发表于: 2019-10-13 18:07:23
7 1089
今天是正式加入修真院的第一天,啥也不说就是干!!!
1、Mysql 环境搭建及基本SQL语句操作
首先安装 Mysql 数据库,及可视化工具 Navicat
创建数据库 jnshu
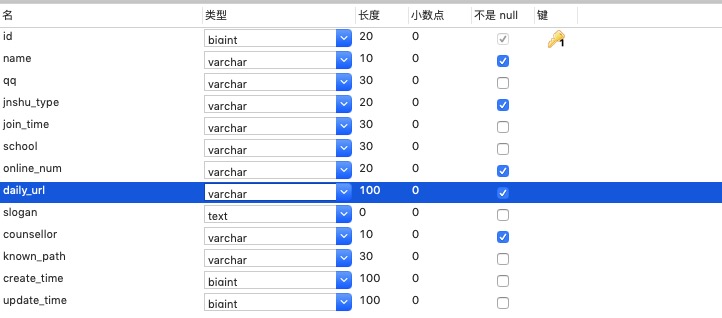
根据报名帖设计数据表结构如下:表名:student
根据报名帖内容插入数据:
INSERT INTO student( name, qq, jnshu_type, join_time, school, online_num, daily_url, slogan, counsellor, known_path, create_time, update_time) VALUES( '高世豪', '948212712', 'Java后端', '2019年9月27日', '聊城大学', 'java-6161',
'http://www.jnshu.com/daily/106193?total=7&page=1&uid=38926&sort=0&orderBy=3',
'三到四个月的时间,彻底的改变自己!', '辛家印', '知乎',
UNIX_TIMESTAMP(NOW())*1000,
UNIX_TIMESTAMP(NOW())*1000);
插入数据成功

根据姓名查询该条记录
SELECT * FROM student WHERE name='高世豪';

将该条记录的报名誓言改为“老大最帅”:UPDATE student SET slogan='老大最帅' WHERE name='高世豪';

导出sql文件:
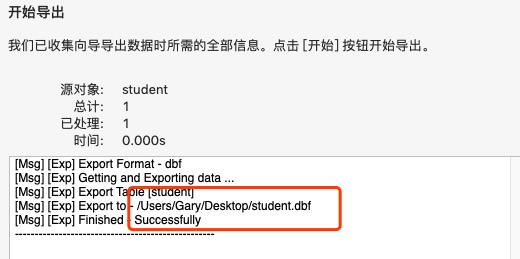
删除该条数据:DELETE FROM student WHERE name='高世豪';

用导出的 student.dbf 文件对数据进行恢复
导入成功
2、Mysql 索引、主外键
索引的创建对于 Mysql 的高效运行还是很重要的,可以大大提高检索速度。其实索引也是一张表,该表保存了主键与索引字段,并指向实体表中的记录
索引包含了单列索引和组合索引。单列索引只包含单个列,一个表中可以有多个单列索引(并非组合索引);组合索引则包含了多个列
创建索引的时候,需要确保该索引是应用在 sql 查询语句的条件中(一般作为 where 字句的条件)
虽然索引能提高检索速度,但是也会降低表的更新速度,如:insert、update 和 delete 操作。因为每次更新数据,mysql 不仅要保存数据,还要对索引文件重新维护(索引文件也是保存在磁盘中,占用磁盘空间)
创建索引有两种方法:
普通索引(唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须是唯一的)
创建索引语法:
CREATE (UNIQUE) INDEX indexName ON tableName(columnName(length))
ALTER TABLE tableName ADD (UNIQUE) INDEX indexName(columnName(length))
如果是 char、varchar 类型,length 可以小于字段实际长度,如果是 blog、text 类型,必须执行 length。
为上面的表的 name 字段建立索引。
CREATE INDEX name_index ON student(name(10))
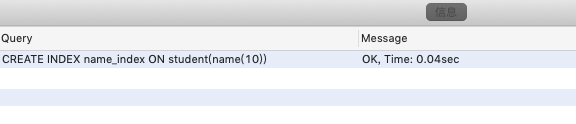
索引已经创建成功,接下来查询一下创建的索引。语法:SHOW INDEX FROM tableName

可以看到两条索引,name_index 为刚创建的,PRIMARY 这个则是主键索引。
删除索引也有两种方法:
DROP INDEX indexName ON tableName
ALTER TABLE tableName DROP INDEX indexName
主键是一条记录的唯一标识,不能重复,不能为空。一个表中也只能有一个主键,保证数据的完整性
创建主键可以在设计表结构的时候声明,也可以通过修改表结构进行添加
CREATE TABLE IF NOT EXISTS test(
id INT AUTO_INCREMENT,
name VARCHAR(10) NOT NULL,
age INT(2) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
或者
ALTER TABLE test MODIFY id INT NOT NULL (确保要添加的主键默认不为空)
ALTER TABLE test ADD PRIMARY KEY (id) (将主键索引添加到对应的列上)
删除主键:ALTER TABLE test DROP PRIMARY KEY (id) (自增的主键不能删除)
ALTER TABLE test DROP PRIMARY KEY
外键约束一般是指对另外一张表主键的关联,用于链表查询。外键可以有多个,可以为空。
外键的添加与删除
ALTER TABLE test ADD CONSTRAINT fk_class_id FOREIEN KEY(class_id) REFERENCES classes(id)
ALTER TABLE test DROP FOREIGN KEY fk_class_id
3、关于深度思考问题与总结(有些参考师兄的日志)
1)存储时间的字段用 Long 代替 Datetime 有以下的好处:
存储方便,占用字节数更少
由于时间格式比较多,不同的地区也有时差,为了规范使用时间戳进行存储
转化方便,取出来的时间戳可以转化为任意的格式
2)
当使用 select * from table 查询数据的弊端:
使用SELECT * 语句将不会使用到覆盖索引,不利于查询的性能优化。(索引覆盖:索引覆盖是一种速度极快,效率极高,业界推荐的一种查询方式.就是select的数据列只用从索引中就能够获得,不必从数据表中读取,也就是查询列要被所使用的索引覆盖)
MySQL 会解析更多的对象,字段,权限,属性相关,从而导致优化和效率问题; 还会对表中所有列进行权限检查,这部分是也额外的开销。
因此我们为了规范和效率,还是需要什么字段就查什么字段用 select 字段名进行查询操作吧
3)关于自增 id
缺点就是,当合并多张表时候,会出现 ID重复的情况,而且不具有连续性,比如表中存有3行数据,ID字段为1,2,3 那么当删除字段2时就变为1,3,不具有连续性。网上也推荐使用 UUID 来代替 ID 确保数据标识的唯一性。分布式中更需要生成唯一主键 id,使用 Redis 自增,或者 Twitter 的雪花算法,后期涉及到再详细学习
4)唯一索引和普通索引
Mysql 提供了多种索引类型:普通索引,唯一索引,主键,全文索引等
普通索引的目的就是为了加快检索数据的效率,可以在经常查询的字段上面加索引
唯一索引是确定数据表中该列只能存在唯一的值,创建索引的时候也应该用 UNIQUE 来约束。当数据插入时候,Mysql 会自动检查数据表中该列是否存在这个值,如果存在则不能插入成功。
5)当对学员 qq 号建立唯一索引以后,插入数据时侯应当先判断这个 qq 号是否存在,否则的话会抛异常
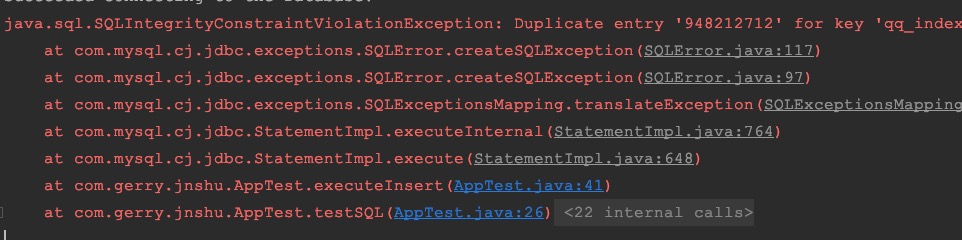
6) 对于 create_time创建的时候赋值,updte_time 在创建和更新的时候赋值
create_time update_time 属于对数据的创建和修改操作记录,不需要对外开放给外部接口
7)对于修真类型这个字段最好还是通过 int 来存储,int 字段比 varchar 字段存储的空间少。但是在查询完结果以后还需要根据 int 值来转化为所需要的字符串(根据业务的具体情况来定)
8)varchar 类型的长度
varchar 存储变长数据,char 是存储固定长度。varchar 存储效率没有 char 高
varchar(20) 存储20个字符。无论是存储数字,字母还是 utf8汉字(每个汉字3字节),都可以存放 20个。
对于具体长度定多少根据具体情况,比如用户名,一般不会出现 255/8=25个汉字。所以考虑到少数民族 varchar(20)就足够用。
对于数字类型的字段尽量使用数字类型,因为使用字符串类型会降低查询和连接的性能
Text 和 LongText 可以存储长度可变的类型
Text的最大长度是可以存储 65535 (2^16 – 1) 个字符
LongText的最大长度是可以存储4294967295 (2^32 – 1) 个字符。
9)怎么进行分页数据的查询,如何判断是否有下一页
Mysql 分页查询通过 limit 关键字实现,接收一个或两个数字参数。第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目
例如查询 6-15 行的数据
SELECT * FROM table LIMIT 5,10 (从第5行开始,到 15行结束)
如果查询从某个偏移量开始到所有结束的记录行,指定第二个参数为 -1
SELECT * FROM table LIMIT 95,-1 (查询 96-last 行的记录)
如果指定一个参数,标识返回最大的记录行数目
SELECT * FROM table LIMIT 5 等价于 SELECT * FROM table LIMIT 0,5
判断是否有下一页(伪代码)
int total = SELECT COUNT(*) FROM student;
int pageSize = 5;
int pageNow = 0;
int pageIndex = total % pageSize;
int pageCount = total / pageSize;
int totalPage = pageIndex==0 ? pageCount : pageCount + 1;
pageNow++;
if(pageNow<totalPage){
//有下一页
}
else{
//没有下一页
pageNow = totalPage;
}
4、疑问与待解答的问题:
1)导出sql文件,有以下选项

一般在实际项目中采用什么类型的文件格式
2)在实际业务场景中多大的数据量能体现出索引的影响
做测试的时候 在是否创建 name 列索引的情况下,插入数据执行效率相差不大,可能是数据量太小。
还请师兄帮忙答疑解惑
今天主要学习了 Mysql 相关的知识点,往后还要掌握 Mysql 更高级的用法,目前按照任务走,接下来打算学习 Maven。




评论