作执行完毕后,会在target目录中生成三个文件夹:surefire、surefire-reports(测试报告)、test-classes(测试的字节码文件)
Mvn package执行 mvn package命令,完成打包操作执行完毕后,会在target目录中生成一个文件,该文件可以是jar、war等
Mvn install执行 mvn install命令,完成将打好的jar包安装到本地仓库的操作执行完毕后,会在本地仓库中出现安装后的jar包,方便其他工程引用
Mvn deploy将打好的包拷贝到远程的repository,使得其他的开发者或者工程可以共享。
17.怎么样能让Maven跳过JUnit?
1.mvn package - Dmaven.test.skip=true
不执行测试用例,也不编译测试用例类。
或者为pom.xml添加plugin
<plugin>
<groupId>org.apache.maven.plugin</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.1</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.5</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
2.mvn package =Dskip Tests
不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下。
或者修改pom.xml文件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.5</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
18.为什么要用Log4j来替代System.out.println?
因为system.out.println只能输出到控制台
而log4j还可以输出日志文件,并且根据级别进行分类
而且,项目上线测试时,没有开发工具显示,需要手动打日志
19.为什么DB的设计中要使用Long来替换掉Date类型?
1.有利于计算时间差
2.方便java与数据库之间的传输
20.自增ID有什么坏处?什么样的场景下不使用自增ID?
坏处:不存在连续性,也就是说若表中存有3行数据,ID字段为1,2,3 那么当删除字段2时就变为1,3,不具有连续性合并表会出现ID重复的情况,上面说个使用自增ID能够在单个表中保证ID字段唯一,但两个表何为1个表,时不具有这种性质的。
不推荐使用的场景:正是因为自增ID的缺点也就是无法在多个表中,或者多个数据库中保持ID主键唯一不重复,所以若是使用分布式数据库以及数据合并的情况下时不能使用自增ID的。需要频繁操作的表也不推荐使用
21.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
数据库索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
索引的一个主要目的就是加快检索表中数据的方法,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构。
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
22.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引:(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。列中包含可以复的值
因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn)中的数据列创建索引。
只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
唯一索引:使数据列只包含彼此各不相同的值
好处:1.简化索引管理工作,使索引更有效率
2.mysql插入时会自动检测是否重复,重复则拒绝插入,避免我们的数据出现重复
什么时候需要用: 列中不需要重复的值的时候 比如身份证号码 学生学号等内容
23.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要, 一旦你建立唯一索引
mysql插入时会自动检测是否重复,重复则拒绝插入,避免我们的数据出现重复
24.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
CreateAt 创建时获取的 不会变化 也不能赋值
UpdateAt 是对数据进行修改操作时 修改才会变化 也不能自己赋值
如果是查询,可以开放给外部调用的接口
如果是修改或删除,是不能调用的,只能由代码来自动控制
25.修真类型应该是直接存储Varchar,还是应该存储int?
varchar 因为不如int效率高
26.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
varchar(m),指的是m字符,无论存放的是数字、字母还是UTF8汉字(每个汉字3字节)都可以存放m个
最大大小是65532字节 ( mysql5.0以上版本 否则就是255 )
text的长度为存放最大长度为 65,535 个字符的字符串。
longtext存放最大长度为 4,294,967,295 个字符的字符串。
27.怎么进行分页数据的查询,如何判断是否有下一页?
MySQL数据库实现分页比较简单,提供了LIMIT函数。
LIMIT子句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数。例如:
select * from table WHERE … LIMIT 10; #返回前10行
select * from table WHERE … LIMIT 0,10; #返回前10行
select * from table WHERE … LIMIT 10,20; #返回第10-20行数据
28.maven是什么,和Ant有什么区别?
Ant是软件构建工具,Maven的定位是软件项目管理和理解工具。Maven除了具备Ant的功能外,还增加了以下主要的功能:
1)使用Project Object Model来对软件项目管理;
2)内置了更多的隐式规则,使得构建文件更加简单;
3)内置依赖管理和Repository来实现依赖的管理和统一存储;(这个我们经常用)
4)内置了软件构建的生命周期;(maven life)
参考: https://blog.csdn.net/q649381130/article/details/77498892
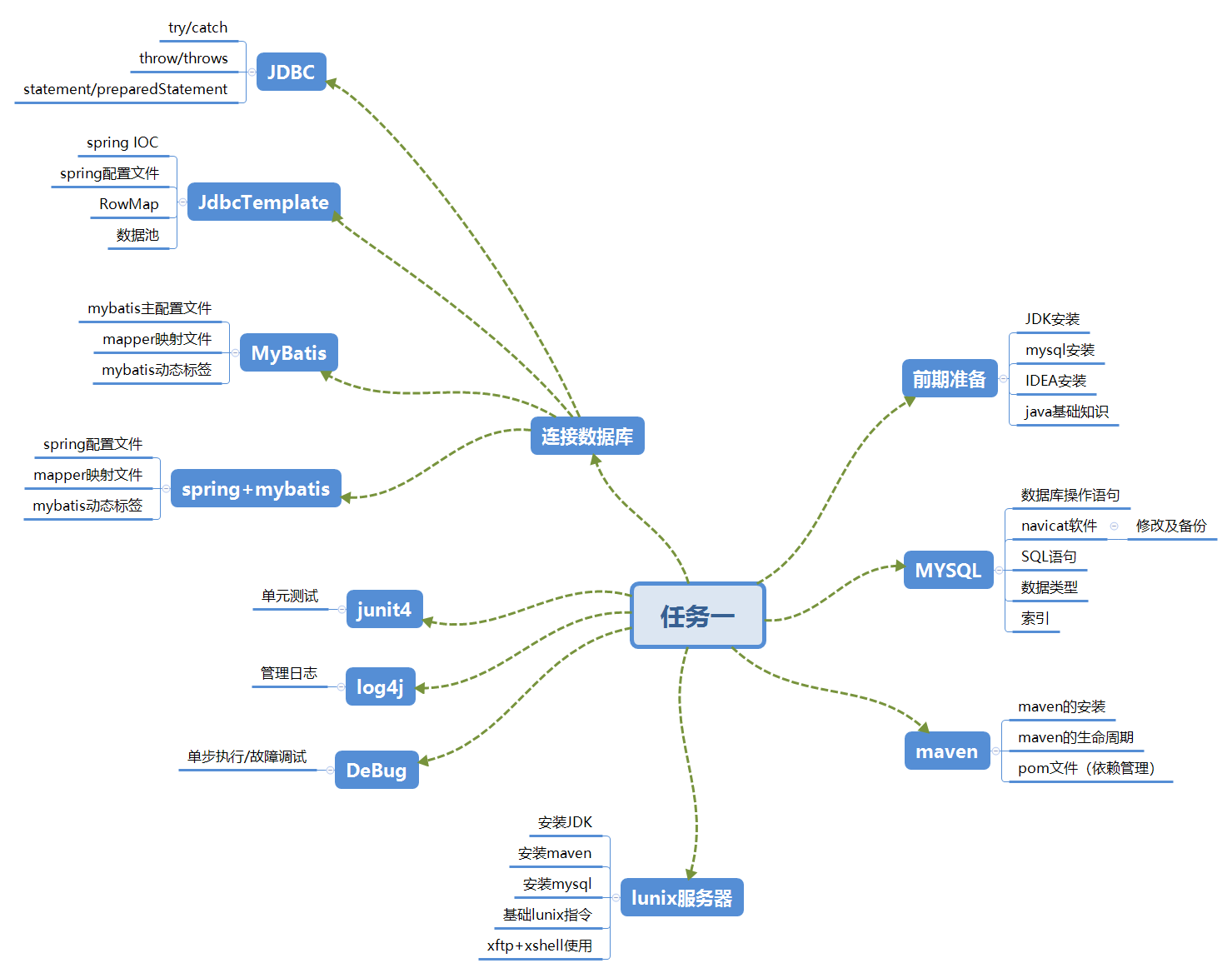
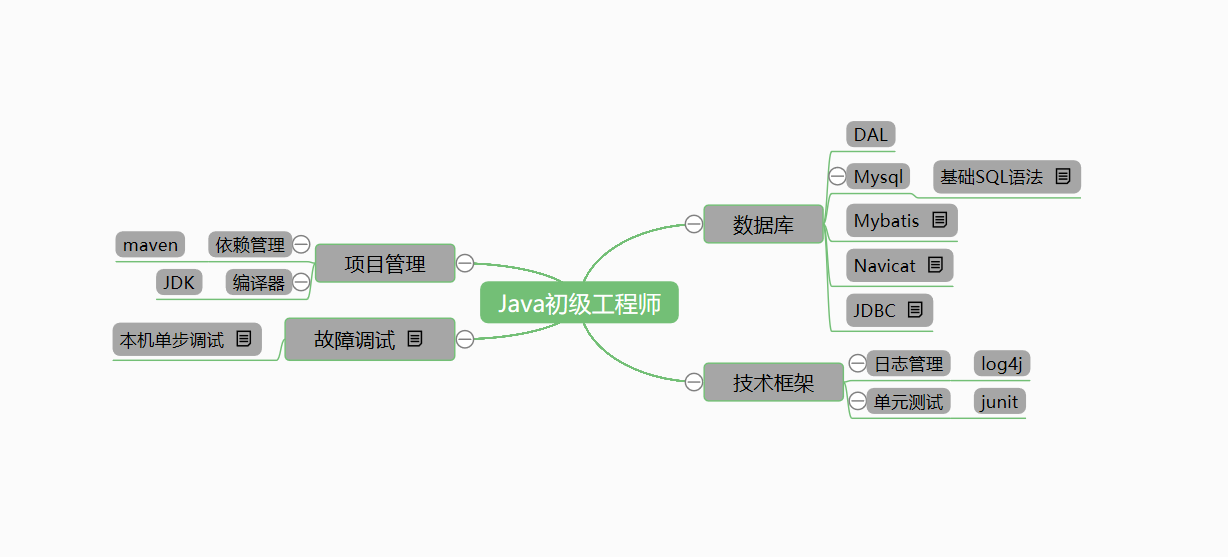
任务一的总结
自己的脑图
官方脑图
任务一算上试学共耗时32天,2019年10月11号开始试学——2019年11月13号。
一 任务进度是否符合预期,是否延期,如果延期,原因是什么,如何避免下次继续延期
不符合预期,延期了2天
原因
1. 基础差 需要边做任务边补充java基础知识 占据了一些时间
2. 后期学习状态有所下滑,效率低,也耽误了不少时间
————学不进去就调整调整状态,实在不行给自己放个假
3. 学习方式, 有时A不会了去看A A牵扯到B又去看B B牵扯C又去看C 结果都没怎么看懂 还浪费时间
———— 要有目的的去搜索知识点
4. 自己碰到问题 喜欢死磕 很少问师兄,与师兄的交流也较少 会耽误任务的进度。
——— 多和师兄交流 少死磕
二 脑图对比分析
在上方
三 任务中遇到哪些疑难问题,最终是如何解决的,有哪些值得分享的收获
刚开始学习的时候,推进到任务17后,很懵逼。 发现自己不会的好多,想推进任务,别人的代码根本就看不懂
整个人都快自闭了。
后面就是先补充些Java基础知识,比如java的方法/类/对象/接口等
然后从JDBC开始,JDBC还好一点,连接简单,不过每个都需要需要关闭操作。
到jdbctemplate mybatis 难度就起来了,要补充的知识很多:dao模式 /spring/mybatis.....。 还要写配置文件。
自己也是摸索了好久,结合师兄日报和一些博客,跟着写。并在配置文件里一行一行打注释,代码里打注释,慢慢完成的。
自己在学习spring和mybatis过程中 卡的也挺久
因为自己天天埋头百度,不怎么主动问师兄问题,有时就算不懂也不主动问,死磕,导致进度缓慢,
真正的改正这个习惯了。
现在即使任务做完了,感觉现在掌握的知识也很浅薄,涉及到得只会基础的使用,还需要不停的学习。
分享:
1.java的 数据类型/方法/参数/对象等知识一定要掌握 任务里各个文件的关系 都会牵扯到这些知识。
2. 网上的博客虽然很多,但筛选出对自己有用的还需要过程。
推荐去看师兄的日报,他们遇到的问题和收获都在里面,真的对我们任务推进很有用(个人是这样)
2.买云服务器别买错了 我就错买了阿里云的云数据库(MySQL) 直接买 云服务器 就好
我自己现在买的是腾讯云服务器,30元/3个月 价格还可以。
明天计划的事情:
任务一代码先提交下
让师兄看看有没有问题
提前看看任务2所需要的东西把


.png)






评论