发表于: 2019-11-03 17:43:52
3 806
啥也不说就是干!!!
今天完成的事情:
1、重构插入 百万数据
由于之前插入数据耗时太久,师兄说方式不对,参考之前师兄的日志:
进行Mybatis 批量插入的方案。更换 Datasource 由于之前使用 c3p0 数据源,现在改为 阿里 Druid 数据源
Druid 相对于其他数据库连接池的优点:
1.强大的监控特性,通过Druid提供的监控功能,可以清楚知道连接池和SQL的工作情况。
a. 监控SQL的执行时间、ResultSet持有时间、返回行数、更新行数、错误次数、错误堆栈信息;
b. SQL执行的耗时区间分布。什么是耗时区间分布呢?比如说,某个SQL执行了1000次,其中0~1毫秒区间50次,1~10毫秒800次,10~100毫秒100 次,100~1000毫秒30次,1~10秒15次,10秒以上5次。通过耗时区间分布,能够非常清楚知道SQL的执行耗时情况
c. 监控连接池的物理连接创建和销毁次数、逻辑连接的申请和关闭次数、非空等待次数、PSCache命中率等。
2.其次,方便扩展。Druid提供了Filter-Chain模式的扩展API,可以自己编写Filter拦截JDBC中的任何方法,可以在上面做任何事情,比如说性能监控、SQL审计、用户名密码加密、日志等等。
3.Druid集合了开源和商业数据库连接池的优秀特性,并结合阿里巴巴大规模苛刻生产环境的使用经验进行优化
Spring 更换 Druid 数据源:
添加依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.29</version>
</dependency>
定义 Druid Datasource实例
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
<!-- 数据库基本信息配置 -->
<property name="url" value="${druid.url}" />
<property name="username" value="${druid.username}" />
<property name="password" value="${druid.password}" />
<property name = "driverClassName" value = "${druid.driverClassName}" />
<!-- 初始化连接数量 -->
<property name="initialSize" value="${druid.initialSize}" />
<!-- 最小空闲连接数 -->
<property name="minIdle" value="${druid.minIdle}" />
<!-- 最大并发连接数 -->
<property name="maxActive" value="${druid.maxActive}" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="${druid.maxWait}" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="${druid.timeBetweenEvictionRunsMillis}" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="${druid.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="${druid.validationQuery}" />
<property name="testWhileIdle" value="${druid.testWhileIdle}" />
<property name="testOnBorrow" value="${druid.testOnBorrow}" />
<property name="testOnReturn" value="${druid.testOnReturn}" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 如果用Oracle,则把poolPreparedStatements配置为true,mysql可以配置为false。 -->
<property name="poolPreparedStatements" value="${druid.poolPreparedStatements}" />
<property name="maxPoolPreparedStatementPerConnectionSize"
value="${druid.maxPoolPreparedStatementPerConnectionSize}" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="${druid.filters}" />
</bean>
Druid Dababase 配置文件
druid.driverClassName=com.mysql.cj.jdbc.Driver
druid.url=jdbc:mysql://localhost:3306/jnshu?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT
druid.username=root
druid.password=zhou1990
druid.initialSize=10
druid.minIdle=6
druid.maxActive=50
druid.maxWait=60000
druid.timeBetweenEvictionRunsMillis=60000
druid.minEvictableIdleTimeMillis=300000
druid.validationQuery=SELECT 'x'
druid.testWhileIdle=true
druid.testOnBorrow=false
druid.testOnReturn=false
druid.poolPreparedStatements=false
druid.maxPoolPreparedStatementPerConnectionSize=20
druid.filters=wall,stat
修改测试方法:
添加 Mybatis 批量插入方法:
@Repository
public interface StudentMapper {List<Student> queryStudentById(long id);
//省略部分代码
int insertStudentInfos(@Param("stuInfos") List<Student> stuInfos);
}
添加 StudentMapper 的批量插入
<insert id="insertStudentInfos" parameterType="java.util.List">
INSERT INTO student(name,qq,jnshu_type,join_time,school,online_num,daily_url,slogan,counsellor,known_path)
VALUES
<foreach collection="stuInfos" index="index" item="item" separator=",">
(#{item.name},#{item.qq},#{item.jnshuType},#{item.joinTime},#{item.school},#{item.onlineNum},#{item.dailyUrl},#{item.slogan},#{item.counsellor},#{item.knownPath})
</foreach>
</insert>
遍历传入的 List 执行插入,更改测试方法:
private void insert300w() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(1000);
//声明等待锁
final CountDownLatch latch = new CountDownLatch(1);
executorService.execute(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
for (int i = 0; i < 30; i++) {
final List<Student> studentInfos = new ArrayList<>();
for(int j=0;j<100000;j++) {
Student student = new Student();
student.setName("高世豪" + j);
student.setJnshuType("JavaWeb");
student.setOnlineNum("007");
student.setDailyUrl("http://www/test.com");
student.setCounsellor("令狐冲");
synchronized (student){
studentInfos.add(student);
}
}
try {
studentService.insertInfos(studentInfos);
} catch (Exception e) {
e.printStackTrace();
}
latch.countDown();
long end = System.currentTimeMillis();
logger.debug("插入 300 万条数据耗时:" + (end - start));
}
});
//开始等待,主线程挂起
latch.await();
}
循环 30次,每次 Mybatis 插入 10w 条数据
 差不多耗时 3.8 分钟左右,比之前效率大大提高。应该还有优化的空间(等以后再考虑更优的方案)
差不多耗时 3.8 分钟左右,比之前效率大大提高。应该还有优化的空间(等以后再考虑更优的方案)
2、关于索引的知识:
索引类似于书的目录,可以提高数据检索的效率,降低数据库的 IO 成本,同时索引会占据磁盘空间,降低更新表的效率,每次对表进行增删改查操作,MySQL 不仅要保存数据,还要保存或者更新对应的索引文件
单列索引
普通索引:MySQL 中基本素银类型,没有限制,允许定义索引的列中插入重复值和空值,纯粹为了查询数据更快
唯一索引:索引列中的值必须是唯一的,但允许为空值
主键索引:一种特殊的唯一索引,不允许有空值
组合索引:在表中的多个字段组合上创建的索引
只有在查询条件中使用了这些字段的左边字段时候,索引才会被使用,遵循最左匹配原则
一般情况下,建议使用组合索引代替单列索引
索引的存储结构:索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
MyISAM 和 InnoDB 存储引擎:只支持 BTREE 索引,也就是说默认使用 BTREE,不能够更换
B树是为了磁盘或其他存储设备而设计的一种多叉平衡查找树(相对于二叉,B树每个内结点有多个分支,即多叉)
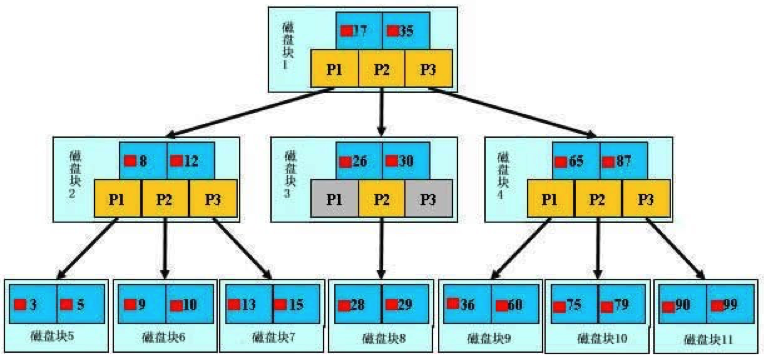
B树的高度一般都在 2-4 这个高度,树的高度直接影响 IO 读写的次数,如果三层结构可存储数据达 20G,四层大约可以达到几十 T
B树 和 B+树 的区别:
BTree 和 B+Tree 的最大区别在于非叶子节点是否存储数据
BTree 是非叶子节点和叶子节点都会存储数据,而 B+Tree 只有在叶子节点才会存储数据,而且存储的数据都在一行上,这些数据都是有指针指向的,也就是有顺序的
每创建一个索引都会创建一个树
非聚簇索引(MyISAM)
叶子节点只会存储数据行(数据文件中)的指针,简单来说数据和索引不在一起,就是非聚簇索引。主键索引和辅助索引都会存储指针的值
主键索引:
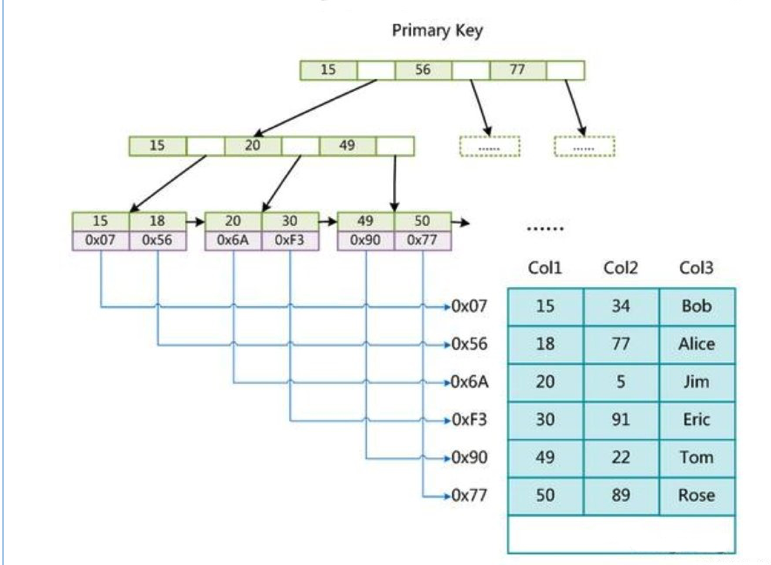
这里假设表一共有三列,以 Col1 为主键,则上图是一个 MyISAM 标的主索引(Primary key)示意。可以看出 MyISAM 的索引文件仅仅保存数据记录的地址。
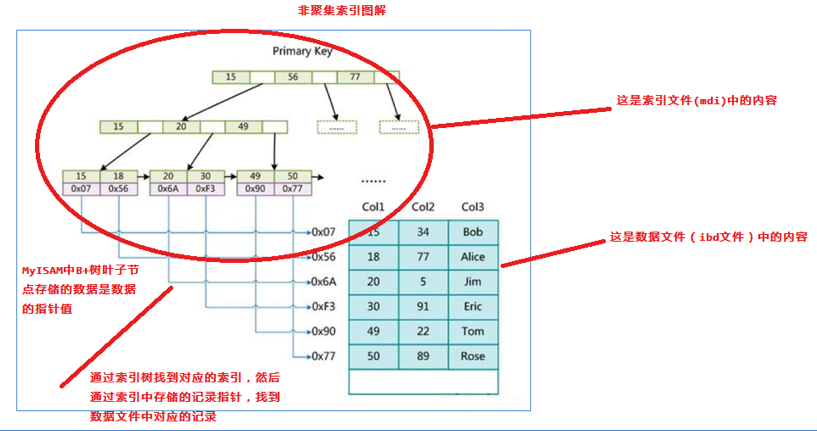
辅助索引(次要索引)
在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。如果我们在 Col2 上建立一个辅助索引,则此索引的结构如下图所示: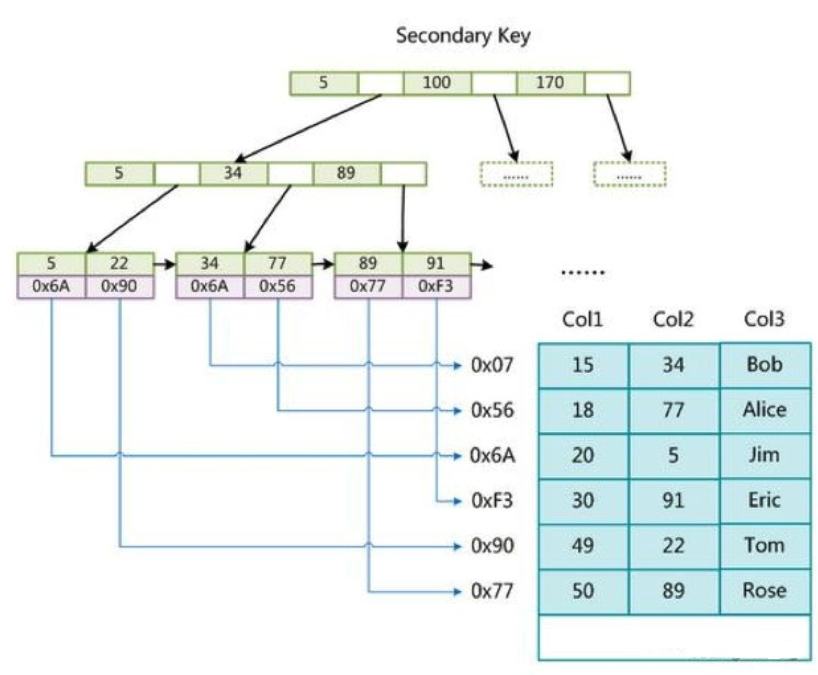
data 域保存数据记录的地址。首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出 data 域的值,然后以 data 域的值为地址,读取相应数据记录
聚簇索引(InnoDB)
主键索引(聚集索引)的叶子节点会存储数据行,也就是说数据和索引是在一起,这就是聚簇索引,辅助索引只会存储主键值,如果没有主键值,则使用唯一索引建立聚集索引,如果没有唯一索引,MySQL 会按照一定规则创建聚集索引
辅助索引只会存储主键值,如果没有主键,则使用唯一索引建立聚集索引,如果没有唯一索引,MySQL 会按照一定规则出啊建聚集索引。
主键索引
InnoDB 要求表必须有主键(MyISAM可以没有),如果没有显示指定,则 MySQL 系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则 MySQL 自动 InnoDB 表生成一个隐含字段作为主键,类型为长整形。
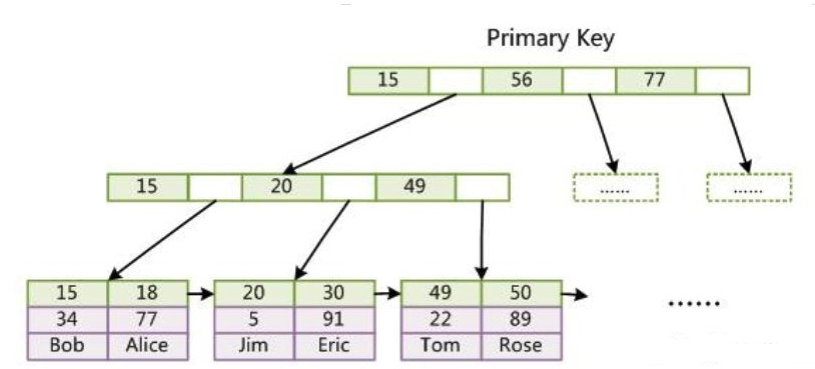
上图为 InooDB 主索引(同时也是数据文件)的示意图,可以看到也自己点包含了完整的数据记录。这种索引叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集
辅助索引(次要索引)
第二个与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话说 InnoDB 的所有附注索引都引用主键为 data 域。
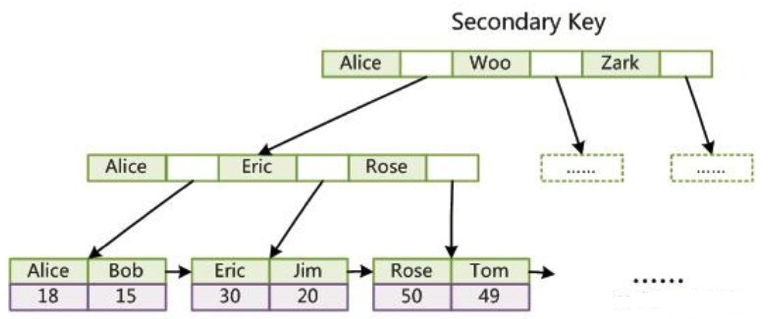
聚集索引这种实现方式使得按主键的搜索十分高效,单附注索引搜索需要检索两边索引:首先检索附注索引获得主键,然后用主键到主索引中检索获得记录(以上图为例:非主键查询,一次是 name 辅助索引,一次是主键索引,最终取出来数据)
不建议使用过长的字段作为主键,以为所有的辅助索引都引用主索引,过长的主索引会令辅助做阴变得过大,同时尽量在 InnoDB 上采用自增字段做表主键。
组合索引的使用
为了更好的提高 MySQL 效率可以建立组合索引(能使用组合索引就不使用)
创建组合索引 ALTER TABLE tableName ADD index_name('col1','col2','col3');,相当于建立了 col1,col1col2,col1col2col3 三个索引
组合索引的使用要遵循最左前缀原则:使用组合索引的时候,where 语句中的条件顺序要按照组合索引从左到右的顺序进行匹配,如果顺序不一致或者出现断层,就无法使用组合索引
创建一张表
CREATE TABLE `people` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
id 为主键,(name,cid)是一个组合索引
select * from people where cid = 1; 通过执行计划分析该条 sql 语句
EXPLAIN select * from people where cid = 1;

主要通过 type 字段进行分析
type:index 这种类型表示 mysql 会对整个索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者摸个组合索引的一部分,mysql 都可能会采用 index 类型进行扫描。这条语句是 cid =1,而 cid 是 (name,cid)组合索引的一部分,可以进行 index 类型的索引扫描方式。这种方式效率相对不高。mysql 会从索引的第一个数据一个个查找到最后一个数据,直到找到符合判断条件的某个索引。
接下来再看一条 sql 语句:select * from people where cid = 1 and name="zhangsan"; 通过执行计划分析该条 sql 语句

type 此时变为了 ref:这种类型表示 mysql 会根据特定的算法快速查找到某个符合调价的索引,而不是对索引中的每个数据进行一一扫描,也就是所谓平时理解的使用索引查询会更快的取出数据。
既然用到索引(name,cid)那么为何 where 后面的顺序则为( cid name) 并不符合最左前缀原则。
这里是因为在执行 sql 语句之前 mysql 会有个查询优化器,也就是说在不影响结果的情况下,mysql 会对 sql 语句进行优化。因此这条 sql 语句就被优化为 select * from people where name=‘zhangsan’ and cid=1; 这里就用到了创建的索引。
此外 type 还有两个比较重要的类型:
const:这种类型表示使用到了唯一索引或者主键,返回记录一定是 1条记录的等值 where 条件。也叫唯一索引扫描
range:索引范围扫描,常见于使用 >、<,is null ,between,in,like 等运算符的查询中。
另外一个重要的属性 extra:
using index:表示为覆盖索引,是指 select 只查询了索引树就能把所要的结果查出来,不需要回表查询(不用对主索引进行二次查询)。比如上个例子中 查询的字段为 id,name,cid 查询过程中 mysql 会先对 辅助索引进行查询找到主键 id,这个时候就是仅通过索引扫描就把 id,name,cid 拿到了。
如果同时出现Using Where ,说明索引被用来执行查找索引键值
如果没有同时出现Using Where ,表明索引用来读取数据而非执行查找动作。
using where:
表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件.
5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。
5.6.x之后支持ICP特性(索引下推),可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
使用索引的注意事项:
1、主键自动建立唯一索引
2、频繁作为查询条件的字段应该创建索引
3、多表管理查询,关联字段应该创建索引
4、查询中的排序字段,应该创建索引
5、查询中统计或分组字段,应该创建索引
6、要查询的列尽量创建为索引,这样就可以使用覆盖索引,减少回表
7、表记录太少不必建立索引
8、经常增删改的表不创建索引
9、频繁更新的字段上面不创建索引
10、不要在 where 条件里使用频率不高的字段上创建索引
3、深度思考的总结
1)Mybais 常用的标签(之前日报也有总结)
基本标签 <insert> <update> <select> <delete>
动态标签 <sql> <iclude> <if> <where> <foreach>
2)什么是反射,反射的坏处是什么,有哪些反射的应用场景?
反射 (Reflection) 是 Java 的特征之一,它允许运行中的 Java 程序获取自身的信息,并且可以操作类或对象的内部属性
优点
反射提高了程序的灵活性和扩展性,降低耦合性,提高自适应能力。它允许程序创和控制任何类的对象,无需提前硬编码目标类
缺点
性能问题,使用反射基本上是一种解释操作,字段和方法接入时要远慢于直接代码。因此反射机制主要应用在对灵活性和扩展性要求很高的系统框架上,普通程序不建议使用
反射的应用场景
JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;
Spring框架也用到很多反射机制,最经典的就是xml的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程
3) 什么是SVN,小乌龟是什么,SVN的文件版本号是怎么来的,哪些文件应该上传到SVN,哪些不该上传?Git和SVN的区别又是什么?
svn git 都是版本控制工具,最主要的区别Git是分布式的,而Svn不是分布的。一般使用 git
4)为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
使用Interface是为了实现接口和实现类分离,对接口进行封装,这样一个接口可以对应多个实现类。使用起来就很方便
同一个方法也可能不止一个类调用,这个时候用接口实现分离的方法可以减少代码重复率,耦合度更低。
使用接口使代码看起来层次分明,更易于理解和更改。
5)Map,List,Array,Set之间的关系是什么,分别适用于哪些场景,集合大家族还有哪些常见的类?
java集合类中主要派生出两个接口 Collection 和 Map
List、Set 是 Collection 的派生接口
HashSet、TreeSet、LinkedHashSet 是 set 的实现类
LinkedList ArrayList、Vector 都是 List 的实现类
HashMap HashTable LinkedHashMap 是 Map 的子类
6)Spring的IOC有几种方式?它们之间的差别是什么,应该选择Annonation还是应该选择XML?
Spring IoC 方式有 xml 配置及注解方式,一般选择 xml 与 注解 混合使用,不过现在 SpringBoot 盛行,则使用纯注解的方式。怎么选择还得看公司项目及具体的使用场景。
8)Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
IoC 就是 Spring 一个核心的组件,控制反转。
10)为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
以业务逻辑功能为单位,在最上层加Try-Catch机制。为什么要这样做呢?这主要是增加程序的健壮性,防止因抛出异常过多,导致程序崩溃。
底层代码,在可能出错的地方加Try-Catch机制,用Catch侦测具体的异常,然后就具体的异常,采取相应的解决方案。
底层代码,在需异常追踪时加Try-Catch机制,在Catch块中抛出自定义异常,调试时可迅速定位到错误代码段。
Try-Catch机制会将异常屏蔽掉,必须根据具体的应用场景,具体分析。
可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
可以用idea 配置线上调试,不过真实项目上线之后就要用日志分析的方法去排查问题
https://www.jianshu.com/p/fb4a533856fe(师兄之前的讲解)
11)日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
日志一般记录业务逻辑的重要点。需要方法的入参,返回值
还要记录方法出错的具体原因,及堆栈信息等。
13)可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
idea 是可以连接到远程的 tomcat 进行调试的,但是真实项目中不会用到,一般排查错误日志可以找到出问题的原因及解决方案。
14)什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?)(参考之前师兄的日志)
贫血模型是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务逻辑层。
有人将我们这里说的贫血模型进一步划分成失血模型(领域对象完全没有业务逻辑)和贫血模型(领域对象有少量的业务逻辑),我们这里就不对此加以区分了。充血模型将大多数业务逻辑和持久化放在领域对象中,业务逻辑(业务门面)只是完成对业务逻辑的封装、事务和权限等的处理。贫血模型和充血模型的分层架构。
更加细粒度的有失血模型,贫血模型,充血模型,胀血模型。贫血模型就是domain ojbect包含了不依赖于持久化的领域逻辑,而那些依赖持久化的领域逻辑被分离到Service层。
失血模型简单来说,就是domain object只有属性的getter/setter方法的纯数据类,所有的业务逻辑完全由business object来完成(又称Transaction Script),这种模型下的domain object被Martin Fowler称之为“贫血的domain object”。
充血模型和第二种模型差不多,所不同的就是如何划分业务逻辑,即认为,绝大多业务逻辑都应该被放在domain object里面(包括持久化逻辑),而Service层应该是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
15) 为什么不可以用Select * from table?
当使用 select * from table 查询数据的弊端:
使用SELECT * 语句将不会使用到覆盖索引,不利于查询的性能优化。(索引覆盖:索引覆盖是一种速度极快,效率极高,业界推荐的一种查询方式.就是select的数据列只用从索引中就能够获得,不必从数据表中读取,也就是查询列要被所使用的索引覆盖)
MySQL 会解析更多的对象,字段,权限,属性相关,从而导致优化和效率问题; 还会对表中所有列进行权限检查,这部分是也额外的开销。
因此我们为了规范和效率,还是需要什么字段就查什么字段用 select 字段名进行查询操作吧
16) clean,install,package,deploy分别代表什么含义?
mvn clean package依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)等7个阶段。
mvn clean install依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)、install等8个阶段。
mvn clean deploy依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)、install、deploy等9个阶段。
由上面的分析可知主要区别如下
package命令完成了项目编译、单元测试、打包功能,但没有把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库
install命令完成了项目编译、单元测试、打包功能,同时把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库,但没有布署到远程maven私服仓库
deploy命令完成了项目编译、单元测试、打包功能,同时把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库
17)怎么让 Maven 跳过 Junit?
maven Test 常用命令及如何跳过单元测试
mvn test -Dtest=com.gary.mavenmybatis.*
在 mvn package 进行编译、打包时,Maven 会执行 ***src/test/java*** 中的 JUnit 测 试用例,有时为了跳过测试,
会使用参数 -DskipTests
Dmaven.test.skip=true(还可以在 pom.xml 文件中进行配置)
18)为什么要用Log4j来替代System.out.println?
log4j的配置文件中有输出到文件的相关配置,也是我们为什么使用log的关键点,查找日志信息的时候就可以到相应的日志文件中去查看,并且不会因为程序关闭等等因素丢失掉之前的日志信息,如果是sout的话,程序关闭,信息就丢失了。
19)为什么DB的设计中要使用Long来替换掉Date类型?
存储时间的字段用 Long 代替 Datetime 有以下的好处:
存储方便,占用字节数更少
由于时间格式比较多,不同的地区也有时差,为了规范使用时间戳进行存储
转化方便,取出来的时间戳可以转化为任意的格式
20)自增ID有什么坏处?什么样的场景下不使用自增ID?
缺点就是,当合并多张表时候,会出现 ID重复的情况,而且不具有连续性,比如表中存有3行数据,ID字段为1,2,3 那么当删除字段2时就变为1,3,不具有连续性。网上也推荐使用 UUID 来代替 ID 确保数据标识的唯一性。分布式中更需要生成唯一主键 id,使用 Redis 自增,或者 Twitter 的雪花算法,后期涉及到再详细学习
21)什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
22)唯一索引和普通索引
Mysql 提供了多种索引类型:普通索引,唯一索引,主键,全文索引等
普通索引的目的就是为了加快检索数据的效率,可以在经常查询的字段上面加索引
唯一索引是确定数据表中该列只能存在唯一的值,创建索引的时候也应该用 UNIQUE 来约束。当数据插入时候,Mysql 会自动检查数据表中该列是否存在这个值,如果存在则不能插入成功。
23)如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
当对学员 qq 号建立唯一索引以后,插入数据时侯应当先判断这个 qq 号是否存在,否则的话会抛异常
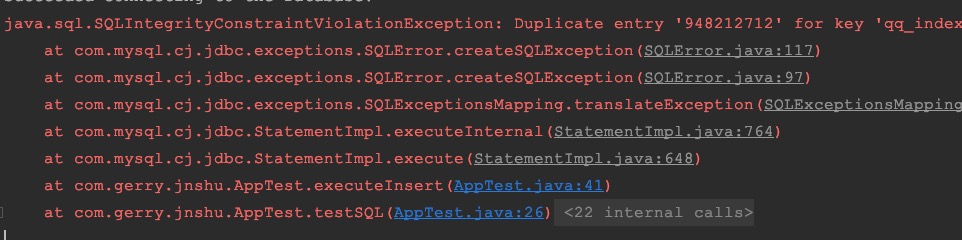
24)CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
对于 create_time创建的时候赋值,updte_time 在创建和更新的时候赋值
create_time update_time 属于对数据的创建和修改操作记录,不需要对外开放给外部接口
25)修真类型应该是直接存储Varchar,还是应该存储int?
对于修真类型这个字段最好还是通过 int 来存储,int 字段比 varchar 字段存储的空间少。但是在查询完结果以后还需要根据 int 值来转化为所需要的字符串(根据业务的具体情况来定)
26)varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
varchar 存储变长数据,char 是存储固定长度。varchar 存储效率没有 char 高
varchar(20) 存储20个字符。无论是存储数字,字母还是 utf8汉字(每个汉字3字节),都可以存放 20个。
对于具体长度定多少根据具体情况,比如用户名,一般不会出现 255/8=25个汉字。所以考虑到少数民族 varchar(20)就足够用。
对于数字类型的字段尽量使用数字类型,因为使用字符串类型会降低查询和连接的性能
Text 和 LongText 可以存储长度可变的类型
Text的最大长度是可以存储 65535 (2^16 – 1) 个字符
LongText的最大长度是可以存储4294967295 (2^32 – 1) 个字符。
27)怎么进行分页数据的查询,如何判断是否有下一页
Mysql 分页查询通过 limit 关键字实现,接收一个或两个数字参数。第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目
例如查询 6-15 行的数据
SELECT * FROM table LIMIT 5,10 (从第5行开始,到 15行结束)
如果查询从某个偏移量开始到所有结束的记录行,指定第二个参数为 -1
SELECT * FROM table LIMIT 95,-1 (查询 96-last 行的记录)
如果指定一个参数,标识返回最大的记录行数目
SELECT * FROM table LIMIT 5 等价于 SELECT * FROM table LIMIT 0,5
判断是否有下一页(伪代码)
int total = SELECT COUNT(*) FROM student;
int pageSize = 5;
int pageNow = 0;
int pageIndex = total % pageSize;
int pageCount = total / pageSize;
int totalPage = pageIndex==0 ? pageCount : pageCount + 1;
pageNow++;
if(pageNow<totalPage){
//有下一页
}
else{
//没有下一页
pageNow = totalPage;
}
明天计划的事情:
任务一需要完善的部分已经完成,深度总结也加上了,接下来准备开始任务二
遇到的问题:
暂无
收获:
掌握了 MySQL、MyBatis、Spring 基本知识,虽然还有很多要学,但是以任务为前提,以后慢慢在学习中补充




评论