发表于: 2019-11-11 17:55:09
0 869
一、Token的起源与发展
在计算机身份认证中是令牌(临时)的意思,在词法分析中是标记的意思。一般作为邀请、登录系统使用。
发展史
1、很久很久以前,Web 基本上就是文档的浏览而已, 既然是浏览,作为服务器, 不需要记录谁在某一段时间里都浏览了什么文档,每次请求都是一个新的HTTP协议, 就是请求加响应, 尤其是我不用记住是谁刚刚发了HTTP请求, 每个请求对我来说都是全新的。这段时间很嗨皮
2、但是随着交互式Web应用的兴起,像在线购物网站,需要登录的网站等等,马上就面临一个问题,那就是要管理会话,必须记住哪些人登录系统, 哪些人往自己的购物车中放商品, 也就是说我必须把每个人区分开,这就是一个不小的挑战,因为HTTP请求是无状态的,所以想出的办法就是给大家发一个会话标识(session id), 说白了就是一个随机的字串,每个人收到的都不一样, 每次大家向我发起HTTP请求的时候,把这个字符串给一并捎过来, 这样我就能区分开谁是谁了
3、这样大家很嗨皮了,可是服务器就不嗨皮了,每个人只需要保存自己的session id,而服务器要保存所有人的session id ! 如果访问服务器多了, 就得由成千上万,甚至几十万个。
这对服务器说是一个巨大的开销 , 严重的限制了服务器扩展能力, 比如说我用两个机器组成了一个集群, 小F通过机器A登录了系统, 那session id会保存在机器A上, 假设小F的下一次请求被转发到机器B怎么办? 机器B可没有小F的 session id啊。
有时候会采用一点小伎俩: session sticky , 就是让小F的请求一直粘连在机器A上, 但是这也不管用, 要是机器A挂掉了, 还得转到机器B去。
那只好做session 的复制了, 把session id 在两个机器之间搬来搬去, 快累死了。
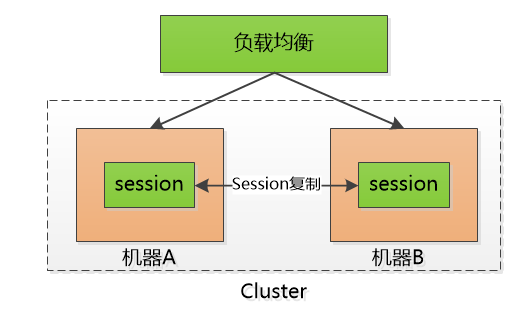
后来有个叫Memcached的支了招: 把session id 集中存储到一个地方, 所有的机器都来访问这个地方的数据, 这样一来,就不用复制了, 但是增加了单点失败的可能性, 要是那个负责session 的机器挂了, 所有人都得重新登录一遍, 估计得被人骂死。
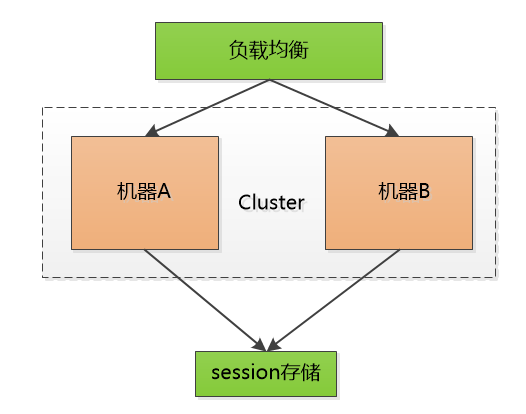
也尝试把这个单点的机器也搞出集群,增加可靠性, 但不管如何, 这小小的session 是一个沉重的负担
4 于是有人就一直在思考, 我为什么要保存这可恶的session呢, 只让每个客户端去保存该多好?
可是如果不保存这些session id , 怎么验证客户端发给我的session id 的确是我生成的呢? 如果不去验证,我们都不知道他们是不是合法登录的用户, 那些不怀好意的家伙们就可以伪造session id , 为所欲为了。
嗯,对了,关键点就是验证 !
比如说, 小F已经登录了系统, 我给他发一个令牌(token), 里边包含了小F的 user id, 下一次小F 再次通过Http 请求访问我的时候, 把这个token 通过Http header 带过来不就可以了。
不过这和session id没有本质区别啊, 任何人都可以可以伪造, 所以我得想点儿办法, 让别人伪造不了。
那就对数据做一个签名吧, 比如说我用HMAC-SHA256 算法,加上一个只有我才知道的密钥, 对数据做一个签名, 把这个签名和数据一起作为token , 由于密钥别人不知道, 就无法伪造token了。
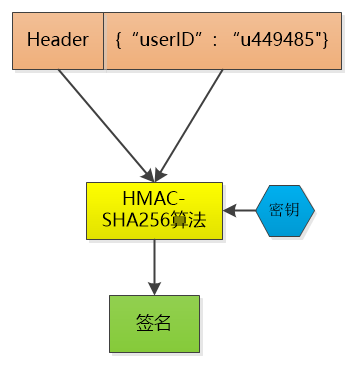
这个token 我不保存, 当小F把这个token 给我发过来的时候,我再用同样的HMAC-SHA256 算法和同样的密钥,对数据再计算一次签名, 和token 中的签名做个比较, 如果相同, 我就知道小F已经登录过了,并且可以直接取到小F的user id , 如果不相同, 数据部分肯定被人篡改过, 我就告诉发送者: 对不起,没有认证。
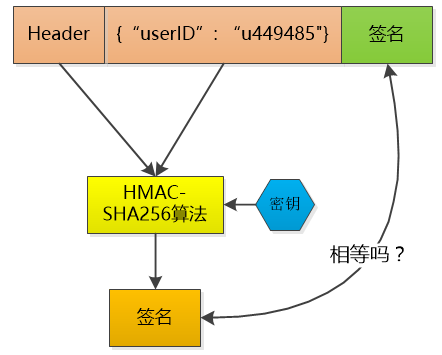
Token 中的数据是明文保存的(虽然我会用Base64做下编码, 但那不是加密), 还是可以被别人看到的, 所以我不能在其中保存像密码这样的敏感信息。
当然, 如果一个人的token 被别人偷走了, 那我也没办法, 我也会认为小偷就是合法用户, 这其实和一个人的session id 被别人偷走是一样的。
这样一来, 我就不保存session id 了, 我只是生成token , 然后验证token , 我用我的CPU计算时间获取了我的session 存储空间 !
解除了session id这个负担, 可以说是无事一身轻, 我的机器集群现在可以轻松地做水平扩展, 用户访问量增大, 直接加机器就行。 这种无状态的感觉实在是太好了!
二、session和cookie
Session
session 从字面上讲,就是会话。这个就类似于你和一个人交谈,你怎么知道当前和你交谈的是张三而不是李四呢?对方肯定有某种特征(长相等)表明他就是张三。
session 也是类似的道理,服务器要知道当前发请求给自己的是谁。为了做这种区分,服务器就要给每个客户端分配不同的“身份标识”,然后客户端每次向服务器发请求的时候,都带上这个“身份标识”,服务器就知道这个请求来自于谁了。至于客户端怎么保存这个“身份标识”,可以有很多种方式,对于浏览器客户端,大家都默认采用 cookie 的方式。
服务器使用session把用户的信息临时保存在了服务器上,用户离开网站后session会被销毁。这种用户信息存储方式相对cookie来说更安全,可是session有一个缺陷:如果web服务器做了负载均衡,那么下一个操作请求到了另一台服务器的时候session会丢失。
Cookie
cookie 是一个非常具体的东西,指的就是浏览器里面能永久存储的一种数据,仅仅是浏览器实现的一种数据存储功能。
cookie由服务器生成,发送给浏览器,浏览器把cookie以kv形式保存到某个目录下的文本文件内,下一次请求同一网站时会把该cookie发送给服务器。由于cookie是存在客户端上的,所以浏览器加入了一些限制确保cookie不会被恶意使用,同时不会占据太多磁盘空间,所以每个域的cookie数量是有限的。
Token
在Web领域基于Token的身份验证随处可见。在大多数使用Web API的互联网公司中,tokens 是多用户下处理认证的最佳方式。
三、cookie VS token
工作流程
cookie(Cookie渐渐被淘汰。)
cookie 登录是有状态的,服务端维护一个 session 客户端维护一个 cookie,cookie 只保留 sessionID 服务端要保存并跟踪所有活动的 session 如下:
- 1.输入用户名密码登陆。
- 2.服务器拿到身份并验证后生成一个 session 存到数据库。
- 3.把 sessionID 返回给客户端存成一个 cookie 保存在用户浏览器。
- 4.随后的请求会携带这个包含 sessionID 的 cookie。
- 5.服务器拿着 sessionID 找到对应的 session 认证用户是否有对应权限。
6.登出后,服务端销毁 session 客户端销毁 cookie。
token
token 的认证方式是无状态的,服务端不保存登陆状态,也不关心哪些客户端签发了 token ,每个请求都会携带 token 通常在 header 中,也可以出现在 body 和 query 如下:- 1.通过输入用户名密码登陆发送请求。
- 2.服务器拿到身份并验证后签发一个经过签名的 token。
- 3.客户端拿到 token 并存起来,好多地方都可以存(可以存在localstorage,或者cookie中)。
- 4.客户端发送的每一个请求都要携带 token(每次访问API是携带Token到服务器端),好多方式可以携带。
- 5.服务器接收请求后拿到 token 并解析,拿解析的结果进行权限认证(token中可能已经携带权限信息,能被正常解析的 token 被认为是合法机构签发的)。
6.登出后,在客户端销毁 token 即可。
每一次请求都需要token。token应该在HTTP的头部发送从而保证了Http请求无状态。我们同样通过设置服务器属性Access-Control-Allow-Origin:* ,让服务器能接受到来自所有域的请求。需要主要的是,在ACAO头部标明(designating)*时,不得带有像HTTP认证,客户端SSL证书和cookies的证书。
特性对比
cookie
用户登录成功后,会在服务器存一个session,同时发送给客户端一个cookie
数据需要客户端和服务器同时存储
用户进行操作时,需要带上cookie,在服务器进行验证
cookie是有状态的
token
用户进行任何操作时,都需要带上一个token
token的携带形式有很多种,header/requestbody/url 都可以
这个token只需要存在客户端,服务器在收到数据后,进行解析
token是无状态的
token 的优势
- 无状态,token 是无状态的,服务器端不需要保留任何信息,每个 token 都会包含所有需要的用户信息。服务器端可以只负责签发和解析 token 解放了部分服务器资源,让服务器更单纯的提供接口。
- 跨服务器,无状态优势在此。Token 完全由应用管理,服务器如果做了负载均衡之类的,你两条请求不一定去同一个服务器,着如果用服务器维护一个 session 的话就显得有些棘手了,一个服务器和一个客户端对应,另一个服务器不一定认得你啊,不对是一定不认得你啊,当然这个问题也不难解决。
- 可携带其他信息,比如携带具体权限信息之类的,省的还要去查库。
- 高性能,解 token 可比查库要省事儿的多。
- 可跨域,请求需要跨域的接口的时候 cookie 就力不从心了,不同域就不会携带 cookie ,不携带 cookie 服务器也不知道是哪个 session 啊,token 在此优势明显。
- 配合移动端,cookie 是浏览器端的玩意儿,移动端应用想使用 cookie 还得折腾一下,token 就方便得多。token 让服务器端单纯提供 API 服务,适用性更广。
- 防止CSRF(跨站请求伪造),如果 token 不存放在 cookie 中,防止了跨站请求伪造带来的安全性风险。
那些使用基于Token的身份验证的大佬们
大部分你见到过的API和Web应用都使用tokens。例如Facebook, Twitter, Google+, GitHub等。
四、页面间传参
五、使用require.context实现前端工程自动化
require.context 是什么
什么时候需要用到 require.context
require.context
require.context函数接受三个参数
directory {String} -读取文件的路径
useSubdirectories {Boolean} -是否遍历文件的子目录
regExp {RegExp} -匹配文件的正则
语法: require.context(directory, useSubdirectories = false, regExp = /^.//);
例:
这里把require.context函数执行后的代码赋值给了files变量,files中保存了以.js结尾的文件,files是个函数,
上面的代码遍历当前目录文件夹的所有.js结尾的文件,不遍历子目录
require.context函数执行后返回的是一个函数,并且这个函数有3个属性
resolve {Function} - 返回这个匹配文件相对于整个工程的相对路径
resolve方法是一个函数可以接受req参数,这个req参数的值是keys方法返回的数组的元素,
传入其中一个元素执行resolve函数:

resolve方法返回了代表着传入参数的文件相对于整个工程的相对路径的字符串
keys {Function} -返回由匹配文件的文件名组成的数组
id {String} - 返回的是组合(匹配的文件夹的相对于工程的相对路径、是否遍历子目录、匹配正则)的字符串
files 作为一个函数,也接受一个req参数,即匹配的文件名的相对路径,返回的是一个模块,这个模块才是真正我们需要的

使用 require.context 自动导入路由文件
在
1、首先调用require.context导入某个文件夹的所有匹配文件,返回执行上下文的环境赋值给files变量
2、声明一个configRouters用来暴露给外层index.js作为vue-router的数组
3、调用files函数的keys方法返回modules文件夹下所有以.js结尾的文件的文件名,返回文件名组成的数组
4、遍历数组每一项,如果是index.js就跳过(index.js并不是路由模块),调用files函数传入遍历的元素返回一个Modules模块
5、因为webpack是根据你文件夹中文件的位置排序的,这个时候需要定义一个标识符来给路由数组排序,这里我们给每个文件夹最上层的路由添加一个sort属性用于排序
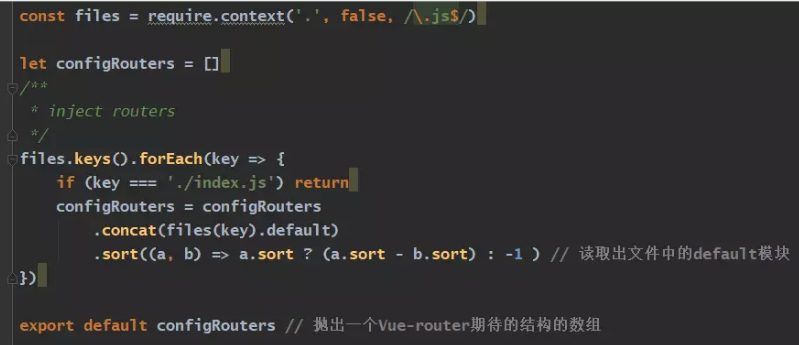
6、因为我的路径是用export default导出的,所以在Module模块的default属性中获取到我导出的内容(即路由的结构),类似这种样子
- import Vue from 'vue'import router from 'vue-router'import routes from './modules/pages'import children from './modules/tabbar'import components from './modules/components'// navFoot.vue (底部导航)Vue.use(router)// Supports both of Vue 1.0 and Vue 2.0Object.keys(components).forEach(item => {Vue.component(item, components[item]);})export default new router({routes: [...routes,{path: '/',component: () => import('@/components/tabbar'),children},]})
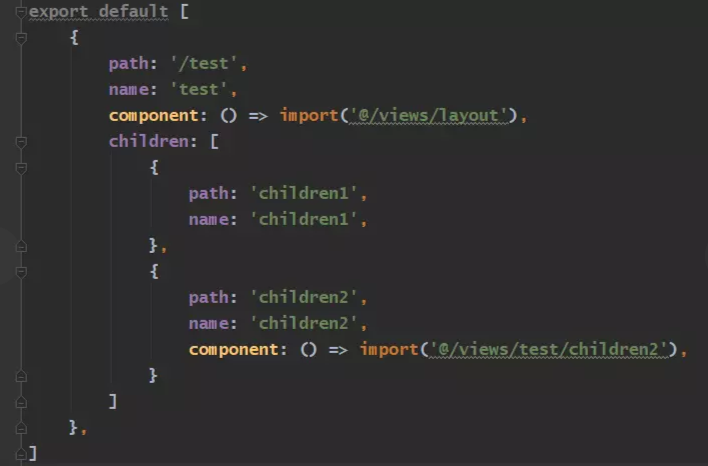
7、将上一步返回的所有路由结构添加到configRouters数组然后暴露给外层的index.js

8、外层引入后导入到vue-router中就可以使用了




评论