发表于: 2019-11-10 23:44:29
0 1216
今日完成的事
今天继续学习了正则
所谓正则就是一个规则,用来处理字符串的规则,正则只能用来处理字符串,处理一般包含2个方面,1验证当前字符串是不是符合某个规则(正则的匹配),2把一个字符串中符合规则的字符串获取到(正则的捕获),学习正则就是学习如何编写规则。
正则的匹配方法test和exec
每一个正则都是由元字符和修饰符2部分组成
创建正则的两种方式
1. 字面量方式例如let reg1=/xxx/g
2. 构造函数方式 let reg2 = new RegExp(xxx,g)
正则的两种创建方式是有区别的,如果我们想把一个变量加入到正则中那么字面量的创建方式就不行了,必须用构造函数的方法

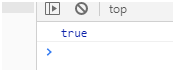

这里注意因为默认\d是字符串,不能识别为正则所以需要转义再加一个\。
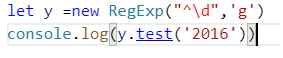

字面量方式和实例创建的方式区别,字面量方式中出现的一切都是元字符,所以不能进行变量值的拼接,而实例创建的方式可以,字面量方式中直接写\d就可以,在实例中需要转义。
正则元字符和修饰符:每一个正则表达式都是由元字符和修饰符组成的,
2个斜杠包起来的具有意义的字符都是元字符,两个斜杠以外的都是修饰符。
普通元字符
只要在正则中出现的元字符(基于字面量创建),除了特殊和有量词意义的以外,其余都是普通元字符
常用元字符
1.\ :转义字符:把它后面字符所代表的含义。
2.^:以某一个元字符开始,在字符串中是没有位置的。
3.$:以某一个元字符结尾,在字符串中是没有位置的。
4. . :出来\n以外的任意字符
5. \n匹配一个换行符
6.x|y:x或者y中的一个
7[xyz]:x或者y或者z中的一个
8[^]:非,如[^xyz]除了xyz中的任何一个字符
9[a-z]:a-z之间的任何一个字符
10:\d一个0-9之间的数字
11:\D:除了0-9之间的数字以外的任何字符
12:\b:匹配一个边界符
13:\w:数字字母下划线中的任意字符
14:\s:匹配一个空白字符 空格 一个制表符 换页符
量词元字符
*出现零到多次
?出现零到一次
{n}出现n次
{n,}出现n到多次
{n,m}出现n到m次。
+:出现1到多次
特殊元字符【】
中括号的一些细节,例如[xyz] [^xyz] [a-z] [^a-z]
1. 中括号中出现的元字符一般都是代表本身含义的。
2. 中括号里面出现的两位数并不是两位数而是2个数字中的任意一个.比如
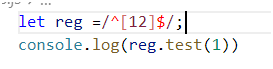
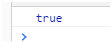
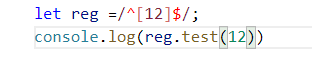
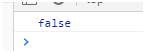
let reg =/^[12-89]$/;这个正则代表是1或者2-8或者9都可以
特殊元字符()
小括号具有分组的作用,把一个大正则划分成几个小的正则
比如let reg =/^18|19$/;这个正则就是代表以18开头,或者以19结尾,或者以1开头以9结束中间的数为8或者1,这会显得特别乱,所以如果只想要以18开头,以19结尾的效果要加一个小括号let reg =/^(18|19)$/;这样18|19就代表一个整体了。
正则的分组引用
例如let reg =/^([a-z])([a-z])\2\1$/;
正则中出现\1代表和第一个分组出现一模一样的内容

正则修饰符i,m,g
g:全局匹配
i:忽略大小写匹配
m:多行匹配
常用的正则表达式写法
1. 有效数字
/^[+-]?(\d|([1-9]\d+))(\.\d+)?$/;
只有负数的且没有-0
/^(-?([1-9]|([1-9]\d+))(\.\d+)?|0(\.\d+)?)$/
2. 手机号
/^1\d{10}$/
3. 中文汉字
[\u4E00-\u9FA5]
4. 中文姓名
/^[\u4E00-\u9FA5]+$/
5. 邮箱
/^\w+([-.]\w+)*@[a-zA-Z0-9]+([-.][A-Za-z0-9]+)*(\.[a-zA-Z0-9]+)$/;
6. 年龄18-65
/(1[8-9])|([2-5]\d)|(6[0-5])/
正则的捕获:把一个字符串当中和正则匹配的部分获取到
基于exec捕获如果当前正则和字符串不匹配,则捕获的结果为null
如果匹配则返回来一个数组
0:位正则捕获的内容
Index:正则捕获的起始索引
Input:原始操作的字符串
执行一次exec只能捕获到第一个和正则匹配的内容,其余匹配的内容还没有捕获到,而且执行多次也没什么卵用,这是因为正则的捕获具有懒惰性(每一次执行exec只捕获第一个匹配的内容,在不进行任何处理的情况下,在执行多次捕获,捕获的还是第一个匹配的内容)。如何解决懒惰性在正则的末尾加一个修饰符g,加了全局修饰符g每一次正则捕获结束后我们的lastindex的值就会变为最新的值,下一次捕获会从最新的位置开始查找,这样就可以把所有需要捕获的诶荣都获取到了。
正则每次捕获都会按照最长的结果捕获的,这个特性叫做正则的贪婪性。
如何解决正则的贪婪性,在量词元字符加一个问号即可
在正则捕获的时候,如果正则中存在分组,捕获的时候不仅仅把大正则匹配的字符捕获到,还会把分组的内容捕获到,这就是分组捕获。


阻止分组捕获用的是问号和冒号


Match方法虽然可以捕获所有相关的字符串,但是不能分组捕获了,而且用match时正则必须加g不然跟exec方法一样了


正则捕获有一个很恶心的地方,如果用同一个正则捕获不同的字符串,那么这个正则会在捕获完第一个字符串之后捕获第二字符串的时候会从第一个字符串的索引值处开始捕获
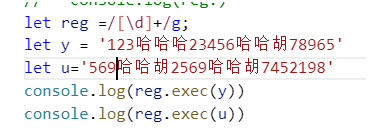

我们发现在捕获第二个字符串的时候并没有从569开始而是重2569开始,虽然捕获的不是同一个字符串但是正则是同一个,上一次正则处理的时候修改了它的LAST-TNDEX,也会对下一次匹配新的字符串产生影响。
明天计划的事
继续学习angular和正则
遇到的困难
对正则还是不熟悉
收获
了解了正则的贪婪性和懒惰性




评论