发表于: 2019-11-08 23:15:37
0 1079
今日完成的事
今天学习了正则表达式
所谓正则就是一个规则,用来处理字符串的规则,正则只能用来处理字符串,处理一般包含2个方面,1验证当前字符串是不是符合某个规则(正则的匹配),2把一个字符串中符合规则的字符串获取到(正则的捕获),学习正则就是学习如何编写规则。
正则的匹配方法test和exec
每一个正则都是由元字符和修饰符2部分组成
创建正则的两种方式
1. 字面量方式例如let reg1=/xxx/g
2. 构造函数方式 let reg2 = new RegExp(xxx,g)
正则元字符和修饰符:2个斜杠包起来的都是元字符,两个斜杠以外的都是修饰符
量词元字符
*出现零到多次
?出现零到一次
{n}出现n次
{n,}出现n到多次
{n,m}出现n到m次。
普通元字符
只要在正则中出现的元字符(基于字面量创建),除了特殊和有量词意义的以外,其余都是普通元字符
特殊元字符【】
中括号的一些细节,例如[xyz] [^xyz] [a-z] [^a-z]
1. 中括号中出现的元字符一般都是代表本身含义的。
2. 中括号里面出现的两位数并不是两位数而是2个数字中的任意一个.比如
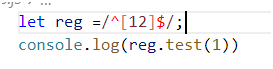
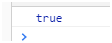
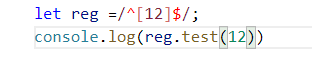
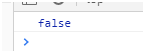
let reg =/^[12-89]$/;这个正则代表是1或者2-8或者9都可以
特殊元字符()
小括号具有分组的作用
比如let reg =/^18|19$/;这个正则就是代表以18开头,或者以19结尾,或者以1开头以9结束中间的数为8或者1,这会显得特别乱,所以如果只想要以18开头,以19结尾的效果要加一个小括号let reg =/^(18|19)$/;这样18|19就代表一个整体了。
正则的分组引用
例如let reg =/^([a-z])([a-z])\2\1$/;
正则中出现\1代表和第一个分组出现一模一样的内容

常用的正则表达式写法
1. 有效数字
/^[+-]?(\d|([1-9]\d+))(\.\d+)?$/;
2. 手机号
/^1\d{10}$/
3. 中文汉字
[\u4E00-\u9FA5]
4. 中文姓名
/^[\u4E00-\u9FA5]+$/
5. 邮箱
/^\w+([-.]\w+)*@[a-zA-Z0-9]+([-.][A-Za-z0-9]+)*(\.[a-zA-Z0-9]+)$/;
6. 年龄18-65
/(1[8-9])|([2-5]\d)|(6[0-5])/
正则的捕获:把一个字符串当中和正则匹配的部分获取到
基于exec捕获如果当前正则和字符串不匹配,则捕获的结果为null
如果匹配则返回来一个数组
0:位正则捕获的内容
Index:正则捕获的起始索引
Input:原始操作的字符串
明天计划的事
继续学习正则表达式
遇到的问题
刚学正则,还有很多不懂得地方
收获
初步了解了正则表达式




评论