发表于: 2019-10-31 19:58:34
3 1134
啥也不说就是干!!!
今天完成的事情:
1、之前买了阿里云服务器,安装数据库
首先检测系统是否自带安装的 mysql
# yum list installed | grep mysql
删除系统自带的 mysql 及其依赖
# yum -y remove mysql-libs.x86_64
给 centos 添加 rpm 源,并且选择较新的源
# wget dev.mysql.com/get/mysql-community-release-el6-5.noarch.rpm
# yum localinstall mysql-community-release-el6-5.noarch.rpm
# yum repolist all | grep mysql
# yum repolist all | grep mysql
# yum-config-manager --disable mysql55-community
# yum-config-manager --disable mysql56-community
# yum-config-manager --enable mysql57-community-dmr
# yum repolist enabled | grep mysql
安装 mysql 服务器
# yum install mysql-community-server
查看 mysql 是否启动,并设置开启自启动
# chkconfig --list | grep mysqld
# chkconfig mysqld on
mysql 安全设置
# mysql_secure_installation
启动 MySQL(centos6.8)
service mysqld start
修改 MySQL 初始密码,通过 rpm 包安装,在 /var/log/mysqld.log中赋值了初始密码
# grep 'temporary password' /var/log/mysqld.log
登录 mysql,开启远程授权
# grant 权限 on 数据库对象 to 用户
例如:GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%' INDENTIFIED BY 'mypassword' WITH GRANT OPTION;
再执行 fulsh privileges;
ALL PRIVILEGES :表示授予所有的权限,此处可以指定具体的授权权限。
*.* :表示所有库中的所有表
'myuser'@'%' : myuser是数据库的用户名,%表示是任意ip地址,可以指定具体ip地址。
IDENTIFIED BY 'mypassword' :mypassword是数据库的密码。
使授权立即生效 “flush privileges”
由于阿里云开启了安全规则,所以要配置端口号,将 mysql 3306端口放开(如果是Linux 服务器需要配置防火墙规则,定义开放的端口,或者关闭防火墙。但不建议直接关闭防火墙)
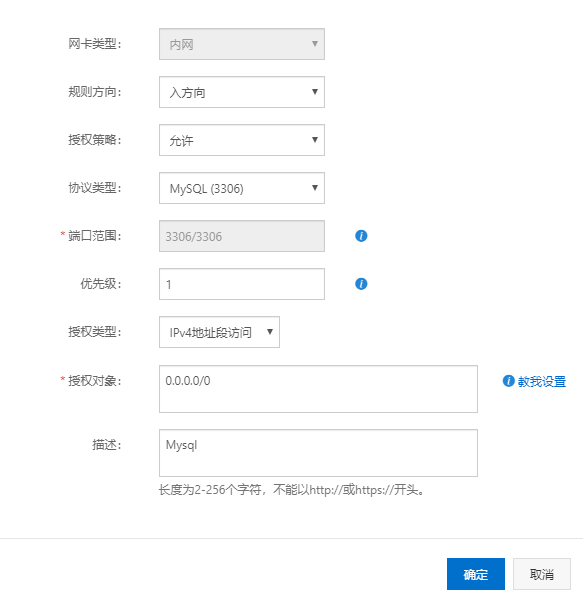
2、Navicat 连接远程数据库
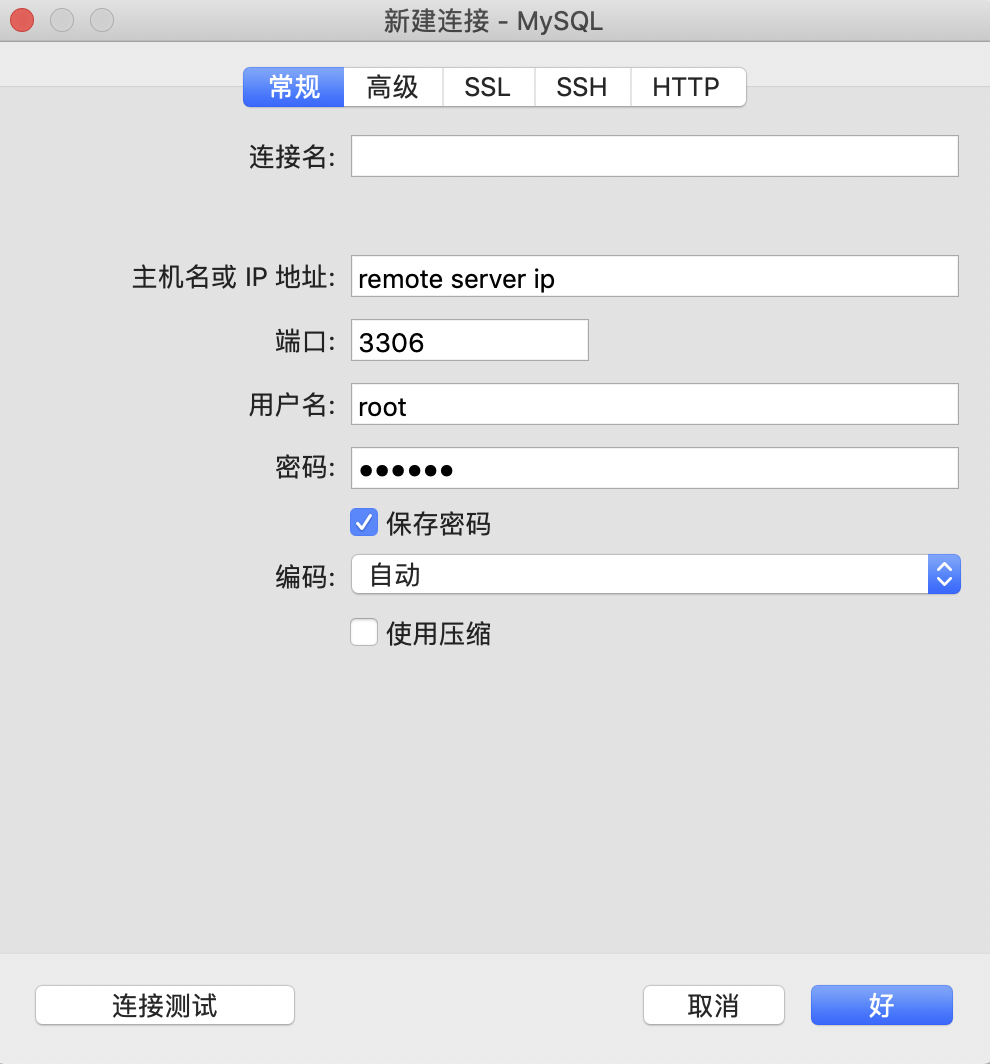
填写主机地址、数据库用户名、密码,点测试连接,可以看到连接成功,然后将本地的数据表结构导出再导入到远程的连接中:
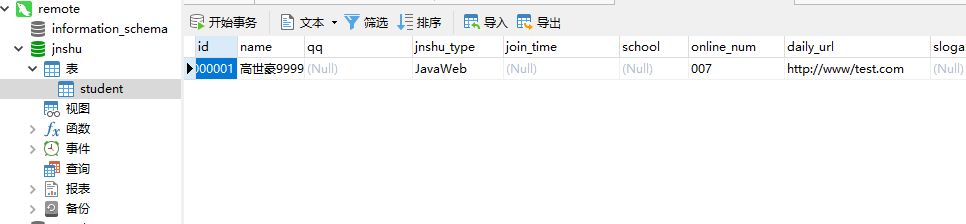
看到数据表跟数据已经导入到远程服务器的数据库中
3、Spring 连接远程数据库
修改程序中的 db.properties 配置文件:
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="${jdbc.username}"></property>
<property name="password" value="${jdbc.password}"></property>
<property name="jdbcUrl" value="${jdbc.urlRemote}"></property>
<property name="driverClass" value="${jdbc.driver}"></property>
</bean>
将 jdbcUrl 更换为远程库的地址
jdbc.urlRemote=jdbc:mysql://23.197.76.255:3306/jnshu?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT
执行测试类,插入数据
@Test
public void insertStudent() throws InterruptedException {
//插入 100 万条数据
//insert100w();
Student student = new Student();
student.setName("高世豪");
student.setJnshuType("JavaWeb");
student.setOnlineNum("007");
student.setDailyUrl("http://www/test.com");
student.setCounsellor("令狐冲");
try {
studentService.insertInfo(student);
} catch (Exception e) {
logger.error(e.getMessage());
}
}
执行成功,可以看到远程数据库的新插入数据:

4、插入100w 条数据
之前师兄提到过使用多线程进行插入,这里使用 ExcutorService 线程池实现多线程。
声明线程池,定义 1000 个线程。
ExecutorService executorService = Executors.newFixedThreadPool(1000);
定义 Runnable,要执行的任务。并交给 executor 对象执行。
private void insert100w() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(1000);
final CountDownLatch latch = new CountDownLatch(1);
executorService.execute(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Student student = new Student();
student.setName("高世豪"+i);
student.setJnshuType("JavaWeb");
student.setOnlineNum("007");
student.setDailyUrl("http://www/test.com");
student.setCounsellor("令狐冲");
try {
studentService.insertInfo(student);
} catch (Exception e) {
logger.error(e.getMessage());
} finally {
latch.countDown();
}
}
long end = System.currentTimeMillis();
logger.info("插入 100 万条数据耗时:" + (end - start));
}
});
latch.await();
}
可以看到执行的结果:

耗时大约 0.9 个小时。(1000个线程感觉还有点慢,电脑可能配置太低?)
5、从 100w 条数据中,查询数据
增加根据 name 查询的方法:
<select id="queryStudentByName" parameterType="java.lang.String" resultType="com.gerry.jnshu.bean.Student">
SELECT id,name,jnshu_type,online_num,counsellor FROM student WHERE name = #{id}
</select>
定义接口及实现类:
List<Student> queryStudentByName(String name);
@Override
public List<Student> queryByName(String name) {
return studentMapper.queryStudentByName(name);
}
编写单元测试方法:
@Test
public void queryStudentByName() {
long start = System.currentTimeMillis();
List<Student> students = studentService.queryByName("高世豪999852");
if (students.size() > 0) {
logger.info("查询结果----->" + students.get(0));
} else {
logger.info("查询结果为空");
}
long end = System.currentTimeMillis();
logger.info("无索引查询(100万)耗时:" + (end - start));
}
没建立索引的情况:大约 3 秒

接下来在 name 字段上加上索引:
create unique index st_name_index on student(name(10));

可以看到索引创建成功,其中一个为 id 的主键索引。再次执行单元测试方法:

建立索引的情况:2.3秒。数据量大的时候索引应该更加明显。3000w跟2亿数据实在太大,怕电脑扛不住,暂时没法测试了。
6、其他部分(算是对任务一的扫尾)
测试一下不关闭连接池的时候,在Main函数里写1000个循环调用会出现什么情况。
不断循环读取数据,而不关闭连接,会造成数据库连接过多而报错:Too many connections

为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
1)以业务逻辑功能为单位,在最上层加Try-Catch机制。为什么要这样做呢?这主要是增加程序的健壮性,防止因抛出异常过多,导致程序崩溃。
2)底层代码,在可能出错的地方加Try-Catch机制,用Catch侦测具体的异常,然后就具体的异常,采取相应的解决方案。
3)底层代码,在需异常追踪时加Try-Catch机制,在Catch块中抛出自定义异常,调试时可迅速定位到错误代码段。
Try-Catch机制会将异常屏蔽掉,必须根据具体的应用场景,具体分析。
可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
可以用idea 配置线上调试,不过真实项目上线之后就要用日志分析的方法去排查问题
什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?)(参考之前师兄的日志)
贫血模型是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务逻辑层。
有人将我们这里说的贫血模型进一步划分成失血模型(领域对象完全没有业务逻辑)和贫血模型(领域对象有少量的业务逻辑),我们这里就不对此加以区分了。充血模型将大多数业务逻辑和持久化放在领域对象中,业务逻辑(业务门面)只是完成对业务逻辑的封装、事务和权限等的处理。贫血模型和充血模型的分层架构。
更加细粒度的有失血模型,贫血模型,充血模型,胀血模型。贫血模型就是domain ojbect包含了不依赖于持久化的领域逻辑,而那些依赖持久化的领域逻辑被分离到Service层。
失血模型简单来说,就是domain object只有属性的getter/setter方法的纯数据类,所有的业务逻辑完全由business object来完成(又称Transaction Script),这种模型下的domain object被Martin Fowler称之为“贫血的domain object”。
充血模型和第二种模型差不多,所不同的就是如何划分业务逻辑,即认为,绝大多业务逻辑都应该被放在domain object里面(包括持久化逻辑),而Service层应该是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
明天计划的事情:
任务一暂时结束,师兄看一下可否开始任务二,代码已重新上传至 Github 了
遇到的问题:
1、db.properties 配置文件 ${username} 变量值的问题

这个是我在公司 windows10 系统上遇到的问题
为何我在 db.properties 里面指定了用户为 root 。但却读出来的 admin。在网上搜索了一下,是因为 Spring 在使用 <context:place-holder> 指定配置文件时候,会先去系统的环境变量中读取。而我的Windows10 系统中正好存在了 username 这个变量
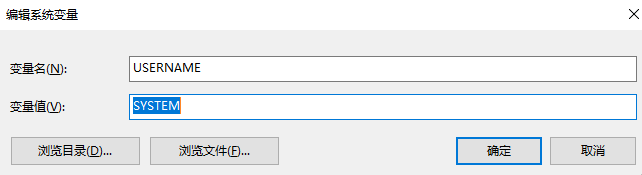
而 SYSTEM 指向了我的计算机用户名 admin。这个问题只有在 windows系统中可能会出现。而我自己的mac 系统没有出现该问题。解决方法就是,将 username 替换成 jdbc.username,然后避免该被覆盖。(以后的配置文件中变量名最好制定前缀,类似于 jdbc.XXX)

参考该文章:https://blog.csdn.net/u013536829/article/details/80027391
2、加入休眠等待 CountDownLatch
在插入 100w 数据的时候出现了一下异常情况,写了循环但是没有执行,单元测试类也不报错。但是控制台有句 log 日志:
org.springframework.context.support.GenericApplicationContext doClose
信息: Closing org.springframework.context.support.GenericApplicationContext@2ef5e5e3: startup date [Sun Jan 28 14:56:19 CST 2018]; root of context hierarchy
搜索了该错误结合情况分析是 单元测试线程已经结束,关闭了 Spring Context。但是其中的线程因为耗时久,还没结束被强制关闭掉了。
因此需要让主线程等子线程任务结束后再关闭。这种解决方式有很多,我采用的是 CountDownLatch ,具体的使用参考链接:https://www.jianshu.com/p/128476015902
改造代码:
private void insert100w() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(1000);
//声明等待锁
final CountDownLatch latch = new CountDownLatch(1);
executorService.execute(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
//for循环省略...
//子任务结束,解除锁等待
latch.countDown();
long end = System.currentTimeMillis();
logger.info("插入 100 万条数据耗时:" + (end - start));
}
});
//开始等待,主线程挂起
latch.await();
}
3、index 创建的问题:
由于 name 字段的索引是有了数据之后才出现的,所以在执行
create unique index st_name_index on student(name(5));
这条 sql 语句报错:

但是我数据库中 name 为 ‘高世豪10’的只有一个,为什么会报错,思考了一下,应该是 name(5) 这个 length 引起的。
前五位重复的应该有不止一条数据,于是模糊查询了一下
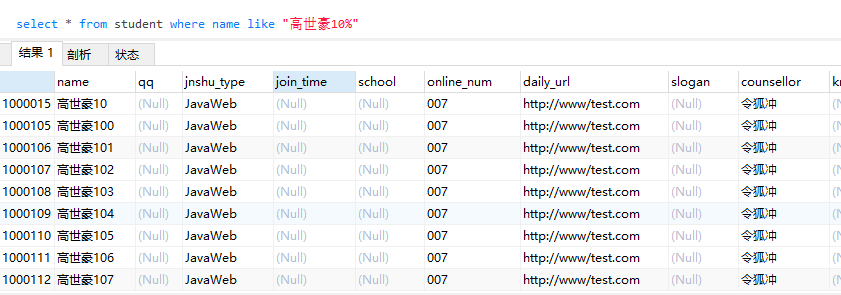
发现确实有很多条,所以在创建索引的时候 name 的 length 应该指定为字段的长度
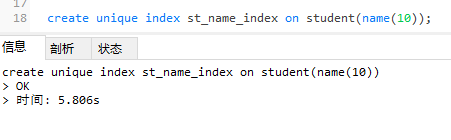
可以看到 name 字段索引创建成功。
收获:
感觉今天收获挺多的,关于 mysql 索引,Mybatis 数据库操作,多线程。包括遇到的问题以及最终的解决方案学到了很多东西,只有动手去做了才会遇到问题,遇到问题才能学到东西。




评论