发表于: 2019-10-31 22:54:43
1 987
今日完成的事
优化前端代码
明日计划的事
复习前端基础
收获
看了点seo优化的东西
搜索引擎做的工作是相当复杂的,我们这里简单说一下大致的过程。后续针对SEO如何优化,也会根据这几个点展开描述。
页面抓取: 蜘蛛向服务器请求页面,获取页面内容
分析入库:对获取到的内容进行分析,对优质页面进行收录
检索排序:当用户检索关键词时,从收录的页面中按照一定的规则进行排序,并返回给用户结果
主要以百度蜘蛛举例。
百度蜘蛛,是百度搜索引擎的一个自动程序。它的作用是访问收集整理互联网上的网页、图片、视频等内容,然后分门别类建立索引数据库,
页面抓取
如何才能吸引蜘蛛光顾我们的网站,如何才能让蜘蛛经常光顾我们的网站。这里提出以下几个优化点:
提交页面。提交页面又分为几种不同的方式
sitemap提交。sitemap,顾名思义,就是网站地图,当蜘蛛来到我们的网站时,告诉它我们有多少页面,不同页面是按什么分类的,每个页面的地址是什么。顺着我们的指引,蜘蛛会很轻松的爬遍所有内容。另外,如果你的页面分类比较多,而且数量大,建议添加sitemap索引文件。如果站点经常更新添加新页面,建议及时更新sitemap文件;
主动提交。就是把你的页面直接丢给百度的接口,亲口告诉百度你有哪些页面,这是效率最高也是收录最快的方式了。但是需要注意,百度对每天提交的数量是有限制的,而且反复提交重复的页面,会被降低每日限额,所以已被收录的页面不建议反复提交。收录有个时间过程,请先耐心等待;
实时提交。在页面中安装百度给的提交代码,当这个页面被用户打开我,便自动把这个页面提交给百度。这里不需要考虑重复提交的问题。
以上几种提交方式可以同时使用,互不冲突。
保证我们的页面是蜘蛛可读的。
早在ajax还没流行的的时候,其实SEO对于前端的要求并没有很多,或者说,那个时候还没有前端这个职业。页面全部在服务器端由渲染好,不管是用户还是蜘蛛过来,都能很友好的返回html。ajax似乎原本是为了避免有数据交互导致必须重刷页面设计的,但是被大规模滥用,一些开发者不管三七二十一,所有数据都用ajax请求,使得蜘蛛不能顺利的获取页面内容。庆幸的是这反倒促进了前端的飞速发展。
到了后来,各种SPA单页应用框架的出现,使得前端开发者不再需要关心页面的DOM结构,只需专注业务逻辑,数据全部由Javascript发ajax请求获取数据,然后在客户端进行渲染。这也就导致了老生常谈的SEO问题。百度在国内搜索引擎的占有率最高,但是很不幸,它并不支持ajax数据的爬取。于是,开发者开始想别的解决方案,比如检测到是爬虫过来,单独把它转发到一个专门的路由去渲染,比如基于Node.js的Jade引擎(现在改名叫Pug了),就能很好地解决这个问题。React和Vue,包括一个比较小众的框架Marko也出了对应的服务端渲染解决方案。
看到一个面试问题 如何理解Virtual DOM
vdom是虚拟DOM(Virtual DOM)的简称,指的是用JS模拟的DOM结构,将DOM变化的对比放在JS层来做。换而言之,vdom就是JS对象。
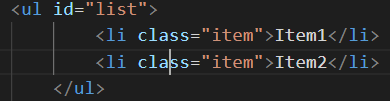
映射成虚拟DOM就是这样:
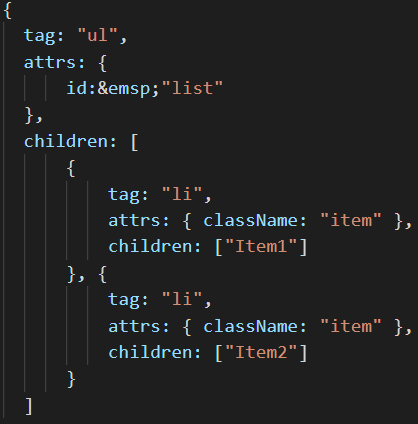
为什么要用vdom?
现有一个场景,实现以下需求
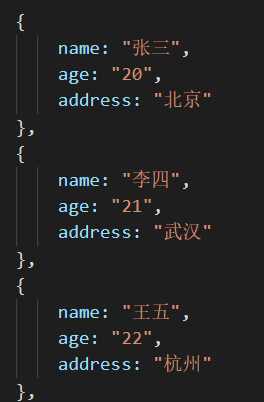
将该数据展示成一个表格,并且随便修改一个信息,表格也跟着修改。

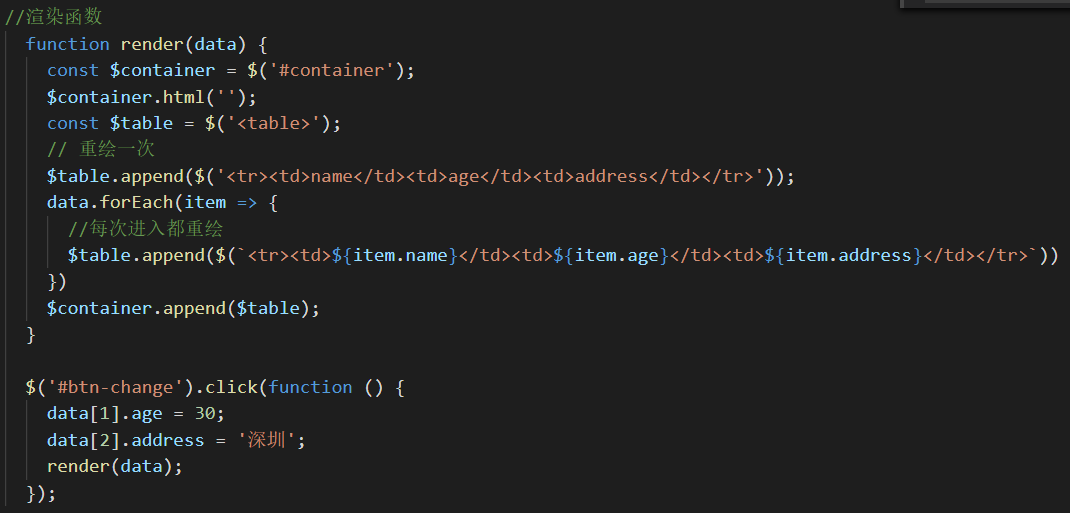
这样点击按钮,会有相应的视图变化,但是你审查以下元素,每次改动之后,table标签都得重新创建,也就是说table下面的每一个栏目,不管是数据是否和原来一样,都得重新渲染,这并不是理想中的情况,当其中的一栏数据和原来一样,我们希望这一栏不要重新渲染,因为DOM重绘相当消耗浏览器性能。
因此我们采用JS对象模拟的方法,将DOM的比对操作放在JS层,减少浏览器不必要的重绘,提高效率。
当然有人说虚拟DOM并不比真实的DOM快,其实也是有道理的。当上述table中的每一条数据都改变时,显然真实的DOM操作更快,因为虚拟DOM还存在js中diff算法的比对过程。所以,上述性能优势仅仅适用于大量数据的渲染并且改变的数据只是一小部分的情况。
虚拟DOM更加优秀的地方在于:
1、它打开了函数式的UI编程的大门,即UI = f(data)这种构建UI的方式。
2、可以将JS对象渲染到浏览器DOM以外的环境中,也就是支持了跨平台开发,比如ReactNative。




评论