发表于: 2019-11-11 23:26:46
1 959
今天完成的事情
晚上出去团建了 深度思考完毕了以下的内容 剩下的明天更新
1.Mybatis有哪些常用标签?怎么使用标签来完成动态查询?
.png)

目前常用的:
定义sql语句: select(属性有id parameterType传参类型 resultType结果类型)
insert delete update (属性只有id 和 paeameterType)
我们在任务中的增删查改中就用这个
java对象属性: resultMap
有三种情况会用到ResultMap:1、如果查询结果字段与po的字段名称不对应;2、查询结果的字段类型与po的字段类型不一致;3、查询结果对应多个po
控制动态sql拼接:if、foreach、choose
格式化输出:where、set、trim
- 如何完成动态查询
动态查询则需要使用动态标签,组成动态sql语句
if if 标签通常用于 WHERE 语句、UPDATE 语句、INSERT 语句中,通过判断参数值来决定是否使用某个查询条件、判断是否更新某一个字段、判断是否插入某个字段的值。
判断某个条件是否成立 ,如果成立 则返回
.png)

举例:如果uesrname不为空 返回此条件
where 如果它包含的标签有返回值 则插入一个where
如果标签的返回值为and 或 or 开头, 则剔除
常用方法 if+where 来剔除多个if 标签中易出现的 where and 语法错误
choose 这个很好理解 类似Java的switch语句 从头开始 哪个符合条件用哪个 否则就判断下一个
set 若它包含的标签若有返回值 就插入一个set
主要用于更新操作 因为更新语句里需要用set赋新值
trim trim标记是一个格式化的标记,可以完成set或者是where标记的功能
里面包含prefix:前缀 prefixoverride:去掉第一个and或者是or 可以替代if+where语句
里面包含suffix:后缀 suffixoverride:去掉最后一个逗号 可以替代if+set语句
foreach foreach 标签主要用于构建 in 条件,可在 sql 中对集合进行迭代。也常用到批量删除、添加等操作中。
虽然有概念摆在这里,但还是要多练习才能理解。
2.什么叫反射?反射的坏处是什么?有哪些反射的应用场景?
反射定义: JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属 性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
反射的坏处: 1.不安全,当我们使用反射时,其实是在动态的获取信息,暴露类和方法的内部, 那么对于被获取信息的一方来说,是不安全的。
2.反射需要以牺牲性能为代价
举例:
packagecn.com.ptteng;
classPerson {}
public class TestDemo {
publicstaticvoidmain(String[] args) throwsException {
Person per = newPerson() ; // 正着操作
System.out.println(per.getClass().getName()); // 反着来
}
}
3.什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
SVN: 开放源代码的版本控制系统
小乌龟: 用于简化操作SVN的软件
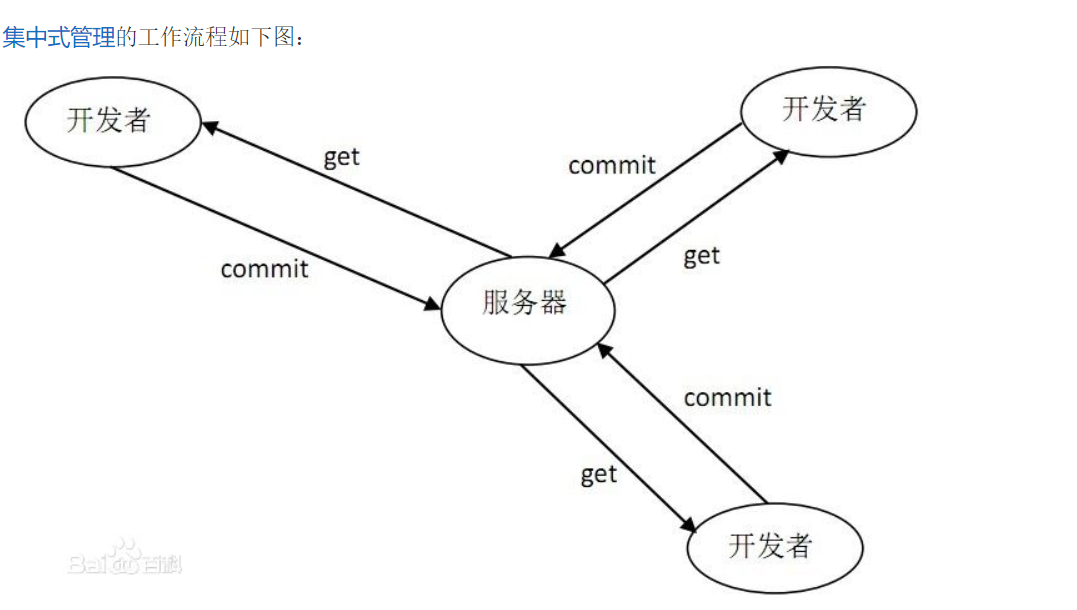
GIT:(分布式版本控制系统)
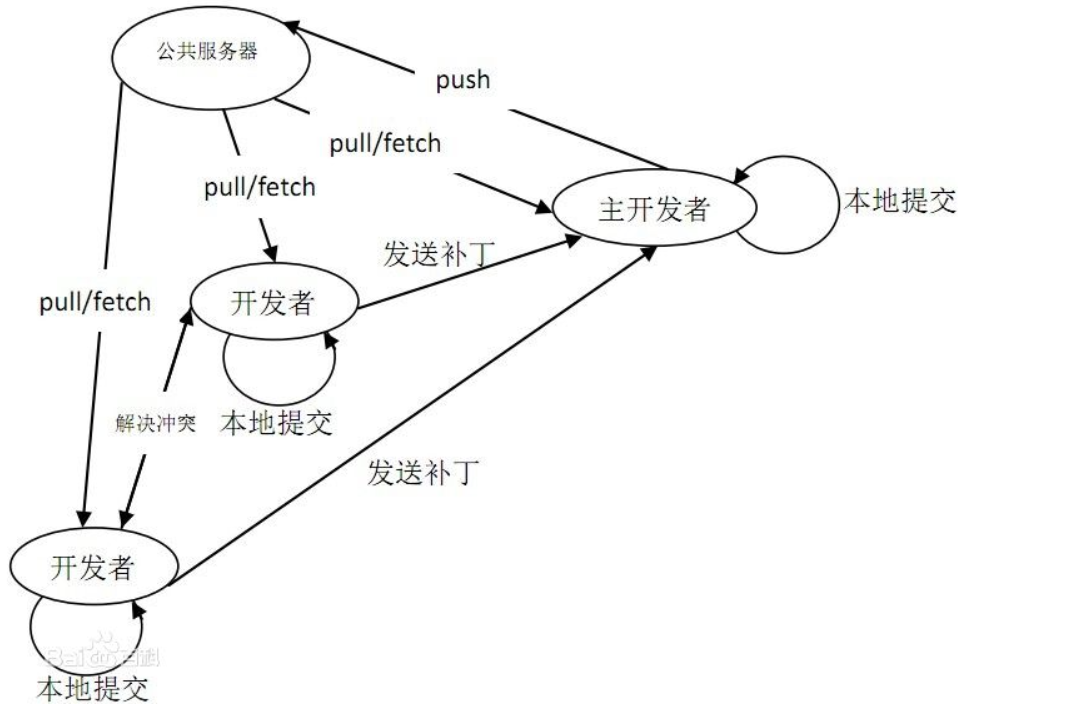
SVN 的优缺点
SVN对中文支持好,操作简单,使用没有难度,美工人员,产品人员,测试人员,实施人员都可轻松上手。使用界面统一,功能完善,操作方便。
Git的优缺点
对程序源代码进行差异化的版本管理,代码库占极少的空间。易于代码的分支化管理。不支持中文,图形界面支持差,使用难度大。不易推广。
适用场景
个人开发适合git 团队开发适合svn
参考:
4.什么是AOP,适用于哪些场景,AOP的实现方案有哪些?
AOP是spring下的一个功能
aop做了什么:
就是把 安全,事物,日志等,先定义好
然后通过注解的方法
放在目标类(targer)的 方法前(连接点) 方法后(连接点)等地方
减少重复的代码量
适用场景:
适用于出现大量提示及相同代码的场景,比如每个方法前需要输出一个信息 方法后输出一个信息
用aop即可减少代码量
实现方案:
首先,引入aop jar包
其次,xml文件里配置 aop
1.先创建一个类,比如:MyAspect.java
2.在类上使用 @Aspect 注解 使之成为切面类
3.在类上使用 @Component 注解 把切面类加入到IOC容器中,或者在spring配置文件中创建bean也可以,也可以在它上面加@Service注解,目的就是让它实例化
@Aspect注解方式来实现前置通知、返回通知、后置通知、异常通知、环绕通知!!!!!!!
5.Map,List,Array,Set之间的关系是什么,分别适用于哪些场景,集合大家族还有哪些常见的类?
array是 数组
map list set是集合
List:
1.可以允许重复的对象。
2.可以插入多个null元素。
3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
4.常用的实现类有 ArrayList、LinkedList 和 Vector
ArrayList 最为流行,它提供了使用索引的随意访问
而 LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适。
Set:
1.不允许重复对象
2. 无序容器,你无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序。
3. 只允许一个 null 元素
4.Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于 HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
Map:
1.Map不是collection的子接口或者实现类。Map是一个接口。
2.Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
3. TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
4. Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
5.Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
6.Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
两种 xml annonation
目前我们用的是xml
7.JDBCTemplate和JDBC
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
JDBCTemplate。相比JDBC,jdbcTemplate在名字上多了一个Template,而多的这个template,就是模板,是Spring框架为我们提供的,所以JDBCTemplate就是Spring对JDBC的封装,通俗点说就是Spring对jdbc的封装的模板。
8.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
9.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
一个实体类会将接口和实现方法混在一起,不易更改
interface和impl的好处是将数据层和数据层分开 方便解耦
10.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
11.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
12.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
为了缩小错误查看的范围。 一步一步查看变量的值变化,找到错误的原因。
13.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
14.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
15.为什么不可以用Select * from table?
Select * from table 是查询表的所有内容 影响效率
正常情况下我们只需要根据列名 来查找表的行信息
16.clean,install,package,deploy分别代表什么含义?
17.怎么样能让Maven跳过JUnit?
18.为什么要用Log4j来替代System.out.println?
因为system.out.println只能输出到控制台 每次输入内容都要自己定义
而log4j还可以输出日志文件,并且根据级别进行分类
19.为什么DB的设计中要使用Long来替换掉Date类型?
20.自增ID有什么坏处?什么样的场景下不使用自增ID?
坏处:不存在连续性,也就是说若表中存有3行数据,ID字段为1,2,3 那么当删除字段2时就变为1,3,不具有连续性合并表会出现ID重复的情况,上面说个使用自增ID能够在单个表中保证ID字段唯一,但两个表何为1个表,时不具有这种性质的。
不推荐使用的场景:正是因为自增ID的缺点也就是无法在多个表中,或者多个数据库中保持ID主键唯一不重复,所以若是使用分布式数据库以及数据合并的情况下时不能使用自增ID的。需要频繁操作的表也不推荐使用
21.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
22.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
23.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要,插入数据的时候会判断是否重复,如果有重复会报错数据库会帮我们去判断的.
24.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
25.修真类型应该是直接存储Varchar,还是应该存储int?
varchar 因为int是整数型,存储数字 而修真类型为字符型
26.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
27.怎么进行分页数据的查询,如何判断是否有下一页?
28.maven是什么,和Ant有什么区别?




评论